 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundus-R1: Training a Fundus-Reading MLLM with Knowledge-Aware Reasoning on Public Data
Apr 09, 2026Fundus imaging such as CFP, OCT and UWF is crucial for the early detection of retinal anomalies and diseases. Fundus image understanding, due to its knowledge-intensive nature, poses a challenging vision-language task. An emerging approach to addressing the task is to post-train a generic multimodal large language model (MLLM), either by supervised finetuning (SFT) or by reinforcement learning with verifiable rewards (RLVR), on a considerable amount of in-house samples paired with high-quality clinical reports. However, these valuable samples are not publicly accessible, which not only hinders reproducibility but also practically limits research to few players. To overcome the barrier, we make a novel attempt to train a reasoning-enhanced fundus-reading MLLM, which we term Fundus-R1, using exclusively public datasets, wherein over 94\% of the data are annotated with only image-level labels. Our technical contributions are two-fold. First, we propose a RAG-based method for composing image-specific, knowledge-aware reasoning traces. Such auto-generated traces link visual findings identified by a generic MLLM to the image labels in terms of ophthalmic knowledge. Second, we enhance RLVR with a process reward that encourages self-consistency of the generated reasoning trace in each rollout. Extensive experiments on three fundus-reading benchmarks, i.e., FunBench, Omni-Fundus and GMAI-Fundus, show that Fundus-R1 clearly outperforms multiple baselines, including its generic counterpart (Qwen2.5-VL) and a stronger edition post-trained without using the generated traces. This work paves the way for training powerful fundus-reading MLLMs with publicly available data.
Learning and Optimizing the Efficacy of Spatio-Temporal Task Allocation under Temporal and Resource Constraints
Jan 05, 2026Complex multi-robot missions often require heterogeneous teams to jointly optimize task allocation, scheduling, and path planning to improve team performance under strict constraints. We formalize these complexities into a new class of problems, dubbed Spatio-Temporal Efficacy-optimized Allocation for Multi-robot systems (STEAM). STEAM builds upon trait-based frameworks that model robots using their capabilities (e.g., payload and speed), but goes beyond the typical binary success-failure model by explicitly modeling the efficacy of allocations as trait-efficacy maps. These maps encode how the aggregated capabilities assigned to a task determine performance. Further, STEAM accommodates spatio-temporal constraints, including a user-specified time budget (i.e., maximum makespan). To solve STEAM problems, we contribute a novel algorithm named Efficacy-optimized Incremental Task Allocation Graph Search (E-ITAGS) that simultaneously optimizes task performance and respects time budgets by interleaving task allocation, scheduling, and path planning. Motivated by the fact that trait-efficacy maps are difficult, if not impossible, to specify, E-ITAGS efficiently learns them using a realizability-aware active learning module. Our approach is realizability-aware since it explicitly accounts for the fact that not all combinations of traits are realizable by the robots available during learning. Further, we derive experimentally-validated bounds on E-ITAGS' suboptimality with respect to efficacy. Detailed numerical simulations and experiments using an emergency response domain demonstrate that E-ITAGS generates allocations of higher efficacy compared to baselines, while respecting resource and spatio-temporal constraints. We also show that our active learning approach is sample efficient and establishes a principled tradeoff between data and computational efficiency.
