 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlove2Hand: Synthesizing Natural Hand-Object Interaction from Multi-Modal Sensing Gloves
Mar 21, 2026Understanding hand-object interaction (HOI) is fundamental to computer vision, robotics, and AR/VR. However, conventional hand videos often lack essential physical information such as contact forces and motion signals, and are prone to frequent occlusions. To address the challenges, we present Glove2Hand, a framework that translates multi-modal sensing glove HOI videos into photorealistic bare hands, while faithfully preserving the underlying physical interaction dynamics. We introduce a novel 3D Gaussian hand model that ensures temporal rendering consistency. The rendered hand is seamlessly integrated into the scene using a diffusion-based hand restorer, which effectively handles complex hand-object interactions and non-rigid deformations. Leveraging Glove2Hand, we create HandSense, the first multi-modal HOI dataset featuring glove-to-hand videos with synchronized tactile and IMU signals. We demonstrate that HandSense significantly enhances downstream bare-hand applications, including video-based contact estimation and hand tracking under severe occlusion.
Bounding Distributional Shifts in World Modeling through Novelty Detection
Aug 08, 2025Recent work on visual world models shows significant promise in latent state dynamics obtained from pre-trained image backbones. However, most of the current approaches are sensitive to training quality, requiring near-complete coverage of the action and state space during training to prevent divergence during inference. To make a model-based planning algorithm more robust to the quality of the learned world model, we propose in this work to use a variational autoencoder as a novelty detector to ensure that proposed action trajectories during planning do not cause the learned model to deviate from the training data distribution. To evaluate the effectiveness of this approach, a series of experiments in challenging simulated robot environments was carried out, with the proposed method incorporated into a model-predictive control policy loop extending the DINO-WM architecture. The results clearly show that the proposed method improves over state-of-the-art solutions in terms of data efficiency.
Failure Forecasting Boosts Robustness of Sim2Real Rhythmic Insertion Policies
Jul 09, 2025This paper addresses the challenges of Rhythmic Insertion Tasks (RIT), where a robot must repeatedly perform high-precision insertions, such as screwing a nut into a bolt with a wrench. The inherent difficulty of RIT lies in achieving millimeter-level accuracy and maintaining consistent performance over multiple repetitions, particularly when factors like nut rotation and friction introduce additional complexity. We propose a sim-to-real framework that integrates a reinforcement learning-based insertion policy with a failure forecasting module. By representing the wrench's pose in the nut's coordinate frame rather than the robot's frame, our approach significantly enhances sim-to-real transferability. The insertion policy, trained in simulation, leverages real-time 6D pose tracking to execute precise alignment, insertion, and rotation maneuvers. Simultaneously, a neural network predicts potential execution failures, triggering a simple recovery mechanism that lifts the wrench and retries the insertion. Extensive experiments in both simulated and real-world environments demonstrate that our method not only achieves a high one-time success rate but also robustly maintains performance over long-horizon repetitive tasks.
PROBE: Proprioceptive Obstacle Detection and Estimation while Navigating in Clutter
May 17, 2025In critical applications, including search-and-rescue in degraded environments, blockages can be prevalent and prevent the effective deployment of certain sensing modalities, particularly vision, due to occlusion and the constrained range of view of onboard camera sensors. To enable robots to tackle these challenges, we propose a new approach, Proprioceptive Obstacle Detection and Estimation while navigating in clutter PROBE, which instead relies only on the robot's proprioception to infer the presence or absence of occluded rectangular obstacles while predicting their dimensions and poses in SE(2). The proposed approach is a Transformer neural network that receives as input a history of applied torques and sensed whole-body movements of the robot and returns a parameterized representation of the obstacles in the environment. The effectiveness of PROBE is evaluated on simulated environments in Isaac Gym and with a real Unitree Go1 quadruped robot.
