 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact-resistant, autonomous robots inspired by tensegrity architecture
Jan 25, 2025



Future robots will navigate perilous, remote environments with resilience and autonomy. Researchers have proposed building robots with compliant bodies to enhance robustness, but this approach often sacrifices the autonomous capabilities expected of rigid robots. Inspired by tensegrity architecture, we introduce a tensegrity robot -- a hybrid robot made from rigid struts and elastic tendons -- that demonstrates the advantages of compliance and the autonomy necessary for task performance. This robot boasts impact resistance and autonomy in a field environment and additional advances in the state of the art, including surviving harsh impacts from drops (at least 5.7 m), accurately reconstructing its shape and orientation using on-board sensors, achieving high locomotion speeds (18 bar lengths per minute), and climbing the steepest incline of any tensegrity robot (28 degrees). We characterize the robot's locomotion on unstructured terrain, showcase its autonomous capabilities in navigation tasks, and demonstrate its robustness by rolling it off a cliff.
OVIR-3D: Open-Vocabulary 3D Instance Retrieval Without Training on 3D Data
Nov 06, 2023

This work presents OVIR-3D, a straightforward yet effective method for open-vocabulary 3D object instance retrieval without using any 3D data for training. Given a language query, the proposed method is able to return a ranked set of 3D object instance segments based on the feature similarity of the instance and the text query. This is achieved by a multi-view fusion of text-aligned 2D region proposals into 3D space, where the 2D region proposal network could leverage 2D datasets, which are more accessible and typically larger than 3D datasets. The proposed fusion process is efficient as it can be performed in real-time for most indoor 3D scenes and does not require additional training in 3D space. Experiments on public datasets and a real robot show the effectiveness of the method and its potential for applications in robot navigation and manipulation.
Context-Aware Entity Grounding with Open-Vocabulary 3D Scene Graphs
Sep 27, 2023



We present an Open-Vocabulary 3D Scene Graph (OVSG), a formal framework for grounding a variety of entities, such as object instances, agents, and regions, with free-form text-based queries. Unlike conventional semantic-based object localization approaches, our system facilitates context-aware entity localization, allowing for queries such as ``pick up a cup on a kitchen table" or ``navigate to a sofa on which someone is sitting". In contrast to existing research on 3D scene graphs, OVSG supports free-form text input and open-vocabulary querying. Through a series of comparative experiments using the ScanNet dataset and a self-collected dataset, we demonstrate that our proposed approach significantly surpasses the performance of previous semantic-based localization techniques. Moreover, we highlight the practical application of OVSG in real-world robot navigation and manipulation experiments.
Self-Supervised Learning of Object Segmentation from Unlabeled RGB-D Videos
Apr 09, 2023



This work proposes a self-supervised learning system for segmenting rigid objects in RGB images. The proposed pipeline is trained on unlabeled RGB-D videos of static objects, which can be captured with a camera carried by a mobile robot. A key feature of the self-supervised training process is a graph-matching algorithm that operates on the over-segmentation output of the point cloud that is reconstructed from each video. The graph matching, along with point cloud registration, is able to find reoccurring object patterns across videos and combine them into 3D object pseudo labels, even under occlusions or different viewing angles. Projected 2D object masks from 3D pseudo labels are used to train a pixel-wise feature extractor through contrastive learning. During online inference, a clustering method uses the learned features to cluster foreground pixels into object segments. Experiments highlight the method's effectiveness on both real and synthetic video datasets, which include cluttered scenes of tabletop objects. The proposed method outperforms existing unsupervised methods for object segmentation by a large margin.
