 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThreading Optimization for Vision-Language-Action Model Inference in Low-Cost Smart Agricultural Manipulation
May 31, 2026Vision-Language Action (VLA) models continue to face challenges such as slow inference speed and difficulty performing fine-grained motion adjustments, limiting their widespread adoption in industry. While the Real-Time Action Chunking (RTAC) algorithm has been proposed to address these bottlenecks, bridging the gap between the algorithm provided in pseudocode to a stable, real-world deployment on a low-cost robotic arm remains a challenge. In this work, we present a complete system-level implementation of RTAC tailored for a low-cost robotic manipulation system. We advance beyond the original high-level pseudocode by optimizing the threading implementation for the policy inference and control pipeline, reducing end-to-end latency and improving responsiveness without modifying the underlying policy. We evaluate this system on tasks involving the manipulation of agricultural produce, specifically garlic bulbs and walnuts. Experimental results demonstrate that our custom threading implementation significantly improves control stability and speed compared to the base implementation of RTAC.
ROG-Grasp: Root-Oriented Geometry for Robotic Grasping and Placement
May 30, 2026Orientation-aware manipulation is essential in post-harvest agricultural processing, where produce must be grasped and placed in consistent configurations. This paper presents ROG-Grasp, a geometry-based robotic grasping and placement framework that estimates the produce orientation from root surface geometry using RGB-D perception. A YOLO-based root detector and point cloud plane fitting are used to infer the root normal, enabling stable grasp pose generation and orientation-constrained Cartesian motion planning. Experiments on tomatoes and onions demonstrate high success rates and stable execution time in both isolated and cluttered scenarios. Compared with vision-language-action (VLA) policies, the proposed method achieves more reliable and accurate grasp completion with faster execution. These results highlight the effectiveness of geometry-driven perception for practical orientation-controlled manipulation tasks. A video of our paper is available online https://youtu.be/Ir2UtGODdMo.
GA3T: A Ground-Aerial Terrain Traversability Dataset for Heterogeneous Robot Teams in Unstructured Environments
May 07, 2026Heterogeneous air-ground robot teams combine complementary sensing modalities, mobility characteristics, and spatial viewpoints that can significantly enhance perception in complex outdoor environments. However, progress in multi-robot collaborative perception has been constrained by the lack of real-world datasets featuring overlapping multi-modal observations from platforms operating in unstructured terrain. We present GA3T (Ground-Aerial Team for Terrain Traversal), a real-world multi-robot collaborative perception dataset collected using a Clearpath Husky UGV and an Autel EVO~II UAV across diverse unstructured environments, including forest trails, rocky paths, muddy terrain, snow piles, and grass-covered fields. The ground platform provides 3D LiDAR, stereo camera, IMU, and GPS data, while the aerial platform contributes RGB imagery, thermal/infrared observations, and GPS from a complementary overhead viewpoint, allowing for rich cross-modal and cross-view perception. The dataset is collected in 4 unique environments, with over 13,000 synchronized frames across approximately 29 minutes of operation, and includes both SAM~3-based zero-shot segmentation and over 8,000 manually labeled images. A unique aspect of the dataset is its early-spring collection period, during which sparse tree canopies allow the aerial robot to partially observe the ground robot and terrain through the trees, allowing for occlusion-aware collaborative perception. Unlike prior multi-robot datasets that focus on SLAM or simulated cooperative driving, GA3T is specifically designed to support research on cross-view perception, air-ground viewpoint fusion, traversability estimation, and collaborative scene understanding in real off-road environments.
VILAS: A VLA-Integrated Low-cost Architecture with Soft Grasping for Robotic Manipulation
May 03, 2026We present VILAS, a fully low-cost, modular robotic manipulation platform designed to support end-to-end vision-language-action (VLA) policy learning and deployment on accessible hardware. The system integrates a Fairino FR5 collaborative arm, a Jodell RG52-50 electric gripper, and a dual-camera perception module, unified through a ZMQ-based communication architecture that seamlessly coordinates teleoperation, data collection, and policy deployment within a single framework. To enable safe manipulation of fragile objects without relying on explicit force sensing, we design a kirigami-based soft compliant gripper extension that induces predictable deformation under compressive loading, providing gentle and repeatable contact with delicate targets. We deploy and evaluate three state-of-the-art VLA models on the VILAS platform: pi_0, pi_0.5, and GR00T N1.6. All models are fine-tuned from publicly released pretrained checkpoints using an identical demonstration dataset collected via our teleoperation pipeline. Experiments on a grape grasping task validate the effectiveness of the proposed system, confirming that capable manipulation policies can be successfully trained and deployed on low-cost modular hardware. Our results further provide practical insights into the deployment characteristics of current VLA models in real-world settings.
