 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot
Apr 15, 2026Scientific peer review faces mounting strain as submission volumes surge, making it increasingly difficult to sustain review quality, consistency, and timeliness. Recent advances in AI have led the community to consider its use in peer review, yet a key unresolved question is whether AI can generate technically sound reviews at real-world conference scale. Here we report the first large-scale field deployment of AI-assisted peer review: every main-track submission at AAAI-26 received one clearly identified AI review from a state-of-the-art system. The system combined frontier models, tool use, and safeguards in a multi-stage process to generate reviews for all 22,977 full-review papers in less than a day. A large-scale survey of AAAI-26 authors and program committee members showed that participants not only found AI reviews useful, but actually preferred them to human reviews on key dimensions such as technical accuracy and research suggestions. We also introduce a novel benchmark and find that our system substantially outperforms a simple LLM-generated review baseline at detecting a variety of scientific weaknesses. Together, these results show that state-of-the-art AI methods can already make meaningful contributions to scientific peer review at conference scale, opening a path toward the next generation of synergistic human-AI teaming for evaluating research.
Configurable Embodied Data Generation for Class-Agnostic RGB-D Video Segmentation
Oct 16, 2024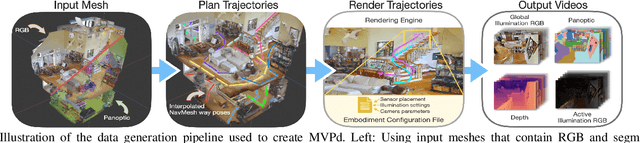

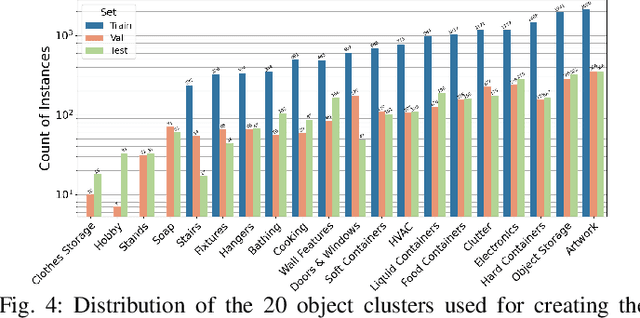
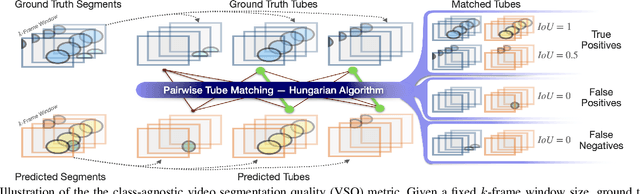
This paper presents a method for generating large-scale datasets to improve class-agnostic video segmentation across robots with different form factors. Specifically, we consider the question of whether video segmentation models trained on generic segmentation data could be more effective for particular robot platforms if robot embodiment is factored into the data generation process. To answer this question, a pipeline is formulated for using 3D reconstructions (e.g. from HM3DSem) to generate segmented videos that are configurable based on a robot's embodiment (e.g. sensor type, sensor placement, and illumination source). A resulting massive RGB-D video panoptic segmentation dataset (MVPd) is introduced for extensive benchmarking with foundation and video segmentation models, as well as to support embodiment-focused research in video segmentation. Our experimental findings demonstrate that using MVPd for finetuning can lead to performance improvements when transferring foundation models to certain robot embodiments, such as specific camera placements. These experiments also show that using 3D modalities (depth images and camera pose) can lead to improvements in video segmentation accuracy and consistency. The project webpage is available at https://topipari.com/projects/MVPd
Single-View 3D Reconstruction via SO(2)-Equivariant Gaussian Sculpting Networks
Sep 11, 2024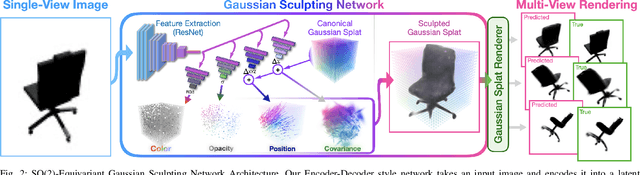
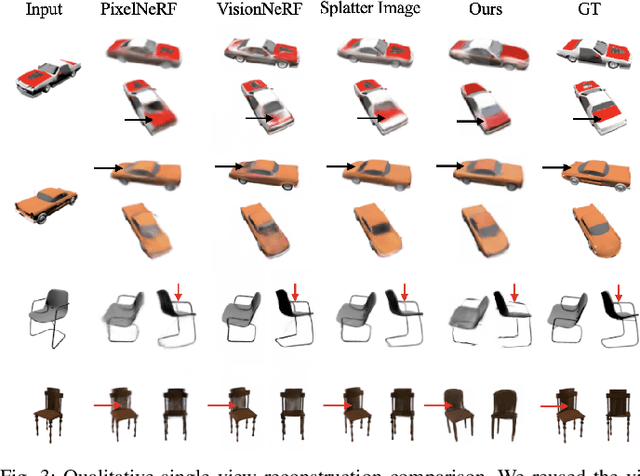