JaxRobotarium: Training and Deploying Multi-Robot Policies in 10 Minutes
May 10, 2025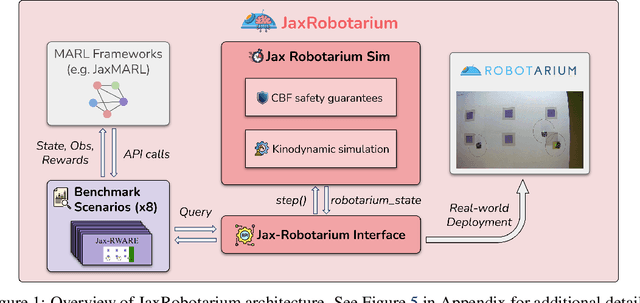
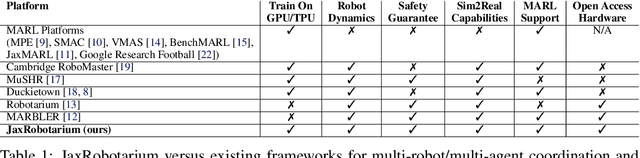
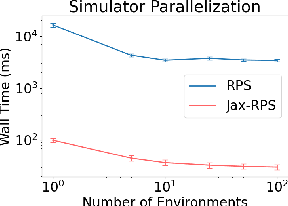

Multi-agent reinforcement learning (MARL) has emerged as a promising solution for learning complex and scalable coordination behaviors in multi-robot systems. However, established MARL platforms (e.g., SMAC and MPE) lack robotics relevance and hardware deployment, leaving multi-robot learning researchers to develop bespoke environments and hardware testbeds dedicated to the development and evaluation of their individual contributions. The Multi-Agent RL Benchmark and Learning Environment for the Robotarium (MARBLER) is an exciting recent step in providing a standardized robotics-relevant platform for MARL, by bridging the Robotarium testbed with existing MARL software infrastructure. However, MARBLER lacks support for parallelization and GPU/TPU execution, making the platform prohibitively slow compared to modern MARL environments and hindering adoption. We contribute JaxRobotarium, a Jax-powered end-to-end simulation, learning, deployment, and benchmarking platform for the Robotarium. JaxRobotarium enables rapid training and deployment of multi-robot reinforcement learning (MRRL) policies with realistic robot dynamics and safety constraints, supporting both parallelization and hardware acceleration. Our generalizable learning interface provides an easy-to-use integration with SOTA MARL libraries (e.g., JaxMARL). In addition, JaxRobotarium includes eight standardized coordination scenarios, including four novel scenarios that bring established MARL benchmark tasks (e.g., RWARE and Level-Based Foraging) to a realistic robotics setting. We demonstrate that JaxRobotarium retains high simulation fidelity while achieving dramatic speedups over baseline (20x in training and 150x in simulation), and provides an open-access sim-to-real evaluation pipeline through the Robotarium testbed, accelerating and democratizing access to multi-robot learning research and evaluation.
Magnifier Prompt: Tackling Multimodal Hallucination via Extremely Simple Instructions
Oct 15, 2024



Hallucinations in multimodal large language models (MLLMs) hinder their practical applications. To address this, we propose a Magnifier Prompt (MagPrompt), a simple yet effective method to tackle hallucinations in MLLMs via extremely simple instructions. MagPrompt is based on the following two key principles, which guide the design of various effective prompts, demonstrating robustness: (1) MLLMs should focus more on the image. (2) When there are conflicts between the image and the model's inner knowledge, MLLMs should prioritize the image. MagPrompt is training-free and can be applied to open-source and closed-source models, such as GPT-4o and Gemini-pro. It performs well across many datasets and its effectiveness is comparable or even better than more complex methods like VCD. Furthermore, our prompt design principles and experimental analyses provide valuable insights into multimodal hallucination.