ARMBench: An Object-centric Benchmark Dataset for Robotic Manipulation
Mar 29, 2023This paper introduces Amazon Robotic Manipulation Benchmark (ARMBench), a large-scale, object-centric benchmark dataset for robotic manipulation in the context of a warehouse. Automation of operations in modern warehouses requires a robotic manipulator to deal with a wide variety of objects, unstructured storage, and dynamically changing inventory. Such settings pose challenges in perceiving the identity, physical characteristics, and state of objects during manipulation. Existing datasets for robotic manipulation consider a limited set of objects or utilize 3D models to generate synthetic scenes with limitation in capturing the variety of object properties, clutter, and interactions. We present a large-scale dataset collected in an Amazon warehouse using a robotic manipulator performing object singulation from containers with heterogeneous contents. ARMBench contains images, videos, and metadata that corresponds to 235K+ pick-and-place activities on 190K+ unique objects. The data is captured at different stages of manipulation, i.e., pre-pick, during transfer, and after placement. Benchmark tasks are proposed by virtue of high-quality annotations and baseline performance evaluation are presented on three visual perception challenges, namely 1) object segmentation in clutter, 2) object identification, and 3) defect detection. ARMBench can be accessed at http://armbench.com
Real2Sim2Real Transfer for Control of Cable-driven Robots via a Differentiable Physics Engine
Sep 20, 2022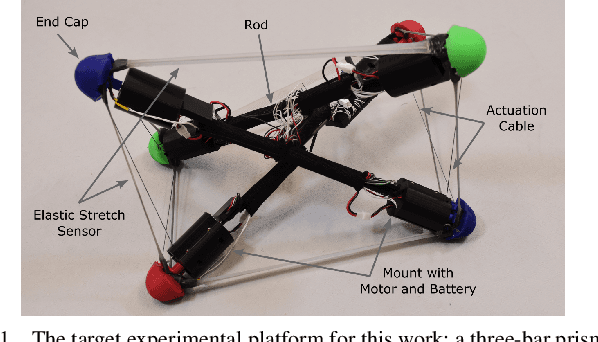
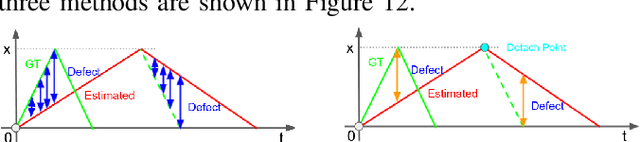
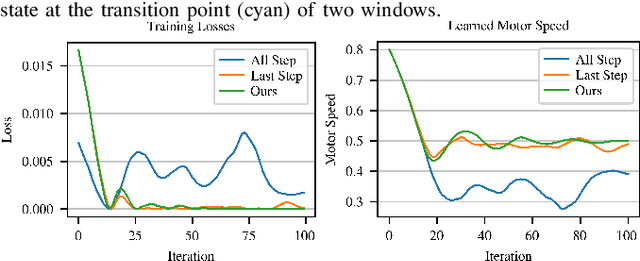
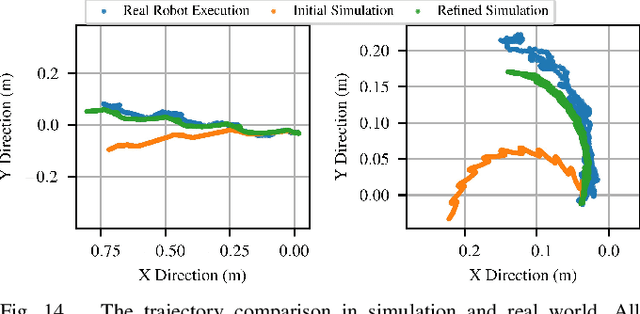
Tensegrity robots, composed of rigid rods and flexible cables, exhibit high strength-to-weight ratios and extreme deformations, enabling them to navigate unstructured terrain and even survive harsh impacts. However, they are hard to control due to their high dimensionality, complex dynamics, and coupled architecture. Physics-based simulation is one avenue for developing locomotion policies that can then be transferred to real robots, but modeling tensegrity robots is a complex task, so simulations experience a substantial sim2real gap. To address this issue, this paper describes a Real2Sim2Real strategy for tensegrity robots. This strategy is based on a differential physics engine that can be trained given limited data from a real robot (i.e. offline measurements and one random trajectory) and achieve a high enough accuracy to discover transferable locomotion policies. Beyond the overall pipeline, key contributions of this work include computing non-zero gradients at contact points, a loss function, and a trajectory segmentation technique that avoid conflicts in gradient evaluation during training. The proposed pipeline is demonstrated and evaluated on a real 3-bar tensegrity robot.
