 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailure Forecasting Boosts Robustness of Sim2Real Rhythmic Insertion Policies
Jul 09, 2025This paper addresses the challenges of Rhythmic Insertion Tasks (RIT), where a robot must repeatedly perform high-precision insertions, such as screwing a nut into a bolt with a wrench. The inherent difficulty of RIT lies in achieving millimeter-level accuracy and maintaining consistent performance over multiple repetitions, particularly when factors like nut rotation and friction introduce additional complexity. We propose a sim-to-real framework that integrates a reinforcement learning-based insertion policy with a failure forecasting module. By representing the wrench's pose in the nut's coordinate frame rather than the robot's frame, our approach significantly enhances sim-to-real transferability. The insertion policy, trained in simulation, leverages real-time 6D pose tracking to execute precise alignment, insertion, and rotation maneuvers. Simultaneously, a neural network predicts potential execution failures, triggering a simple recovery mechanism that lifts the wrench and retries the insertion. Extensive experiments in both simulated and real-world environments demonstrate that our method not only achieves a high one-time success rate but also robustly maintains performance over long-horizon repetitive tasks.
Motion Blender Gaussian Splatting for Dynamic Reconstruction
Mar 12, 2025


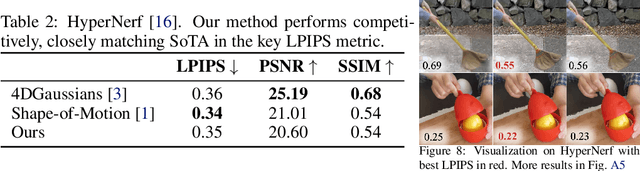
Gaussian splatting has emerged as a powerful tool for high-fidelity reconstruction of dynamic scenes. However, existing methods primarily rely on implicit motion representations, such as encoding motions into neural networks or per-Gaussian parameters, which makes it difficult to further manipulate the reconstructed motions. This lack of explicit controllability limits existing methods to replaying recorded motions only, which hinders a wider application. To address this, we propose Motion Blender Gaussian Splatting (MB-GS), a novel framework that uses motion graph as an explicit and sparse motion representation. The motion of graph links is propagated to individual Gaussians via dual quaternion skinning, with learnable weight painting functions determining the influence of each link. The motion graphs and 3D Gaussians are jointly optimized from input videos via differentiable rendering. Experiments show that MB-GS achieves state-of-the-art performance on the iPhone dataset while being competitive on HyperNeRF. Additionally, we demonstrate the application potential of our method in generating novel object motions and robot demonstrations through motion editing. Video demonstrations can be found at https://mlzxy.github.io/mbgs.
Autoregressive Action Sequence Learning for Robotic Manipulation
Oct 04, 2024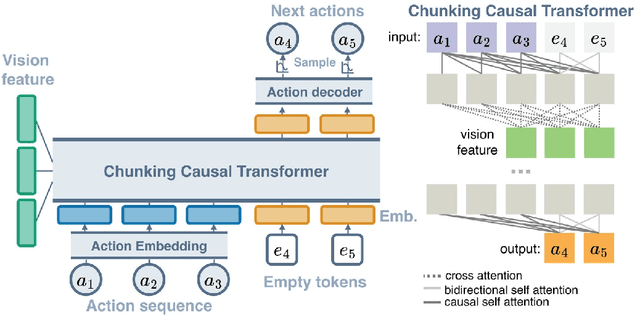



Autoregressive models have demonstrated remarkable success in natural language processing. In this work, we design a simple yet effective autoregressive architecture for robotic manipulation tasks. We propose the Chunking Causal Transformer (CCT), which extends the next-single-token prediction of causal transformers to support multi-token prediction in a single pass. Further, we design a novel attention interleaving strategy that allows CCT to be trained efficiently with teacher-forcing. Based on CCT, we propose the Autoregressive Policy (ARP) model, which learns to generate action sequences autoregressively. We find that action sequence learning enables better leverage of the underlying causal relationships in robotic tasks. We evaluate ARP across diverse robotic manipulation environments, including Push-T, ALOHA, and RLBench, and show that it outperforms the state-of-the-art methods in all tested environments, while being more efficient in computation and parameter sizes. Video demonstrations, our source code, and the models of ARP can be found at http://github.com/mlzxy/arp.
UniAff: A Unified Representation of Affordances for Tool Usage and Articulation with Vision-Language Models
Sep 30, 2024



