 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Impact of Geometric Foundation Models on Vision-Language-Action Models
May 23, 2026Recent work explores new opportunities at the intersection of vision-language-action models (VLAs) and geometric foundation models (GFMs) for 3D reconstruction, such as VGGT. While the resulting geometric VLAs often show improved performance, it remains unclear (i) if modern VLAs already have sufficient geometric understanding to start with, (ii) what is the best architecture to inject geometric understanding into a VLA, and (iii) what is the effect of other design choices that affect geometric VLAs. In this paper we provide a rigorous experimental analysis to shed light on these questions, for a specific choice of VLA (GR00T-N1.5) and GFM (VGGT). Our first contribution is to formalize prior work's intuition that current VLAs lack geometric understanding, by providing a rigorous analysis based on linear probing. The analysis quantifies, for the first time, the "geometric gap" between VLAs and GFMs. Our second contribution is to identify and compare different strategies to bridge GFMs with VLAs. We implement three different architectures, which differ in the way they inject geometry in the VLA, while keeping low-level implementation details as similar as possible, to ensure a fair comparison. Finally, we analyze the impact of non-architectural choices (e.g., training data, number of cameras, reconstruction quality) on the performance of the geometric VLAs.
Revisiting Model Stitching In the Foundation Model Era
Mar 16, 2026Model stitching, connecting early layers of one model (source) to later layers of another (target) via a light stitch layer, has served as a probe of representational compatibility. Prior work finds that models trained on the same dataset remain stitchable (negligible accuracy drop) despite different initializations or objectives. We revisit stitching for Vision Foundation Models (VFMs) that vary in objectives, data, and modality mix (e.g., CLIP, DINOv2, SigLIP 2) and ask: Are heterogeneous VFMs stitchable? We introduce a systematic protocol spanning the stitch points, stitch layer families, training losses, and downstream tasks. Three findings emerge. (1) Stitch layer training matters: conventional approaches that match the intermediate features at the stitch point or optimize the task loss end-to-end struggle to retain accuracy, especially at shallow stitch points. (2) With a simple feature-matching loss at the target model's penultimate layer, heterogeneous VFMs become reliably stitchable across vision tasks. (3) For deep stitch points, the stitched model can surpass either constituent model at only a small inference overhead (for the stitch layer). Building on these findings, we further propose the VFM Stitch Tree (VST), which shares early layers across VFMs while retaining their later layers, yielding a controllable accuracy-latency trade-off for multimodal LLMs that often leverage multiple VFMs. Taken together, our study elevates stitching from a diagnostic probe to a practical recipe for integrating complementary VFM strengths and pinpointing where their representations align or diverge.
Attribute-based Object Grounding and Robot Grasp Detection with Spatial Reasoning
Sep 09, 2025Enabling robots to grasp objects specified through natural language is essential for effective human-robot interaction, yet it remains a significant challenge. Existing approaches often struggle with open-form language expressions and typically assume unambiguous target objects without duplicates. Moreover, they frequently rely on costly, dense pixel-wise annotations for both object grounding and grasp configuration. We present Attribute-based Object Grounding and Robotic Grasping (OGRG), a novel framework that interprets open-form language expressions and performs spatial reasoning to ground target objects and predict planar grasp poses, even in scenes containing duplicated object instances. We investigate OGRG in two settings: (1) Referring Grasp Synthesis (RGS) under pixel-wise full supervision, and (2) Referring Grasp Affordance (RGA) using weakly supervised learning with only single-pixel grasp annotations. Key contributions include a bi-directional vision-language fusion module and the integration of depth information to enhance geometric reasoning, improving both grounding and grasping performance. Experiment results show that OGRG outperforms strong baselines in tabletop scenes with diverse spatial language instructions. In RGS, it operates at 17.59 FPS on a single NVIDIA RTX 2080 Ti GPU, enabling potential use in closed-loop or multi-object sequential grasping, while delivering superior grounding and grasp prediction accuracy compared to all the baselines considered. Under the weakly supervised RGA setting, OGRG also surpasses baseline grasp-success rates in both simulation and real-robot trials, underscoring the effectiveness of its spatial reasoning design. Project page: https://z.umn.edu/ogrg
OpenM3D: Open Vocabulary Multi-view Indoor 3D Object Detection without Human Annotations
Aug 27, 2025Open-vocabulary (OV) 3D object detection is an emerging field, yet its exploration through image-based methods remains limited compared to 3D point cloud-based methods. We introduce OpenM3D, a novel open-vocabulary multi-view indoor 3D object detector trained without human annotations. In particular, OpenM3D is a single-stage detector adapting the 2D-induced voxel features from the ImGeoNet model. To support OV, it is jointly trained with a class-agnostic 3D localization loss requiring high-quality 3D pseudo boxes and a voxel-semantic alignment loss requiring diverse pre-trained CLIP features. We follow the training setting of OV-3DET where posed RGB-D images are given but no human annotations of 3D boxes or classes are available. We propose a 3D Pseudo Box Generation method using a graph embedding technique that combines 2D segments into coherent 3D structures. Our pseudo-boxes achieve higher precision and recall than other methods, including the method proposed in OV-3DET. We further sample diverse CLIP features from 2D segments associated with each coherent 3D structure to align with the corresponding voxel feature. The key to training a highly accurate single-stage detector requires both losses to be learned toward high-quality targets. At inference, OpenM3D, a highly efficient detector, requires only multi-view images for input and demonstrates superior accuracy and speed (0.3 sec. per scene) on ScanNet200 and ARKitScenes indoor benchmarks compared to existing methods. We outperform a strong two-stage method that leverages our class-agnostic detector with a ViT CLIP-based OV classifier and a baseline incorporating multi-view depth estimator on both accuracy and speed.