Resilient and Adaptive Replanning for Multi-Robot Target Tracking with Sensing and Communication Danger Zones
Sep 17, 2024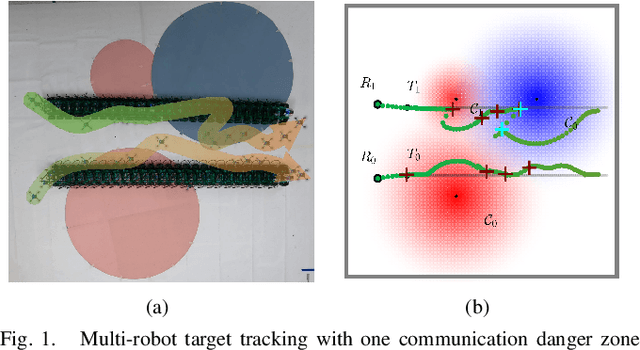
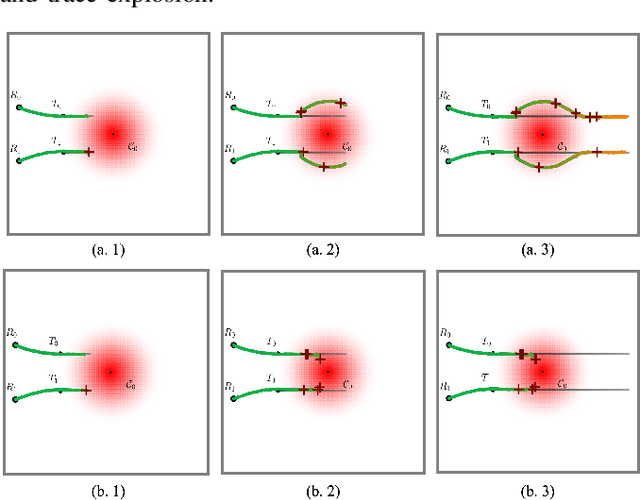
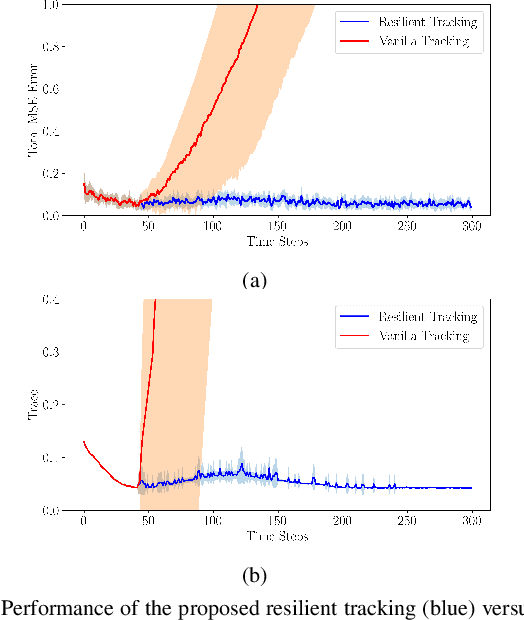
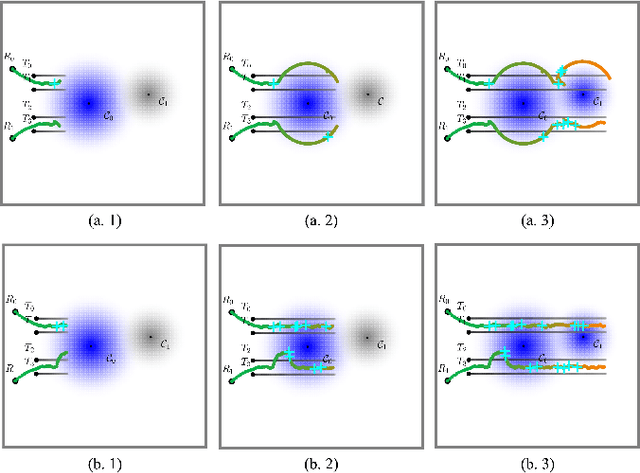
Multi-robot collaboration for target tracking presents significant challenges in hazardous environments, including addressing robot failures, dynamic priority changes, and other unpredictable factors. Moreover, these challenges are increased in adversarial settings if the environment is unknown. In this paper, we propose a resilient and adaptive framework for multi-robot, multi-target tracking in environments with unknown sensing and communication danger zones. The damages posed by these zones are temporary, allowing robots to track targets while accepting the risk of entering dangerous areas. We formulate the problem as an optimization with soft chance constraints, enabling real-time adjustments to robot behavior based on varying types of dangers and failures. An adaptive replanning strategy is introduced, featuring different triggers to improve group performance. This approach allows for dynamic prioritization of target tracking and risk aversion or resilience, depending on evolving resources and real-time conditions. To validate the effectiveness of the proposed method, we benchmark and evaluate it across multiple scenarios in simulation and conduct several real-world experiments.
