 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-based Object Grounding and Robot Grasp Detection with Spatial Reasoning
Sep 09, 2025Enabling robots to grasp objects specified through natural language is essential for effective human-robot interaction, yet it remains a significant challenge. Existing approaches often struggle with open-form language expressions and typically assume unambiguous target objects without duplicates. Moreover, they frequently rely on costly, dense pixel-wise annotations for both object grounding and grasp configuration. We present Attribute-based Object Grounding and Robotic Grasping (OGRG), a novel framework that interprets open-form language expressions and performs spatial reasoning to ground target objects and predict planar grasp poses, even in scenes containing duplicated object instances. We investigate OGRG in two settings: (1) Referring Grasp Synthesis (RGS) under pixel-wise full supervision, and (2) Referring Grasp Affordance (RGA) using weakly supervised learning with only single-pixel grasp annotations. Key contributions include a bi-directional vision-language fusion module and the integration of depth information to enhance geometric reasoning, improving both grounding and grasping performance. Experiment results show that OGRG outperforms strong baselines in tabletop scenes with diverse spatial language instructions. In RGS, it operates at 17.59 FPS on a single NVIDIA RTX 2080 Ti GPU, enabling potential use in closed-loop or multi-object sequential grasping, while delivering superior grounding and grasp prediction accuracy compared to all the baselines considered. Under the weakly supervised RGA setting, OGRG also surpasses baseline grasp-success rates in both simulation and real-robot trials, underscoring the effectiveness of its spatial reasoning design. Project page: https://z.umn.edu/ogrg
HomeEmergency -- Using Audio to Find and Respond to Emergencies in the Home
Apr 01, 2025



In the United States alone accidental home deaths exceed 128,000 per year. Our work aims to enable home robots who respond to emergency scenarios in the home, preventing injuries and deaths. We introduce a new dataset of household emergencies based in the ThreeDWorld simulator. Each scenario in our dataset begins with an instantaneous or periodic sound which may or may not be an emergency. The agent must navigate the multi-room home scene using prior observations, alongside audio signals and images from the simulator, to determine if there is an emergency or not. In addition to our new dataset, we present a modular approach for localizing and identifying potential home emergencies. Underpinning our approach is a novel probabilistic dynamic scene graph (P-DSG), where our key insight is that graph nodes corresponding to agents can be represented with a probabilistic edge. This edge, when refined using Bayesian inference, enables efficient and effective localization of agents in the scene. We also utilize multi-modal vision-language models (VLMs) as a component in our approach, determining object traits (e.g. flammability) and identifying emergencies. We present a demonstration of our method completing a real-world version of our task on a consumer robot, showing the transferability of both our task and our method. Our dataset will be released to the public upon this papers publication.
Modeling Uncertainty in 3D Gaussian Splatting through Continuous Semantic Splatting
Nov 04, 2024In this paper, we present a novel algorithm for probabilistically updating and rasterizing semantic maps within 3D Gaussian Splatting (3D-GS). Although previous methods have introduced algorithms which learn to rasterize features in 3D-GS for enhanced scene understanding, 3D-GS can fail without warning which presents a challenge for safety-critical robotic applications. To address this gap, we propose a method which advances the literature of continuous semantic mapping from voxels to ellipsoids, combining the precise structure of 3D-GS with the ability to quantify uncertainty of probabilistic robotic maps. Given a set of images, our algorithm performs a probabilistic semantic update directly on the 3D ellipsoids to obtain an expectation and variance through the use of conjugate priors. We also propose a probabilistic rasterization which returns per-pixel segmentation predictions with quantifiable uncertainty. We compare our method with similar probabilistic voxel-based methods to verify our extension to 3D ellipsoids, and perform ablation studies on uncertainty quantification and temporal smoothing.
Configurable Embodied Data Generation for Class-Agnostic RGB-D Video Segmentation
Oct 16, 2024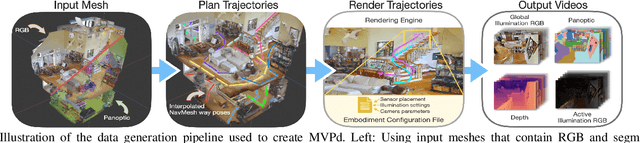