Policy-Guided World Model Planning for Language-Conditioned Visual Navigation
Mar 26, 2026Navigating to a visually specified goal given natural language instructions remains a fundamental challenge in embodied AI. Existing approaches either rely on reactive policies that struggle with long-horizon planning, or employ world models that suffer from poor action initialization in high-dimensional spaces. We present PiJEPA, a two-stage framework that combines the strengths of learned navigation policies with latent world model planning for instruction-conditioned visual navigation. In the first stage, we finetune an Octo-based generalist policy, augmented with a frozen pretrained vision encoder (DINOv2 or V-JEPA-2), on the CAST navigation dataset to produce an informed action distribution conditioned on the current observation and language instruction. In the second stage, we use this policy-derived distribution to warm-start Model Predictive Path Integral (MPPI) planning over a separately trained JEPA world model, which predicts future latent states in the embedding space of the same frozen encoder. By initializing the MPPI sampling distribution from the policy prior rather than from an uninformed Gaussian, our planner converges faster to high-quality action sequences that reach the goal. We systematically study the effect of the vision encoder backbone, comparing DINOv2 and V-JEPA-2, across both the policy and world model components. Experiments on real-world navigation tasks demonstrate that PiJEPA significantly outperforms both standalone policy execution and uninformed world model planning, achieving improved goal-reaching accuracy and instruction-following fidelity.
IDSelect: A RL-Based Cost-Aware Selection Agent for Video-based Multi-Modal Person Recognition
Feb 22, 2026Video-based person recognition achieves robust identification by integrating face, body, and gait. However, current systems waste computational resources by processing all modalities with fixed heavyweight ensembles regardless of input complexity. To address these limitations, we propose IDSelect, a reinforcement learning-based cost-aware selector that chooses one pre-trained model per modality per-sequence to optimize the accuracy-efficiency trade-off. Our key insight is that an input-conditioned selector can discover complementary model choices that surpass fixed ensembles while using substantially fewer resources. IDSelect trains a lightweight agent end-to-end using actor-critic reinforcement learning with budget-aware optimization. The reward balances recognition accuracy with computational cost, while entropy regularization prevents premature convergence. At inference, the policy selects the most probable model per modality and fuses modality-specific similarities for the final score. Extensive experiments on challenging video-based datasets demonstrate IDSelect's superior efficiency: on CCVID, it achieves 95.9% Rank-1 accuracy with 92.4% less computation than strong baselines while improving accuracy by 1.8%; on MEVID, it reduces computation by 41.3% while maintaining competitive performance.
CLAW: A Vision-Language-Action Framework for Weight-Aware Robotic Grasping
Sep 17, 2025Vision-language-action (VLA) models have recently emerged as a promising paradigm for robotic control, enabling end-to-end policies that ground natural language instructions into visuomotor actions. However, current VLAs often struggle to satisfy precise task constraints, such as stopping based on numeric thresholds, since their observation-to-action mappings are implicitly shaped by training data and lack explicit mechanisms for condition monitoring. In this work, we propose CLAW (CLIP-Language-Action for Weight), a framework that decouples condition evaluation from action generation. CLAW leverages a fine-tuned CLIP model as a lightweight prompt generator, which continuously monitors the digital readout of a scale and produces discrete directives based on task-specific weight thresholds. These prompts are then consumed by $\pi_0$, a flow-based VLA policy, which integrates the prompts with multi-view camera observations to produce continuous robot actions. This design enables CLAW to combine symbolic weight reasoning with high-frequency visuomotor control. We validate CLAW on three experimental setups: single-object grasping and mixed-object tasks requiring dual-arm manipulation. Across all conditions, CLAW reliably executes weight-aware behaviors and outperforms both raw-$\pi_0$ and fine-tuned $\pi_0$ models. We have uploaded the videos as supplementary materials.