UA-Pose: Uncertainty-Aware 6D Object Pose Estimation and Online Object Completion with Partial References
Jun 09, 2025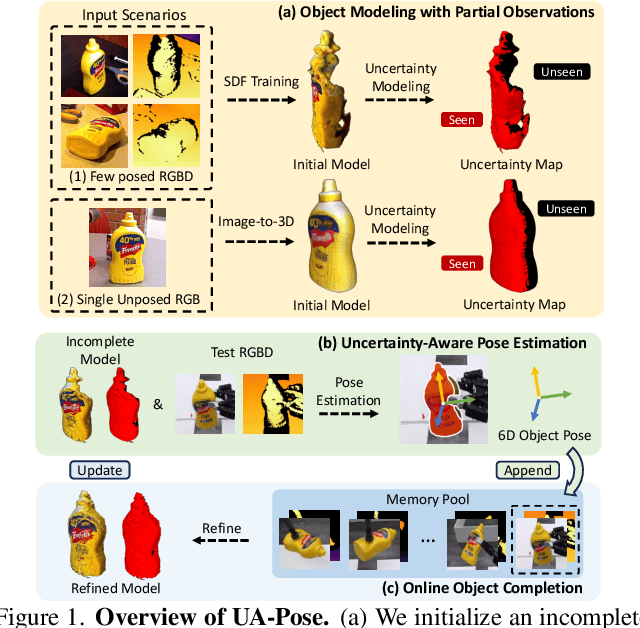

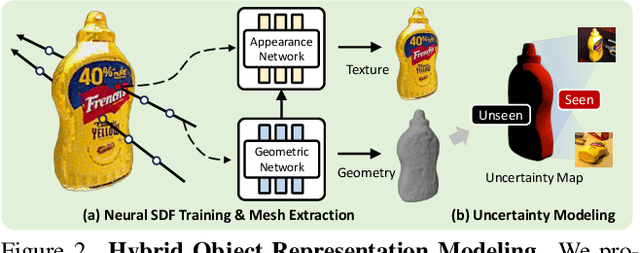

6D object pose estimation has shown strong generalizability to novel objects. However, existing methods often require either a complete, well-reconstructed 3D model or numerous reference images that fully cover the object. Estimating 6D poses from partial references, which capture only fragments of an object's appearance and geometry, remains challenging. To address this, we propose UA-Pose, an uncertainty-aware approach for 6D object pose estimation and online object completion specifically designed for partial references. We assume access to either (1) a limited set of RGBD images with known poses or (2) a single 2D image. For the first case, we initialize a partial object 3D model based on the provided images and poses, while for the second, we use image-to-3D techniques to generate an initial object 3D model. Our method integrates uncertainty into the incomplete 3D model, distinguishing between seen and unseen regions. This uncertainty enables confidence assessment in pose estimation and guides an uncertainty-aware sampling strategy for online object completion, enhancing robustness in pose estimation accuracy and improving object completeness. We evaluate our method on the YCB-Video, YCBInEOAT, and HO3D datasets, including RGBD sequences of YCB objects manipulated by robots and human hands. Experimental results demonstrate significant performance improvements over existing methods, particularly when object observations are incomplete or partially captured. Project page: https://minfenli.github.io/UA-Pose/
POp-GS: Next Best View in 3D-Gaussian Splatting with P-Optimality
Mar 10, 2025In this paper, we present a novel algorithm for quantifying uncertainty and information gained within 3D Gaussian Splatting (3D-GS) through P-Optimality. While 3D-GS has proven to be a useful world model with high-quality rasterizations, it does not natively quantify uncertainty. Quantifying uncertainty in parameters of 3D-GS is necessary to understand the information gained from acquiring new images as in active perception, or identify redundant images which can be removed from memory due to resource constraints in online 3D-GS SLAM. We propose to quantify uncertainty and information gain in 3D-GS by reformulating the problem through the lens of optimal experimental design, which is a classical solution to measuring information gain. By restructuring information quantification of 3D-GS through optimal experimental design, we arrive at multiple solutions, of which T-Optimality and D-Optimality perform the best quantitatively and qualitatively as measured on two popular datasets. Additionally, we propose a block diagonal approximation of the 3D-GS uncertainty, which provides a measure of correlation for computing more accurate information gain, at the expense of a greater computation cost.