This paper introduces SO(2)-Equivariant Gaussian Sculpting Networks (GSNs) as an approach for SO(2)-Equivariant 3D object reconstruction from single-view image observations. GSNs take a single observation as input to generate a Gaussian splat representation describing the observed object's geometry and texture. By using a shared feature extractor before decoding Gaussian colors, covariances, positions, and opacities, GSNs achieve extremely high throughput (>150FPS). Experiments demonstrate that GSNs can be trained efficiently using a multi-view rendering loss and are competitive, in quality, with expensive diffusion-based reconstruction algorithms. The GSN model is validated on multiple benchmark experiments. Moreover, we demonstrate the potential for GSNs to be used within a robotic manipulation pipeline for object-centric grasping.
OVAL-Prompt: Open-Vocabulary Affordance Localization for Robot Manipulation through LLM Affordance-Grounding
Apr 17, 2024



In order for robots to interact with objects effectively, they must understand the form and function of each object they encounter. Essentially, robots need to understand which actions each object affords, and where those affordances can be acted on. Robots are ultimately expected to operate in unstructured human environments, where the set of objects and affordances is not known to the robot before deployment (i.e. the open-vocabulary setting). In this work, we introduce OVAL-Prompt, a prompt-based approach for open-vocabulary affordance localization in RGB-D images. By leveraging a Vision Language Model (VLM) for open-vocabulary object part segmentation and a Large Language Model (LLM) to ground each part-segment-affordance, OVAL-Prompt demonstrates generalizability to novel object instances, categories, and affordances without domain-specific finetuning. Quantitative experiments demonstrate that without any finetuning, OVAL-Prompt achieves localization accuracy that is competitive with supervised baseline models. Moreover, qualitative experiments show that OVAL-Prompt enables affordance-based robot manipulation of open-vocabulary object instances and categories.
TransNet: Transparent Object Manipulation Through Category-Level Pose Estimation
Jul 23, 2023



Transparent objects present multiple distinct challenges to visual perception systems. First, their lack of distinguishing visual features makes transparent objects harder to detect and localize than opaque objects. Even humans find certain transparent surfaces with little specular reflection or refraction, like glass doors, difficult to perceive. A second challenge is that depth sensors typically used for opaque object perception cannot obtain accurate depth measurements on transparent surfaces due to their unique reflective properties. Stemming from these challenges, we observe that transparent object instances within the same category, such as cups, look more similar to each other than to ordinary opaque objects of that same category. Given this observation, the present paper explores the possibility of category-level transparent object pose estimation rather than instance-level pose estimation. We propose \textit{\textbf{TransNet}}, a two-stage pipeline that estimates category-level transparent object pose using localized depth completion and surface normal estimation. TransNet is evaluated in terms of pose estimation accuracy on a large-scale transparent object dataset and compared to a state-of-the-art category-level pose estimation approach. Results from this comparison demonstrate that TransNet achieves improved pose estimation accuracy on transparent objects. Moreover, we use TransNet to build an autonomous transparent object manipulation system for robotic pick-and-place and pouring tasks.