Previous studies on robotic manipulation are based on a limited understanding of the underlying 3D motion constraints and affordances. To address these challenges, we propose a comprehensive paradigm, termed UniAff, that integrates 3D object-centric manipulation and task understanding in a unified formulation. Specifically, we constructed a dataset labeled with manipulation-related key attributes, comprising 900 articulated objects from 19 categories and 600 tools from 12 categories. Furthermore, we leverage MLLMs to infer object-centric representations for manipulation tasks, including affordance recognition and reasoning about 3D motion constraints. Comprehensive experiments in both simulation and real-world settings indicate that UniAff significantly improves the generalization of robotic manipulation for tools and articulated objects. We hope that UniAff will serve as a general baseline for unified robotic manipulation tasks in the future. Images, videos, dataset, and code are published on the project website at:https://sites.google.com/view/uni-aff/home
DAP: Diffusion-based Affordance Prediction for Multi-modality Storage
Aug 31, 2024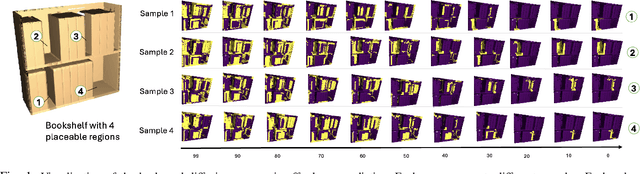
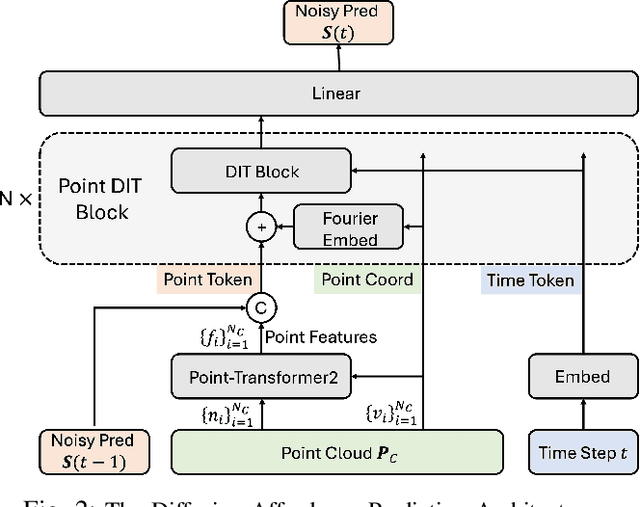
Solving storage problem: where objects must be accurately placed into containers with precise orientations and positions, presents a distinct challenge that extends beyond traditional rearrangement tasks. These challenges are primarily due to the need for fine-grained 6D manipulation and the inherent multi-modality of solution spaces, where multiple viable goal configurations exist for the same storage container. We present a novel Diffusion-based Affordance Prediction (DAP) pipeline for the multi-modal object storage problem. DAP leverages a two-step approach, initially identifying a placeable region on the container and then precisely computing the relative pose between the object and that region. Existing methods either struggle with multi-modality issues or computation-intensive training. Our experiments demonstrate DAP's superior performance and training efficiency over the current state-of-the-art RPDiff, achieving remarkable results on the RPDiff benchmark. Additionally, our experiments showcase DAP's data efficiency in real-world applications, an advancement over existing simulation-driven approaches. Our contribution fills a gap in robotic manipulation research by offering a solution that is both computationally efficient and capable of handling real-world variability. Code and supplementary material can be found at: https://github.com/changhaonan/DPS.git.
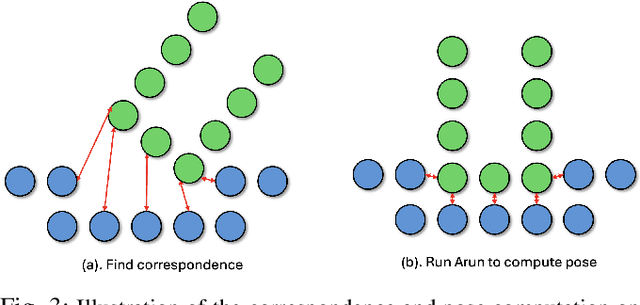
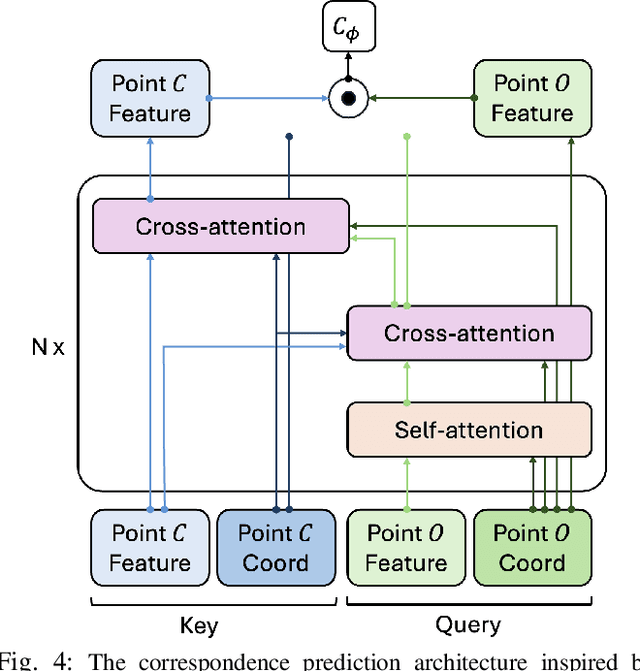
Scaling Manipulation Learning with Visual Kinematic Chain Prediction
Jun 12, 2024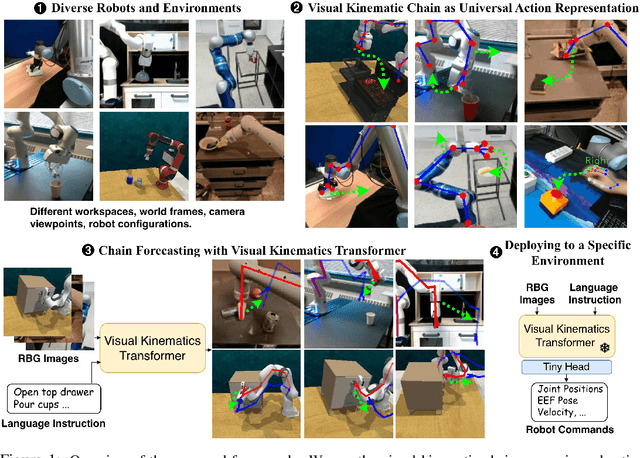