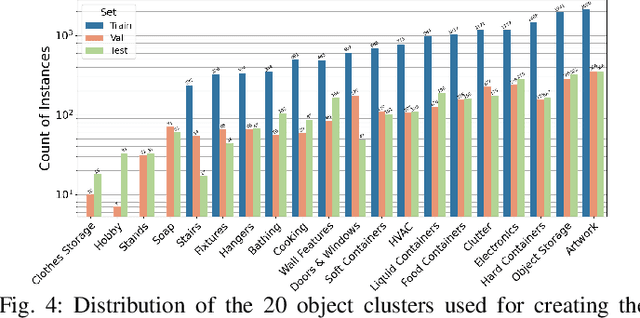
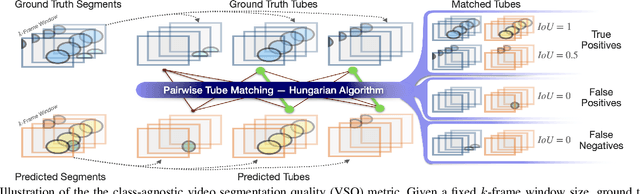
This paper presents a method for generating large-scale datasets to improve class-agnostic video segmentation across robots with different form factors. Specifically, we consider the question of whether video segmentation models trained on generic segmentation data could be more effective for particular robot platforms if robot embodiment is factored into the data generation process. To answer this question, a pipeline is formulated for using 3D reconstructions (e.g. from HM3DSem) to generate segmented videos that are configurable based on a robot's embodiment (e.g. sensor type, sensor placement, and illumination source). A resulting massive RGB-D video panoptic segmentation dataset (MVPd) is introduced for extensive benchmarking with foundation and video segmentation models, as well as to support embodiment-focused research in video segmentation. Our experimental findings demonstrate that using MVPd for finetuning can lead to performance improvements when transferring foundation models to certain robot embodiments, such as specific camera placements. These experiments also show that using 3D modalities (depth images and camera pose) can lead to improvements in video segmentation accuracy and consistency. The project webpage is available at https://topipari.com/projects/MVPd
Enhancing Single Image to 3D Generation using Gaussian Splatting and Hybrid Diffusion Priors
Oct 12, 2024
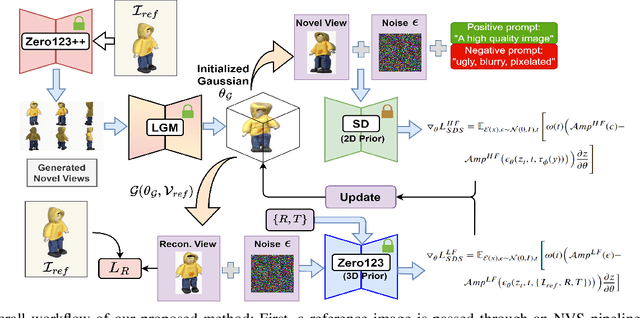
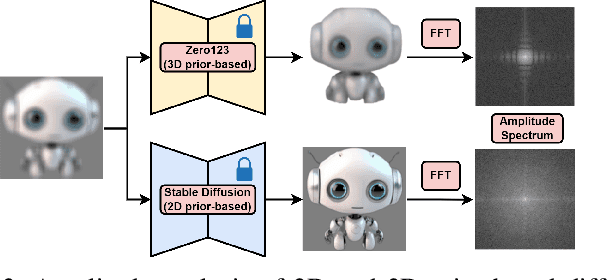
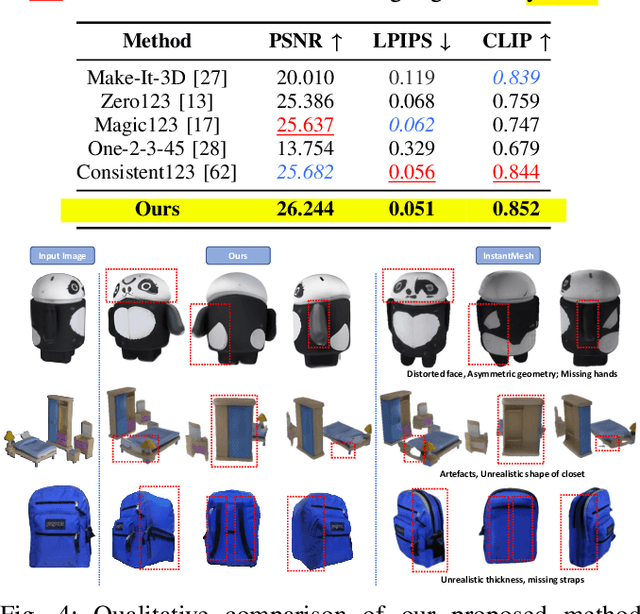
3D object generation from a single image involves estimating the full 3D geometry and texture of unseen views from an unposed RGB image captured in the wild. Accurately reconstructing an object's complete 3D structure and texture has numerous applications in real-world scenarios, including robotic manipulation, grasping, 3D scene understanding, and AR/VR. Recent advancements in 3D object generation have introduced techniques that reconstruct an object's 3D shape and texture by optimizing the efficient representation of Gaussian Splatting, guided by pre-trained 2D or 3D diffusion models. However, a notable disparity exists between the training datasets of these models, leading to distinct differences in their outputs. While 2D models generate highly detailed visuals, they lack cross-view consistency in geometry and texture. In contrast, 3D models ensure consistency across different views but often result in overly smooth textures. We propose bridging the gap between 2D and 3D diffusion models to address this limitation by integrating a two-stage frequency-based distillation loss with Gaussian Splatting. Specifically, we leverage geometric priors in the low-frequency spectrum from a 3D diffusion model to maintain consistent geometry and use a 2D diffusion model to refine the fidelity and texture in the high-frequency spectrum of the generated 3D structure, resulting in more detailed and fine-grained outcomes. Our approach enhances geometric consistency and visual quality, outperforming the current SOTA. Additionally, we demonstrate the easy adaptability of our method for efficient object pose estimation and tracking.
VLPG-Nav: Object Navigation Using Visual Language Pose Graph and Object Localization Probability Maps
Aug 15, 2024