6N-DoF Pose Tracking for Tensegrity Robots
May 29, 2022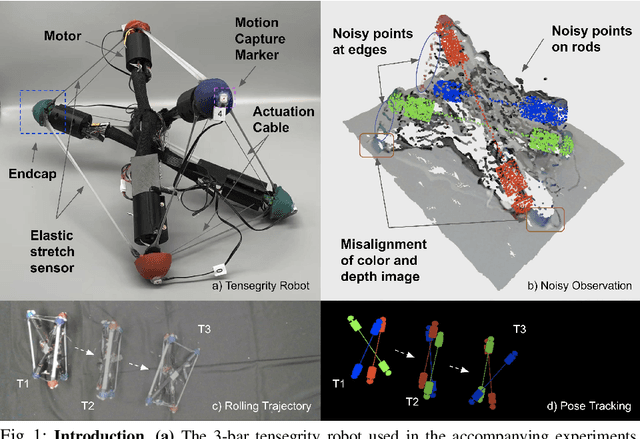
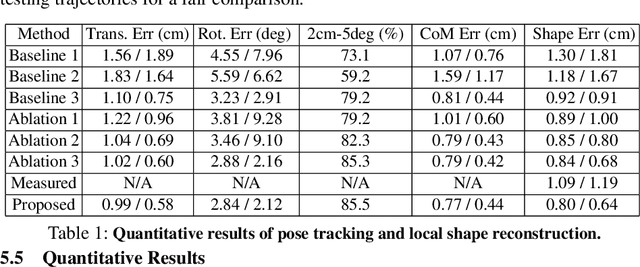

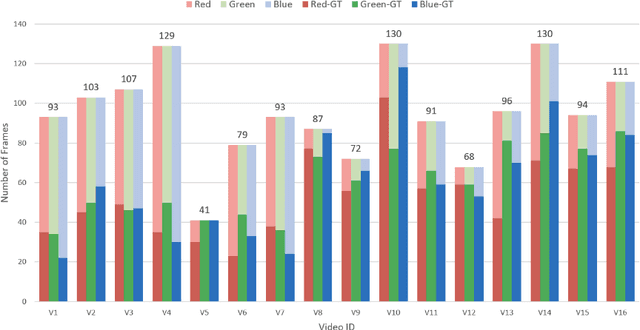
Tensegrity robots, which are composed of rigid compressive elements (rods) and flexible tensile elements (e.g., cables), have a variety of advantages, including flexibility, light weight, and resistance to mechanical impact. Nevertheless, the hybrid soft-rigid nature of these robots also complicates the ability to localize and track their state. This work aims to address what has been recognized as a grand challenge in this domain, i.e., the pose tracking of tensegrity robots through a markerless, vision-based method, as well as novel, onboard sensors that can measure the length of the robot's cables. In particular, an iterative optimization process is proposed to estimate the 6-DoF poses of each rigid element of a tensegrity robot from an RGB-D video as well as endcap distance measurements from the cable sensors. To ensure the pose estimates of rigid elements are physically feasible, i.e., they are not resulting in collisions between rods or with the environment, physical constraints are introduced during the optimization. Real-world experiments are performed with a 3-bar tensegrity robot, which performs locomotion gaits. Given ground truth data from a motion capture system, the proposed method achieves less than 1 cm translation error and 3 degrees rotation error, which significantly outperforms alternatives. At the same time, the approach can provide pose estimates throughout the robot's motion, while motion capture often fails due to occlusions.