PhD: A Prompted Visual Hallucination Evaluation Dataset
Mar 17, 2024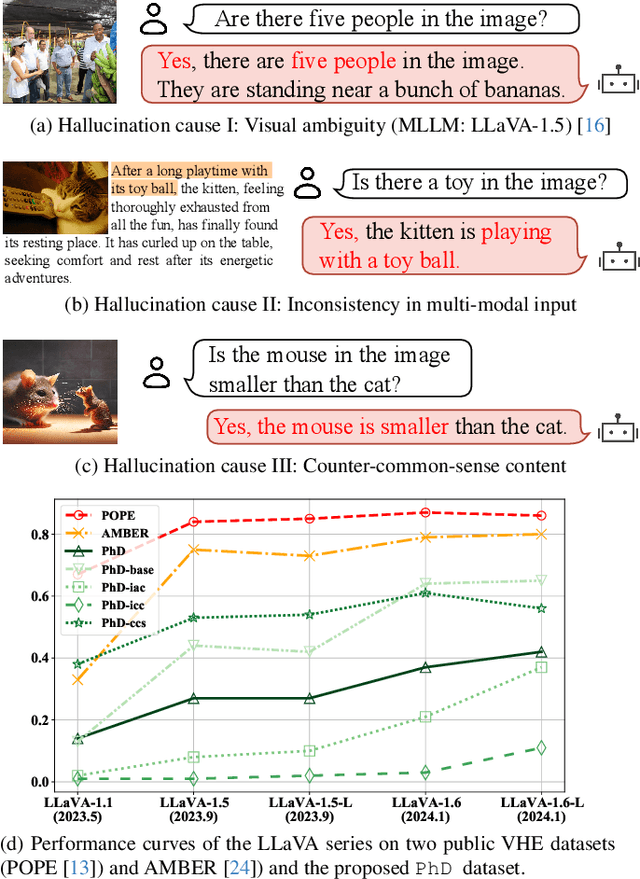

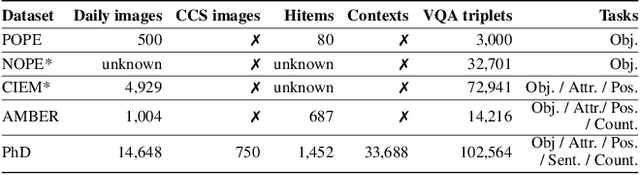

The rapid growth of Large Language Models (LLMs) has driven the development of Large Vision-Language Models (LVLMs). The challenge of hallucination, prevalent in LLMs, also emerges in LVLMs. However, most existing efforts mainly focus on object hallucination in LVLM, ignoring diverse types of LVLM hallucinations. In this study, we delve into the Intrinsic Vision-Language Hallucination (IVL-Hallu) issue, thoroughly analyzing different types of IVL-Hallu on their causes and reflections. Specifically, we propose several novel IVL-Hallu tasks and categorize them into four types: (a) object hallucination, which arises from the misidentification of objects, (b) attribute hallucination, which is caused by the misidentification of attributes, (c) multi-modal conflicting hallucination, which derives from the contradictions between textual and visual information, and (d) counter-common-sense hallucination, which owes to the contradictions between the LVLM knowledge and actual images. Based on these taxonomies, we propose a more challenging benchmark named PhD to evaluate and explore IVL-Hallu. An automated pipeline is proposed