DNBP: Differentiable Nonparametric Belief Propagation
Mar 08, 2023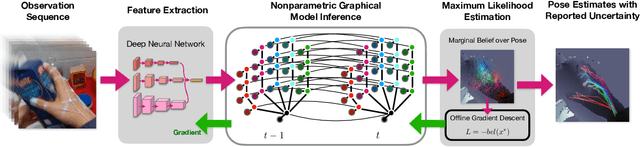
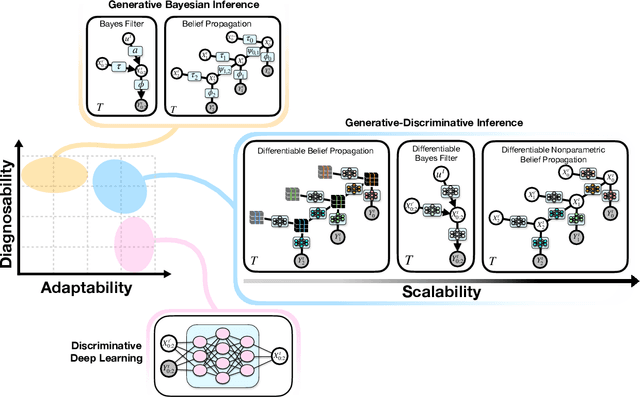
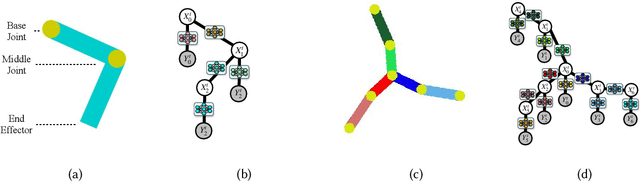
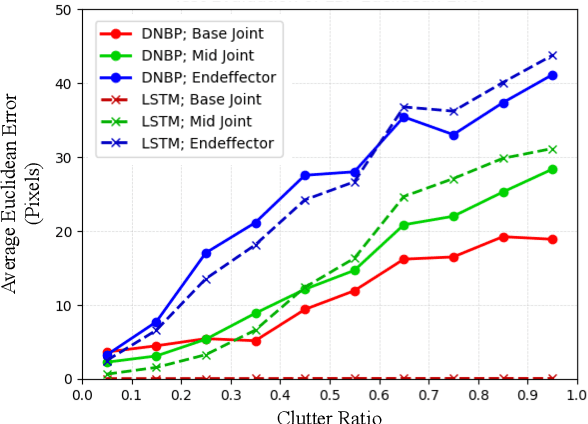
We present a differentiable approach to learn the probabilistic factors used for inference by a nonparametric belief propagation algorithm. Existing nonparametric belief propagation methods rely on domain-specific features encoded in the probabilistic factors of a graphical model. In this work, we replace each crafted factor with a differentiable neural network enabling the factors to be learned using an efficient optimization routine from labeled data. By combining differentiable neural networks with an efficient belief propagation algorithm, our method learns to maintain a set of marginal posterior samples using end-to-end training. We evaluate our differentiable nonparametric belief propagation (DNBP) method on a set of articulated pose tracking tasks and compare performance with learned baselines. Results from these experiments demonstrate the effectiveness of using learned factors for tracking and suggest the practical advantage over hand-crafted approaches. The project webpage is available at: https://progress.eecs.umich.edu/projects/dnbp/ .
TransNet: Category-Level Transparent Object Pose Estimation
Aug 22, 2022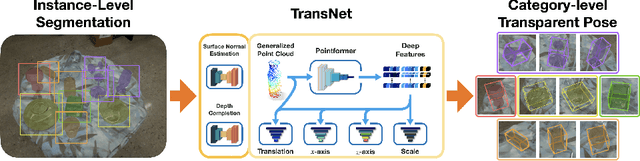



Transparent objects present multiple distinct challenges to visual perception systems. First, their lack of distinguishing visual features makes transparent objects harder to detect and localize than opaque objects. Even humans find certain transparent surfaces with little specular reflection or refraction, e.g. glass doors, difficult to perceive. A second challenge is that common depth sensors typically used for opaque object perception cannot obtain accurate depth measurements on transparent objects due to their unique reflective properties. Stemming from these challenges, we observe that transparent object instances within the same category (e.g. cups) look more similar to each other than to ordinary opaque objects of that same category. Given this observation, the present paper sets out to explore the possibility of category-level transparent object pose estimation rather than instance-level pose estimation. We propose TransNet, a two-stage pipeline that learns to estimate category-level transparent object pose using localized depth completion and surface normal estimation. TransNet is evaluated in terms of pose estimation accuracy on a recent, large-scale transparent object dataset and compared to a state-of-the-art category-level pose estimation approach. Results from this comparison demonstrate that TransNet achieves improved pose estimation accuracy on transparent objects and key findings from the included ablation studies suggest future directions for performance improvements.