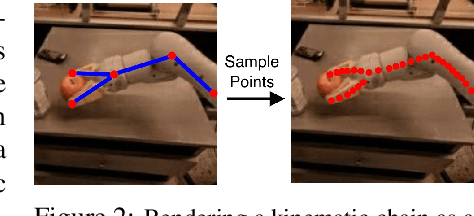
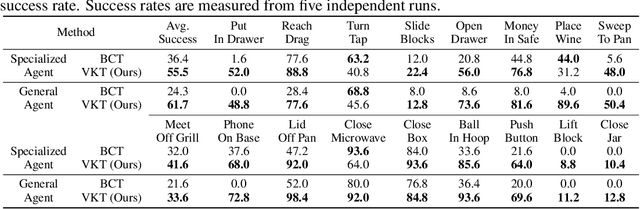
Learning general-purpose models from diverse datasets has achieved great success in machine learning. In robotics, however, existing methods in multi-task learning are typically constrained to a single robot and workspace, while recent work such as RT-X requires a non-trivial action normalization procedure to manually bridge the gap between different action spaces in diverse environments. In this paper, we propose the visual kinematics chain as a precise and universal representation of quasi-static actions for robot learning over diverse environments, which requires no manual adjustment since the visual kinematic chains can be automatically obtained from the robot's model and camera parameters. We propose the Visual Kinematics Transformer (VKT), a convolution-free architecture that supports an arbitrary number of camera viewpoints, and that is trained with a single objective of forecasting kinematic structures through optimal point-set matching. We demonstrate the superior performance of VKT over BC transformers as a general agent on Calvin, RLBench, Open-X, and real robot manipulation tasks. Video demonstrations can be found at https://mlzxy.github.io/visual-kinetic-chain.
A3VLM: Actionable Articulation-Aware Vision Language Model
Jun 11, 2024Vision Language Models (VLMs) have received significant attention in recent years in the robotics community. VLMs are shown to be able to perform complex visual reasoning and scene understanding tasks, which makes them regarded as a potential universal solution for general robotics problems such as manipulation and navigation. However, previous VLMs for robotics such as RT-1, RT-2, and ManipLLM~ have focused on directly learning robot-centric actions. Such approaches require collecting a significant amount of robot interaction data, which is extremely costly in the real world. Thus, we propose A3VLM, an object-centric, actionable, articulation-aware vision language model. A3VLM focuses on the articulation structure and action affordances of objects. Its representation is robot-agnostic and can be translated into robot actions using simple action primitives. Extensive experiments in both simulation benchmarks and real-world settings demonstrate the effectiveness and stability of A3VLM. We release our code and other materials at https://github.com/changhaonan/A3VLM.
OVIR-3D: Open-Vocabulary 3D Instance Retrieval Without Training on 3D Data
Nov 06, 2023