Online Object Model Reconstruction and Reuse for Lifelong Improvement of Robot Manipulation
Sep 28, 2021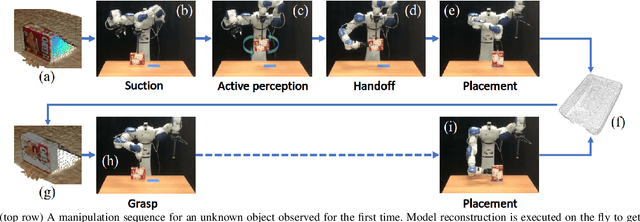
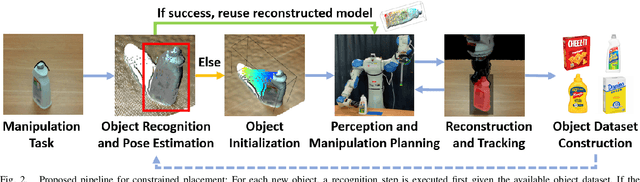
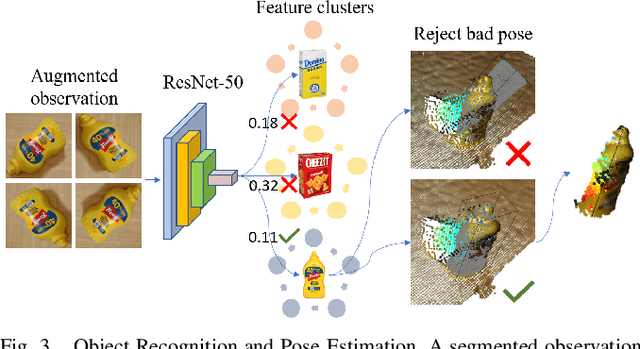
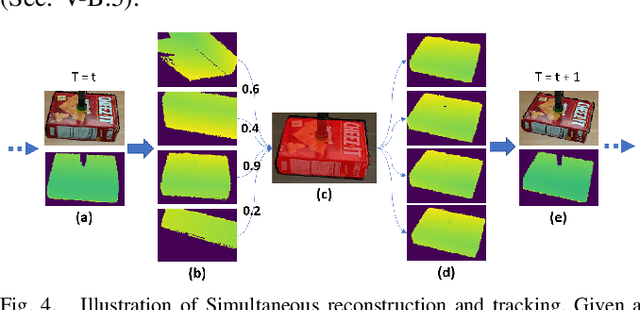
This work proposes a robotic pipeline for picking and constrained placement of objects without geometric shape priors. Compared to recent efforts developed for similar tasks, where every object was assumed to be novel, the proposed system recognizes previously manipulated objects and performs online model reconstruction and reuse. Over a lifelong manipulation process, the system keeps learning features of objects it has interacted with and updates their reconstructed models. Whenever an instance of a previously manipulated object reappears, the system aims to first recognize it and then register its previously reconstructed model given the current observation. This step greatly reduces object shape uncertainty allowing the system to even reason for parts of the objects that are currently not observable. This also results in better manipulation efficiency as it reduces the need for active perception of the target object during manipulation. To get a reusable reconstructed model, the proposed pipeline adopts i) TSDF for object representation, and ii) a variant of the standard particle filter algorithm for pose estimation and tracking of the partial object model. Furthermore, an effective way to construct and maintain a dataset of manipulated objects is presented. A sequence of real-world manipulation experiments is performed to show how future manipulation tasks become more effective and efficient by reusing reconstructed models of previously manipulated objects that were generated on the fly instead of treating objects as novel every time.