LLM-Flock: Decentralized Multi-Robot Flocking via Large Language Models and Influence-Based Consensus
May 10, 2025Large Language Models (LLMs) have advanced rapidly in recent years, demonstrating strong capabilities in problem comprehension and reasoning. Inspired by these developments, researchers have begun exploring the use of LLMs as decentralized decision-makers for multi-robot formation control. However, prior studies reveal that directly applying LLMs to such tasks often leads to unstable and inconsistent behaviors, where robots may collapse to the centroid of their positions or diverge entirely due to hallucinated reasoning, logical inconsistencies, and limited coordination awareness. To overcome these limitations, we propose a novel framework that integrates LLMs with an influence-based plan consensus protocol. In this framework, each robot independently generates a local plan toward the desired formation using its own LLM. The robots then iteratively refine their plans through a decentralized consensus protocol that accounts for their influence on neighboring robots. This process drives the system toward a coherent and stable flocking formation in a fully decentralized manner. We evaluate our approach through comprehensive simulations involving both state-of-the-art closed-source LLMs (e.g., o3-mini, Claude 3.5) and open-source models (e.g., Llama3.1-405b, Qwen-Max, DeepSeek-R1). The results show notable improvements in stability, convergence, and adaptability over previous LLM-based methods. We further validate our framework on a physical team of Crazyflie drones, demonstrating its practical viability and effectiveness in real-world multi-robot systems.
LLM-Land: Large Language Models for Context-Aware Drone Landing
May 09, 2025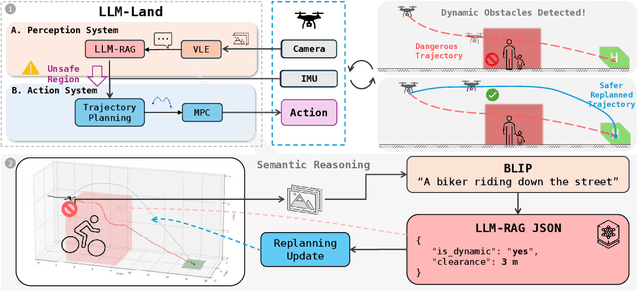


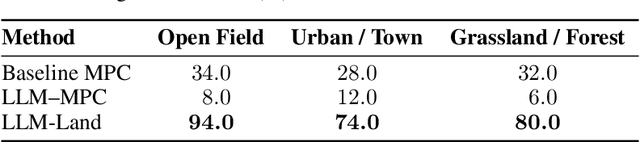
Autonomous landing is essential for drones deployed in emergency deliveries, post-disaster response, and other large-scale missions. By enabling self-docking on charging platforms, it facilitates continuous operation and significantly extends mission endurance. However, traditional approaches often fall short in dynamic, unstructured environments due to limited semantic awareness and reliance on fixed, context-insensitive safety margins. To address these limitations, we propose a hybrid framework that integrates large language model (LLMs) with model predictive control (MPC). Our approach begins with a vision-language encoder (VLE) (e.g., BLIP), which transforms real-time images into concise textual scene descriptions. These descriptions are processed by a lightweight LLM (e.g., Qwen 2.5 1.5B or LLaMA 3.2 1B) equipped with retrieval-augmented generation (RAG) to classify scene elements and infer context-aware safety buffers, such as 3 meters for pedestrians and 5 meters for vehicles. The resulting semantic flags and unsafe regions are then fed into an MPC module, enabling real-time trajectory replanning that avoids collisions while maintaining high landing precision. We validate our framework in the ROS-Gazebo simulator, where it consistently outperforms conventional vision-based MPC baselines. Our results show a significant reduction in near-miss incidents with dynamic obstacles, while preserving accurate landings in cluttered environments.
Reinforcement Learning for Game-Theoretic Resource Allocation on Graphs
May 08, 2025Game-theoretic resource allocation on graphs (GRAG) involves two players competing over multiple steps to control nodes of interest on a graph, a problem modeled as a multi-step Colonel Blotto Game (MCBG). Finding optimal strategies is challenging due to the dynamic action space and structural constraints imposed by the graph. To address this, we formulate the MCBG as a Markov Decision Process (MDP) and apply Reinforcement Learning (RL) methods, specifically Deep Q-Network (DQN) and Proximal Policy Optimization (PPO). To enforce graph constraints, we introduce an action-displacement adjacency matrix that dynamically generates valid action sets at each step. We evaluate RL performance across a variety of graph structures and initial resource distributions, comparing against random, greedy, and learned RL policies. Experimental results show that both DQN and PPO consistently outperform baseline strategies and converge to a balanced $50\%$ win rate when competing against the learned RL policy. Particularly, on asymmetric graphs, RL agents successfully exploit structural advantages and adapt their allocation strategies, even under disadvantageous initial resource distributions.