 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThreading Optimization for Vision-Language-Action Model Inference in Low-Cost Smart Agricultural Manipulation
May 31, 2026Vision-Language Action (VLA) models continue to face challenges such as slow inference speed and difficulty performing fine-grained motion adjustments, limiting their widespread adoption in industry. While the Real-Time Action Chunking (RTAC) algorithm has been proposed to address these bottlenecks, bridging the gap between the algorithm provided in pseudocode to a stable, real-world deployment on a low-cost robotic arm remains a challenge. In this work, we present a complete system-level implementation of RTAC tailored for a low-cost robotic manipulation system. We advance beyond the original high-level pseudocode by optimizing the threading implementation for the policy inference and control pipeline, reducing end-to-end latency and improving responsiveness without modifying the underlying policy. We evaluate this system on tasks involving the manipulation of agricultural produce, specifically garlic bulbs and walnuts. Experimental results demonstrate that our custom threading implementation significantly improves control stability and speed compared to the base implementation of RTAC.
GA3T: A Ground-Aerial Terrain Traversability Dataset for Heterogeneous Robot Teams in Unstructured Environments
May 07, 2026Heterogeneous air-ground robot teams combine complementary sensing modalities, mobility characteristics, and spatial viewpoints that can significantly enhance perception in complex outdoor environments. However, progress in multi-robot collaborative perception has been constrained by the lack of real-world datasets featuring overlapping multi-modal observations from platforms operating in unstructured terrain. We present GA3T (Ground-Aerial Team for Terrain Traversal), a real-world multi-robot collaborative perception dataset collected using a Clearpath Husky UGV and an Autel EVO~II UAV across diverse unstructured environments, including forest trails, rocky paths, muddy terrain, snow piles, and grass-covered fields. The ground platform provides 3D LiDAR, stereo camera, IMU, and GPS data, while the aerial platform contributes RGB imagery, thermal/infrared observations, and GPS from a complementary overhead viewpoint, allowing for rich cross-modal and cross-view perception. The dataset is collected in 4 unique environments, with over 13,000 synchronized frames across approximately 29 minutes of operation, and includes both SAM~3-based zero-shot segmentation and over 8,000 manually labeled images. A unique aspect of the dataset is its early-spring collection period, during which sparse tree canopies allow the aerial robot to partially observe the ground robot and terrain through the trees, allowing for occlusion-aware collaborative perception. Unlike prior multi-robot datasets that focus on SLAM or simulated cooperative driving, GA3T is specifically designed to support research on cross-view perception, air-ground viewpoint fusion, traversability estimation, and collaborative scene understanding in real off-road environments.
LLM-Land: Large Language Models for Context-Aware Drone Landing
May 09, 2025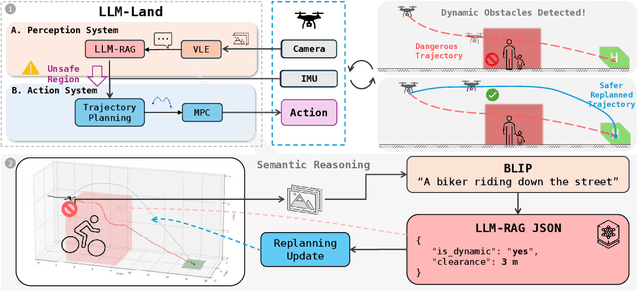


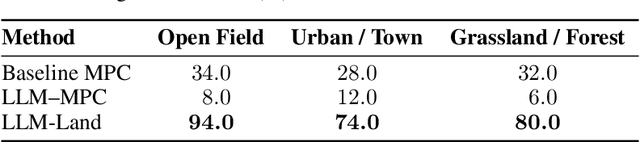
Autonomous landing is essential for drones deployed in emergency deliveries, post-disaster response, and other large-scale missions. By enabling self-docking on charging platforms, it facilitates continuous operation and significantly extends mission endurance. However, traditional approaches often fall short in dynamic, unstructured environments due to limited semantic awareness and reliance on fixed, context-insensitive safety margins. To address these limitations, we propose a hybrid framework that integrates large language model (LLMs) with model predictive control (MPC). Our approach begins with a vision-language encoder (VLE) (e.g., BLIP), which transforms real-time images into concise textual scene descriptions. These descriptions are processed by a lightweight LLM (e.g., Qwen 2.5 1.5B or LLaMA 3.2 1B) equipped with retrieval-augmented generation (RAG) to classify scene elements and infer context-aware safety buffers, such as 3 meters for pedestrians and 5 meters for vehicles. The resulting semantic flags and unsafe regions are then fed into an MPC module, enabling real-time trajectory replanning that avoids collisions while maintaining high landing precision. We validate our framework in the ROS-Gazebo simulator, where it consistently outperforms conventional vision-based MPC baselines. Our results show a significant reduction in near-miss incidents with dynamic obstacles, while preserving accurate landings in cluttered environments.
Context-Aware Entity Grounding with Open-Vocabulary 3D Scene Graphs
Sep 27, 2023



We present an Open-Vocabulary 3D Scene Graph (OVSG), a formal framework for grounding a variety of entities, such as object instances, agents, and regions, with free-form text-based queries. Unlike conventional semantic-based object localization approaches, our system facilitates context-aware entity localization, allowing for queries such as ``pick up a cup on a kitchen table" or ``navigate to a sofa on which someone is sitting". In contrast to existing research on 3D scene graphs, OVSG supports free-form text input and open-vocabulary querying. Through a series of comparative experiments using the ScanNet dataset and a self-collected dataset, we demonstrate that our proposed approach significantly surpasses the performance of previous semantic-based localization techniques. Moreover, we highlight the practical application of OVSG in real-world robot navigation and manipulation experiments.