ClearPose: Large-scale Transparent Object Dataset and Benchmark
Mar 08, 2022
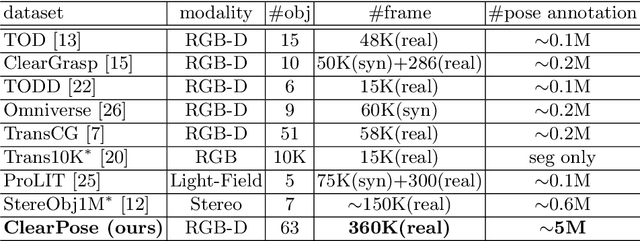

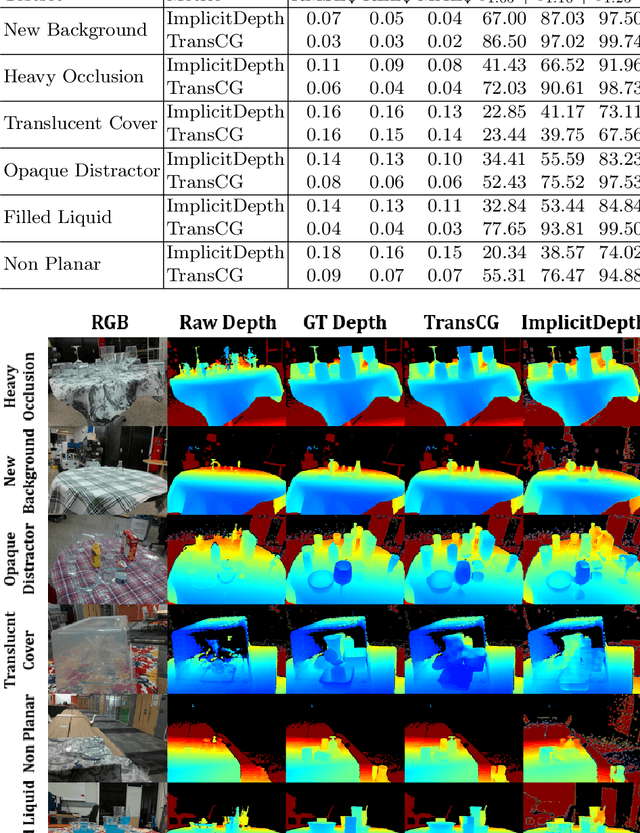
Transparent objects are ubiquitous in household settings and pose distinct challenges for visual sensing and perception systems. The optical properties of transparent objects leave conventional 3D sensors alone unreliable for object depth and pose estimation. These challenges are highlighted by the shortage of large-scale RGB-Depth datasets focusing on transparent objects in real-world settings. In this work, we contribute a large-scale real-world RGB-Depth transparent object dataset named ClearPose to serve as a benchmark dataset for segmentation, scene-level depth completion and object-centric pose estimation tasks. The ClearPose dataset contains over 350K labeled real-world RGB-Depth frames and 4M instance annotations covering 63 household objects. The dataset includes object categories commonly used in daily life under various lighting and occluding conditions as well as challenging test scenarios such as cases of occlusion by opaque or translucent objects, non-planar orientations, presence of liquids, etc. We benchmark several state-of-the-art depth completion and object pose estimation deep neural networks on ClearPose.