V-MIND: Building Versatile Monocular Indoor 3D Detector with Diverse 2D Annotations
Dec 16, 2024The field of indoor monocular 3D object detection is gaining significant attention, fueled by the increasing demand in VR/AR and robotic applications. However, its advancement is impeded by the limited availability and diversity of 3D training data, owing to the labor-intensive nature of 3D data collection and annotation processes. In this paper, we present V-MIND (Versatile Monocular INdoor Detector), which enhances the performance of indoor 3D detectors across a diverse set of object classes by harnessing publicly available large-scale 2D datasets. By leveraging well-established monocular depth estimation techniques and camera intrinsic predictors, we can generate 3D training data by converting large-scale 2D images into 3D point clouds and subsequently deriving pseudo 3D bounding boxes. To mitigate distance errors inherent in the converted point clouds, we introduce a novel 3D self-calibration loss for refining the pseudo 3D bounding boxes during training. Additionally, we propose a novel ambiguity loss to address the ambiguity that arises when introducing new classes from 2D datasets. Finally, through joint training with existing 3D datasets and pseudo 3D bounding boxes derived from 2D datasets, V-MIND achieves state-of-the-art object detection performance across a wide range of classes on the Omni3D indoor dataset.
Modeling Uncertainty in 3D Gaussian Splatting through Continuous Semantic Splatting
Nov 04, 2024In this paper, we present a novel algorithm for probabilistically updating and rasterizing semantic maps within 3D Gaussian Splatting (3D-GS). Although previous methods have introduced algorithms which learn to rasterize features in 3D-GS for enhanced scene understanding, 3D-GS can fail without warning which presents a challenge for safety-critical robotic applications. To address this gap, we propose a method which advances the literature of continuous semantic mapping from voxels to ellipsoids, combining the precise structure of 3D-GS with the ability to quantify uncertainty of probabilistic robotic maps. Given a set of images, our algorithm performs a probabilistic semantic update directly on the 3D ellipsoids to obtain an expectation and variance through the use of conjugate priors. We also propose a probabilistic rasterization which returns per-pixel segmentation predictions with quantifiable uncertainty. We compare our method with similar probabilistic voxel-based methods to verify our extension to 3D ellipsoids, and perform ablation studies on uncertainty quantification and temporal smoothing.
Configurable Embodied Data Generation for Class-Agnostic RGB-D Video Segmentation
Oct 16, 2024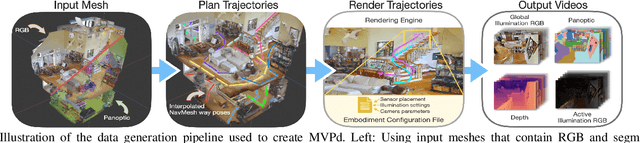

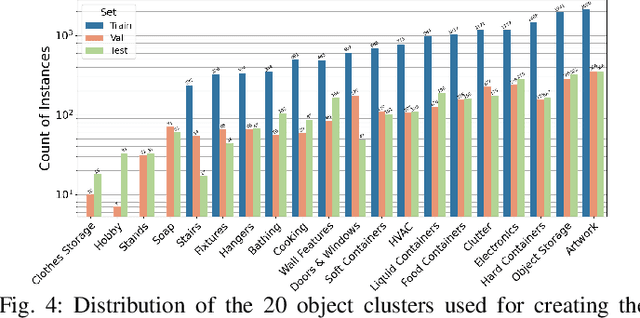
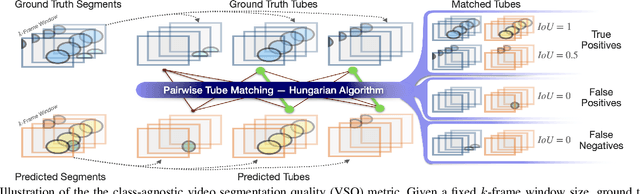