Integrating Model-based Control and RL for Sim2Real Transfer of Tight Insertion Policies
May 17, 2025Object insertion under tight tolerances ($< \hspace{-.02in} 1mm$) is an important but challenging assembly task as even small errors can result in undesirable contacts. Recent efforts focused on Reinforcement Learning (RL), which often depends on careful definition of dense reward functions. This work proposes an effective strategy for such tasks that integrates traditional model-based control with RL to achieve improved insertion accuracy. The policy is trained exclusively in simulation and is zero-shot transferred to the real system. It employs a potential field-based controller to acquire a model-based policy for inserting a plug into a socket given full observability in simulation. This policy is then integrated with residual RL, which is trained in simulation given only a sparse, goal-reaching reward. A curriculum scheme over observation noise and action magnitude is used for training the residual RL policy. Both policy components use as input the SE(3) poses of both the plug and the socket and return the plug's SE(3) pose transform, which is executed by a robotic arm using a controller. The integrated policy is deployed on the real system without further training or fine-tuning, given a visual SE(3) object tracker. The proposed solution and alternatives are evaluated across a variety of objects and conditions in simulation and reality. The proposed approach outperforms recent RL-based methods in this domain and prior efforts with hybrid policies. Ablations highlight the impact of each component of the approach.
Motion Blender Gaussian Splatting for Dynamic Reconstruction
Mar 12, 2025


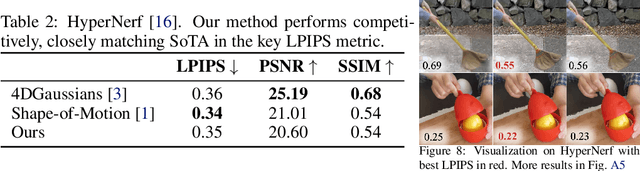
Gaussian splatting has emerged as a powerful tool for high-fidelity reconstruction of dynamic scenes. However, existing methods primarily rely on implicit motion representations, such as encoding motions into neural networks or per-Gaussian parameters, which makes it difficult to further manipulate the reconstructed motions. This lack of explicit controllability limits existing methods to replaying recorded motions only, which hinders a wider application. To address this, we propose Motion Blender Gaussian Splatting (MB-GS), a novel framework that uses motion graph as an explicit and sparse motion representation. The motion of graph links is propagated to individual Gaussians via dual quaternion skinning, with learnable weight painting functions determining the influence of each link. The motion graphs and 3D Gaussians are jointly optimized from input videos via differentiable rendering. Experiments show that MB-GS achieves state-of-the-art performance on the iPhone dataset while being competitive on HyperNeRF. Additionally, we demonstrate the application potential of our method in generating novel object motions and robot demonstrations through motion editing. Video demonstrations can be found at https://mlzxy.github.io/mbgs.
Autoregressive Action Sequence Learning for Robotic Manipulation
Oct 04, 2024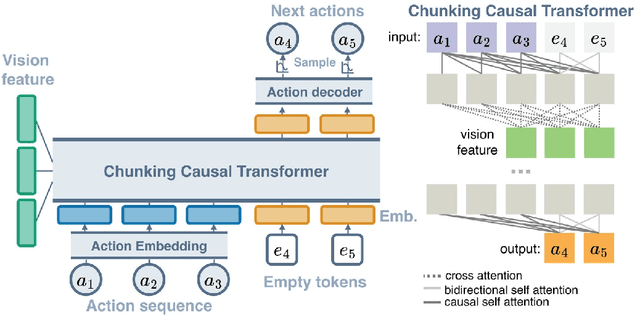



Autoregressive models have demonstrated remarkable success in natural language processing. In this work, we design a simple yet effective autoregressive architecture for robotic manipulation tasks. We propose the Chunking Causal Transformer (CCT), which extends the next-single-token prediction of causal transformers to support multi-token prediction in a single pass. Further, we design a novel attention interleaving strategy that allows CCT to be trained efficiently with teacher-forcing. Based on CCT, we propose the Autoregressive Policy (ARP) model, which learns to generate action sequences autoregressively. We find that action sequence learning enables better leverage of the underlying causal relationships in robotic tasks. We evaluate ARP across diverse robotic manipulation environments, including Push-T, ALOHA, and RLBench, and show that it outperforms the state-of-the-art methods in all tested environments, while being more efficient in computation and parameter sizes. Video demonstrations, our source code, and the models of ARP can be found at http://github.com/mlzxy/arp.