Safe and Effective Picking Paths in Clutter given Discrete Distributions of Object Poses
Aug 11, 2020
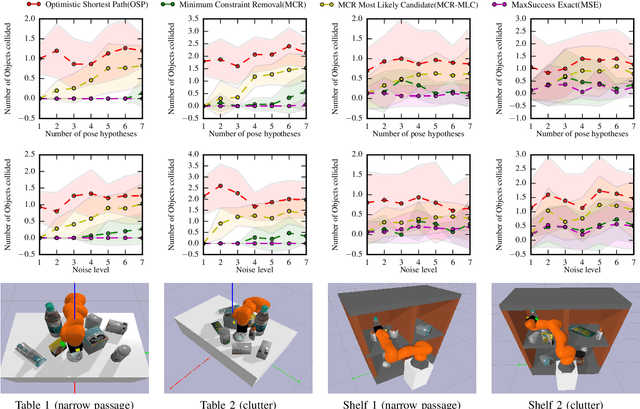
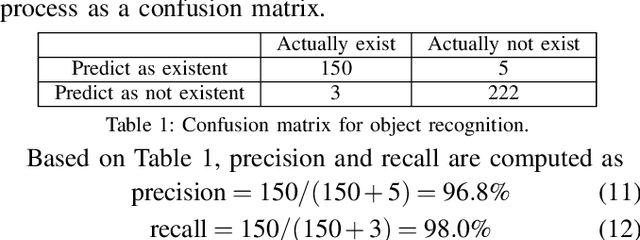
Picking an item in the presence of other objects can be challenging as it involves occlusions and partial views. Given object models, one approach is to perform object pose estimation and use the most likely candidate pose per object to pick the target without collisions. This approach, however, ignores the uncertainty of the perception process both regarding the target's and the surrounding objects' poses. This work proposes first a perception process for 6D pose estimation, which returns a discrete distribution of object poses in a scene. Then, an open-loop planning pipeline is proposed to return safe and effective solutions for moving a robotic arm to pick, which (a) minimizes the probability of collision with the obstructing objects; and (b) maximizes the probability of reaching the target item. The planning framework models the challenge as a stochastic variant of the Minimum Constraint Removal (MCR) problem. The effectiveness of the methodology is verified given both simulated and real data in different scenarios. The experiments demonstrate the importance of considering the uncertainty of the perception process in terms of safe execution. The results also show that the methodology is more effective than conservative MCR approaches, which avoid all possible object poses regardless of the reported uncertainty.
Factored Pose Estimation of Articulated Objects using Efficient Nonparametric Belief Propagation
Dec 10, 2018
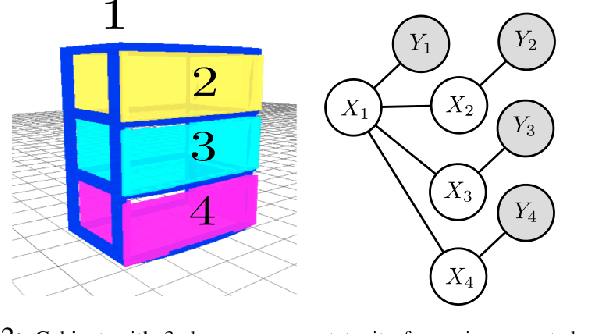

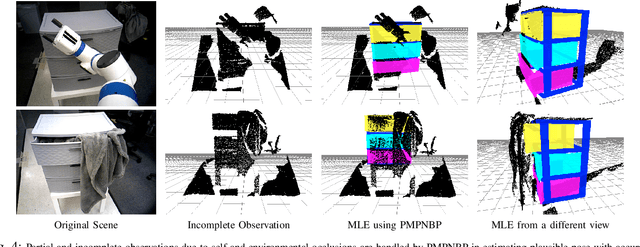
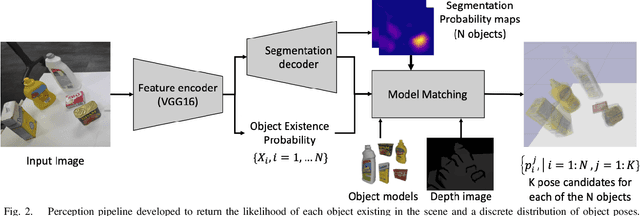
Robots working in human environments often encounter a wide range of articulated objects, such as tools, cabinets, and other jointed objects. Such articulated objects can take an infinite number of possible poses, as a point in a potentially high-dimensional continuous space. A robot must perceive this continuous pose to manipulate the object to a desired pose. This problem of perception and manipulation of articulated objects remains a challenge due to its high dimensionality and multi-modal uncertainty. In this paper, we propose a factored approach to estimate the poses of articulated objects using an efficient nonparametric belief propagation algorithm. We consider inputs as geometrical models with articulation constraints, and observed RGBD sensor data. The proposed framework produces object-part pose beliefs iteratively. The problem is formulated as a pairwise Markov Random Field (MRF) where each hidden node (continuous pose variable) is an observed object-part's pose and the edges denote the articulation constraints between the parts. We propose articulated pose estimation by Pull Message Passing algorithm for Nonparametric Belief Propagation (PMPNBP) and evaluate its convergence properties over scenes with articulated objects.