This work presents OVIR-3D, a straightforward yet effective method for open-vocabulary 3D object instance retrieval without using any 3D data for training. Given a language query, the proposed method is able to return a ranked set of 3D object instance segments based on the feature similarity of the instance and the text query. This is achieved by a multi-view fusion of text-aligned 2D region proposals into 3D space, where the 2D region proposal network could leverage 2D datasets, which are more accessible and typically larger than 3D datasets. The proposed fusion process is efficient as it can be performed in real-time for most indoor 3D scenes and does not require additional training in 3D space. Experiments on public datasets and a real robot show the effectiveness of the method and its potential for applications in robot navigation and manipulation.
Context-Aware Entity Grounding with Open-Vocabulary 3D Scene Graphs
Sep 27, 2023



We present an Open-Vocabulary 3D Scene Graph (OVSG), a formal framework for grounding a variety of entities, such as object instances, agents, and regions, with free-form text-based queries. Unlike conventional semantic-based object localization approaches, our system facilitates context-aware entity localization, allowing for queries such as ``pick up a cup on a kitchen table" or ``navigate to a sofa on which someone is sitting". In contrast to existing research on 3D scene graphs, OVSG supports free-form text input and open-vocabulary querying. Through a series of comparative experiments using the ScanNet dataset and a self-collected dataset, we demonstrate that our proposed approach significantly surpasses the performance of previous semantic-based localization techniques. Moreover, we highlight the practical application of OVSG in real-world robot navigation and manipulation experiments.
LGMCTS: Language-Guided Monte-Carlo Tree Search for Executable Semantic Object Rearrangement
Sep 27, 2023
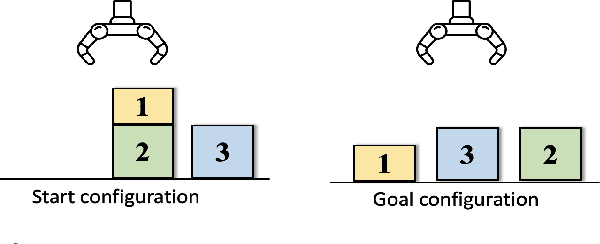

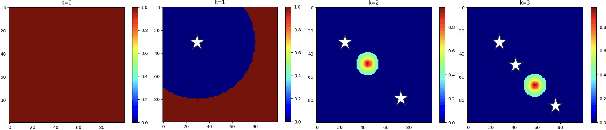
We introduce a novel approach to the executable semantic object rearrangement problem. In this challenge, a robot seeks to create an actionable plan that rearranges objects within a scene according to a pattern dictated by a natural language description. Unlike existing methods such as StructFormer and StructDiffusion, which tackle the issue in two steps by first generating poses and then leveraging a task planner for action plan formulation, our method concurrently addresses pose generation and action planning. We achieve this integration using a Language-Guided Monte-Carlo Tree Search (LGMCTS). Quantitative evaluations are provided on two simulation datasets, and complemented by qualitative tests with a real robot.