This paper presents a method for generating large-scale datasets to improve class-agnostic video segmentation across robots with different form factors. Specifically, we consider the question of whether video segmentation models trained on generic segmentation data could be more effective for particular robot platforms if robot embodiment is factored into the data generation process. To answer this question, a pipeline is formulated for using 3D reconstructions (e.g. from HM3DSem) to generate segmented videos that are configurable based on a robot's embodiment (e.g. sensor type, sensor placement, and illumination source). A resulting massive RGB-D video panoptic segmentation dataset (MVPd) is introduced for extensive benchmarking with foundation and video segmentation models, as well as to support embodiment-focused research in video segmentation. Our experimental findings demonstrate that using MVPd for finetuning can lead to performance improvements when transferring foundation models to certain robot embodiments, such as specific camera placements. These experiments also show that using 3D modalities (depth images and camera pose) can lead to improvements in video segmentation accuracy and consistency. The project webpage is available at https://topipari.com/projects/MVPd
Enhancing Single Image to 3D Generation using Gaussian Splatting and Hybrid Diffusion Priors
Oct 12, 2024
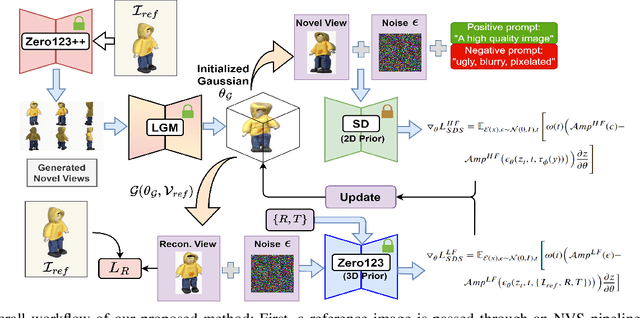
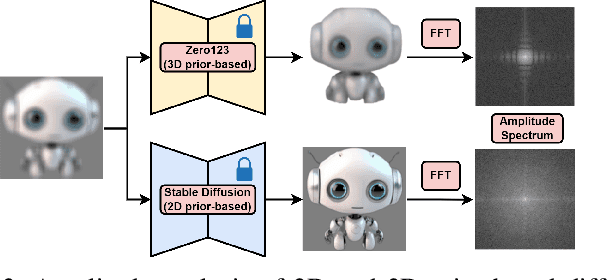
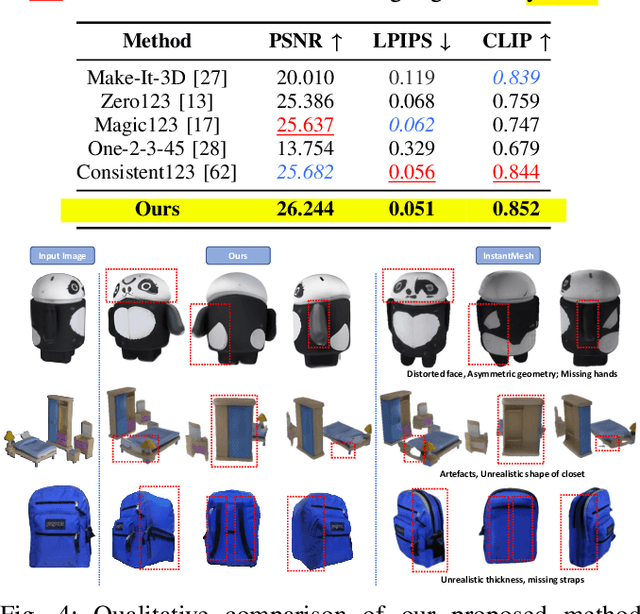
3D object generation from a single image involves estimating the full 3D geometry and texture of unseen views from an unposed RGB image captured in the wild. Accurately reconstructing an object's complete 3D structure and texture has numerous applications in real-world scenarios, including robotic manipulation, grasping, 3D scene understanding, and AR/VR. Recent advancements in 3D object generation have introduced techniques that reconstruct an object's 3D shape and texture by optimizing the efficient representation of Gaussian Splatting, guided by pre-trained 2D or 3D diffusion models. However, a notable disparity exists between the training datasets of these models, leading to distinct differences in their outputs. While 2D models generate highly detailed visuals, they lack cross-view consistency in geometry and texture. In contrast, 3D models ensure consistency across different views but often result in overly smooth textures. We propose bridging the gap between 2D and 3D diffusion models to address this limitation by integrating a two-stage frequency-based distillation loss with Gaussian Splatting. Specifically, we leverage geometric priors in the low-frequency spectrum from a 3D diffusion model to maintain consistent geometry and use a 2D diffusion model to refine the fidelity and texture in the high-frequency spectrum of the generated 3D structure, resulting in more detailed and fine-grained outcomes. Our approach enhances geometric consistency and visual quality, outperforming the current SOTA. Additionally, we demonstrate the easy adaptability of our method for efficient object pose estimation and tracking.