DAP: Diffusion-based Affordance Prediction for Multi-modality Storage
Aug 31, 2024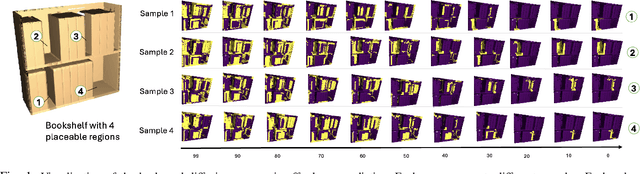
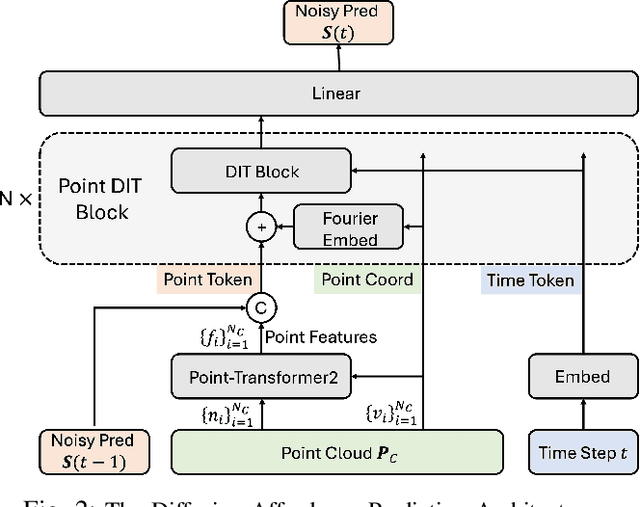
Solving storage problem: where objects must be accurately placed into containers with precise orientations and positions, presents a distinct challenge that extends beyond traditional rearrangement tasks. These challenges are primarily due to the need for fine-grained 6D manipulation and the inherent multi-modality of solution spaces, where multiple viable goal configurations exist for the same storage container. We present a novel Diffusion-based Affordance Prediction (DAP) pipeline for the multi-modal object storage problem. DAP leverages a two-step approach, initially identifying a placeable region on the container and then precisely computing the relative pose between the object and that region. Existing methods either struggle with multi-modality issues or computation-intensive training. Our experiments demonstrate DAP's superior performance and training efficiency over the current state-of-the-art RPDiff, achieving remarkable results on the RPDiff benchmark. Additionally, our experiments showcase DAP's data efficiency in real-world applications, an advancement over existing simulation-driven approaches. Our contribution fills a gap in robotic manipulation research by offering a solution that is both computationally efficient and capable of handling real-world variability. Code and supplementary material can be found at: https://github.com/changhaonan/DPS.git.
Bellman Diffusion Models
Jul 16, 2024Diffusion models have seen tremendous success as generative architectures. Recently, they have been shown to be effective at modelling policies for offline reinforcement learning and imitation learning. We explore using diffusion as a model class for the successor state measure (SSM) of a policy. We find that enforcing the Bellman flow constraints leads to a simple Bellman update on the diffusion step distribution.
Provably Efficient Long-Horizon Exploration in Monte Carlo Tree Search through State Occupancy Regularization
Jul 07, 2024



Monte Carlo tree search (MCTS) has been successful in a variety of domains, but faces challenges with long-horizon exploration when compared to sampling-based motion planning algorithms like Rapidly-Exploring Random Trees. To address these limitations of MCTS, we derive a tree search algorithm based on policy optimization with state occupancy measure regularization, which we call {\it Volume-MCTS}. We show that count-based exploration and sampling-based motion planning can be derived as approximate solutions to this state occupancy measure regularized objective. We test our method on several robot navigation problems, and find that Volume-MCTS outperforms AlphaZero and displays significantly better long-horizon exploration properties.