We present VLPG-Nav, a visual language navigation method for guiding robots to specified objects within household scenes. Unlike existing methods primarily focused on navigating the robot toward objects, our approach considers the additional challenge of centering the object within the robot's camera view. Our method builds a visual language pose graph (VLPG) that functions as a spatial map of VL embeddings. Given an open vocabulary object query, we plan a viewpoint for object navigation using the VLPG. Despite navigating to the viewpoint, real-world challenges like object occlusion, displacement, and the robot's localization error can prevent visibility. We build an object localization probability map that leverages the robot's current observations and prior VLPG. When the object isn't visible, the probability map is updated and an alternate viewpoint is computed. In addition, we propose an object-centering formulation that locally adjusts the robot's pose to center the object in the camera view. We evaluate the effectiveness of our approach through simulations and real-world experiments, evaluating its ability to successfully view and center the object within the camera field of view. VLPG-Nav demonstrates improved performance in locating the object, navigating around occlusions, and centering the object within the robot's camera view, outperforming the selected baselines in the evaluation metrics.
Correspondence-Free SE(3) Point Cloud Registration in RKHS via Unsupervised Equivariant Learning
Jul 29, 2024This paper introduces a robust unsupervised SE(3) point cloud registration method that operates without requiring point correspondences. The method frames point clouds as functions in a reproducing kernel Hilbert space (RKHS), leveraging SE(3)-equivariant features for direct feature space registration. A novel RKHS distance metric is proposed, offering reliable performance amidst noise, outliers, and asymmetrical data. An unsupervised training approach is introduced to effectively handle limited ground truth data, facilitating adaptation to real datasets. The proposed method outperforms classical and supervised methods in terms of registration accuracy on both synthetic (ModelNet40) and real-world (ETH3D) noisy, outlier-rich datasets. To our best knowledge, this marks the first instance of successful real RGB-D odometry data registration using an equivariant method. The code is available at {https://sites.google.com/view/eccv24-equivalign}
CSCPR: Cross-Source-Context Indoor RGB-D Place Recognition
Jul 24, 2024



We present a new algorithm, Cross-Source-Context Place Recognition (CSCPR), for RGB-D indoor place recognition that integrates global retrieval and reranking into a single end-to-end model. Unlike prior approaches that primarily focus on the RGB domain, CSCPR is designed to handle the RGB-D data. We extend the Context-of-Clusters (CoCs) for handling noisy colorized point clouds and introduce two novel modules for reranking: the Self-Context Cluster (SCC) and Cross Source Context Cluster (CSCC), which enhance feature representation and match query-database pairs based on local features, respectively. We also present two new datasets, ScanNetIPR and ARKitIPR. Our experiments demonstrate that CSCPR significantly outperforms state-of-the-art models on these datasets by at least 36.5% in Recall@1 at ScanNet-PR dataset and 44% in new datasets. Code and datasets will be released.
LOC-ZSON: Language-driven Object-Centric Zero-Shot Object Retrieval and Navigation
May 08, 2024



In this paper, we present LOC-ZSON, a novel Language-driven Object-Centric image representation for object navigation task within complex scenes. We propose an object-centric image representation and corresponding losses for visual-language model (VLM) fine-tuning, which can handle complex object-level queries. In addition, we design a novel LLM-based augmentation and prompt templates for stability during training and zero-shot inference. We implement our method on Astro robot and deploy it in both simulated and real-world environments for zero-shot object navigation. We show that our proposed method can achieve an improvement of 1.38 - 13.38% in terms of text-to-image recall on different benchmark settings for the retrieval task. For object navigation, we show the benefit of our approach in simulation and real world, showing 5% and 16.67% improvement in terms of navigation success rate, respectively.
PoCo: Point Context Cluster for RGBD Indoor Place Recognition
Apr 03, 2024We present a novel end-to-end algorithm (PoCo) for the indoor RGB-D place recognition task, aimed at identifying the most likely match for a given query frame within a reference database. The task presents inherent challenges attributed to the constrained field of view and limited range of perception sensors. We propose a new network architecture, which generalizes the recent Context of Clusters (CoCs) to extract global descriptors directly from the noisy point clouds through end-to-end learning. Moreover, we develop the architecture by integrating both color and geometric modalities into the point features to enhance the global descriptor representation. We conducted evaluations on public datasets ScanNet-PR and ARKit with 807 and 5047 scenarios, respectively. PoCo achieves SOTA performance: on ScanNet-PR, we achieve R@1 of 64.63%, a 5.7% improvement from the best-published result CGis (61.12%); on Arkit, we achieve R@1 of 45.12%, a 13.3% improvement from the best-published result CGis (39.82%). In addition, PoCo shows higher efficiency than CGis in inference time (1.75X-faster), and we demonstrate the effectiveness of PoCo in recognizing places within a real-world laboratory environment.