Differentiable Nonparametric Belief Propagation
Jan 15, 2021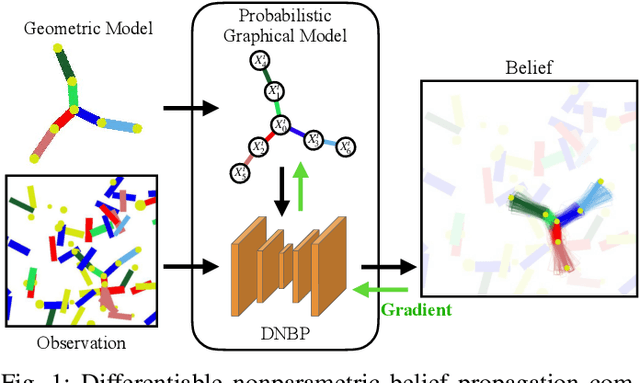
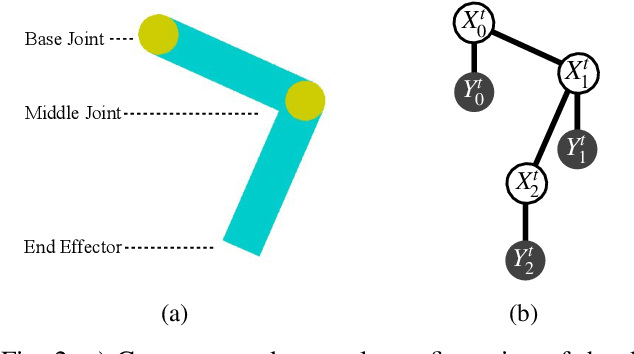

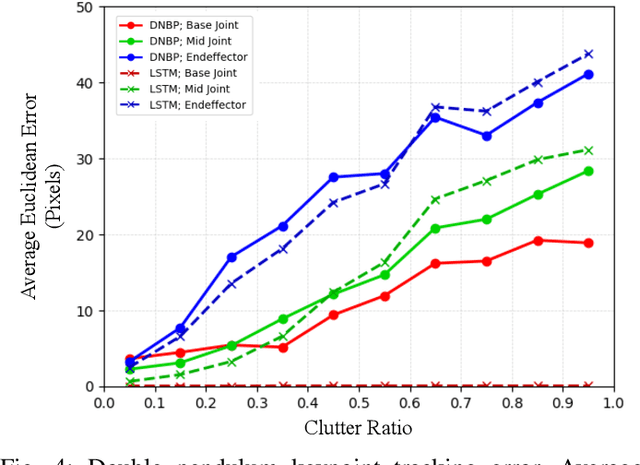
We present a differentiable approach to learn the probabilistic factors used for inference by a nonparametric belief propagation algorithm. Existing nonparametric belief propagation methods rely on domain-specific features encoded in the probabilistic factors of a graphical model. In this work, we replace each crafted factor with a differentiable neural network enabling the factors to be learned using an efficient optimization routine from labeled data. By combining differentiable neural networks with an efficient belief propagation algorithm, our method learns to maintain a set of marginal posterior samples using end-to-end training. We evaluate our differentiable nonparametric belief propagation (DNBP) method on a set of articulated pose tracking tasks and compare performance with a recurrent neural network. Results from this comparison demonstrate the effectiveness of using learned factors for tracking and suggest the practical advantage over hand-crafted approaches. The project webpage is available at: progress.eecs.umich.edu/projects/dnbp.
Factored Pose Estimation of Articulated Objects using Efficient Nonparametric Belief Propagation
Dec 10, 2018
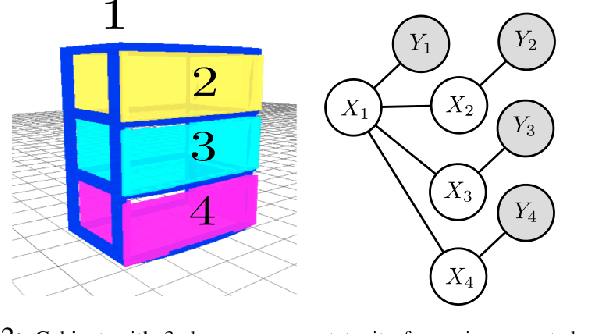

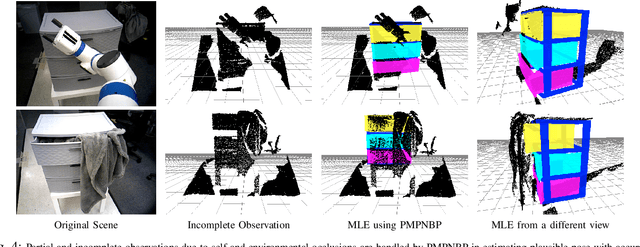
Robots working in human environments often encounter a wide range of articulated objects, such as tools, cabinets, and other jointed objects. Such articulated objects can take an infinite number of possible poses, as a point in a potentially high-dimensional continuous space. A robot must perceive this continuous pose to manipulate the object to a desired pose. This problem of perception and manipulation of articulated objects remains a challenge due to its high dimensionality and multi-modal uncertainty. In this paper, we propose a factored approach to estimate the poses of articulated objects using an efficient nonparametric belief propagation algorithm. We consider inputs as geometrical models with articulation constraints, and observed RGBD sensor data. The proposed framework produces object-part pose beliefs iteratively. The problem is formulated as a pairwise Markov Random Field (MRF) where each hidden node (continuous pose variable) is an observed object-part's pose and the edges denote the articulation constraints between the parts. We propose articulated pose estimation by Pull Message Passing algorithm for Nonparametric Belief Propagation (PMPNBP) and evaluate its convergence properties over scenes with articulated objects.