for generating different types of IVL-Hallu data. Extensive experiments on five SOTA LVLMs reveal their inability to effectively tackle our proposed IVL-Hallu tasks, with detailed analyses and insights on the origins and possible solutions of these new challenging IVL-Hallu tasks, facilitating future researches on IVL-Hallu and LVLM. The benchmark can be accessed at https://github.com/jiazhen-code/IntrinsicHallu
Artificial Intelligence for Complex Network: Potential, Methodology and Application
Feb 23, 2024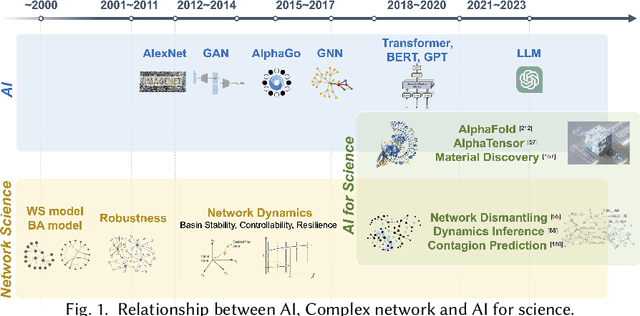
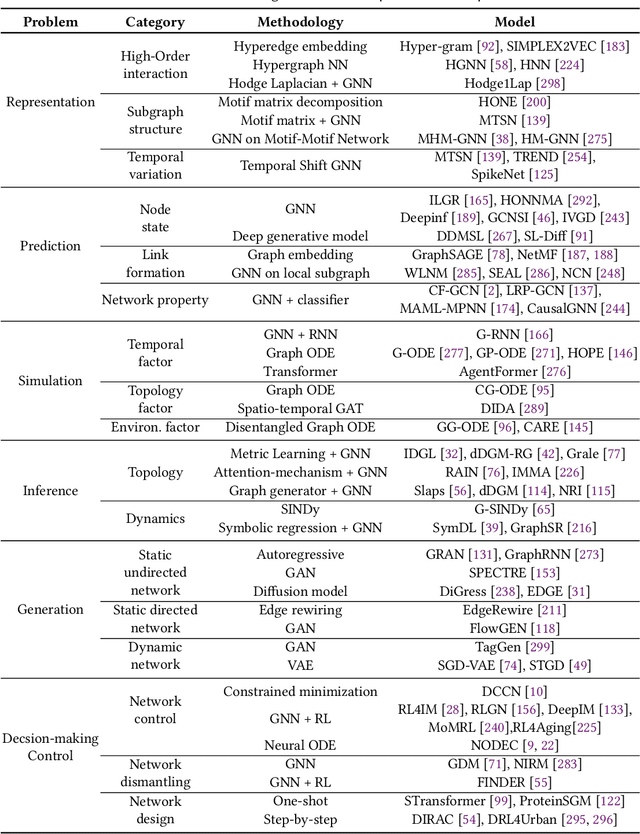
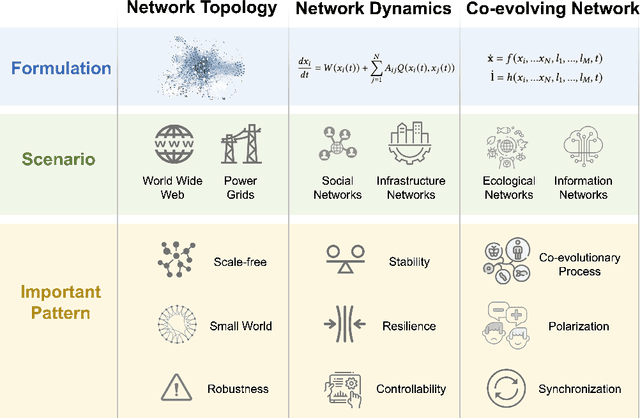
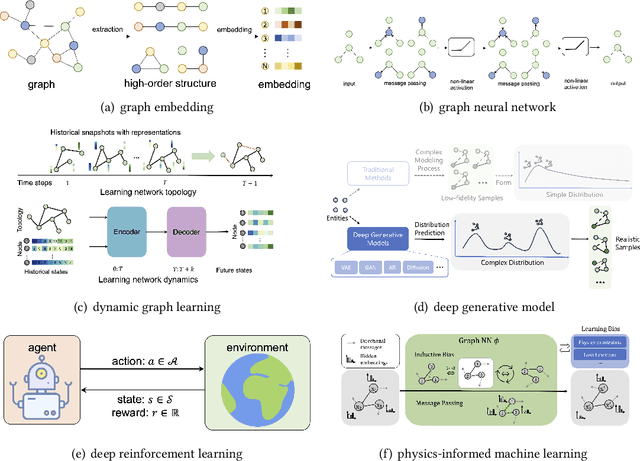
Complex networks pervade various real-world systems, from the natural environment to human societies. The essence of these networks is in their ability to transition and evolve from microscopic disorder-where network topology and node dynamics intertwine-to a macroscopic order characterized by certain collective behaviors. Over the past two decades, complex network science has significantly enhanced our understanding of the statistical mechanics, structures, and dynamics underlying real-world networks. Despite these advancements, there remain considerable challenges in exploring more realistic systems and enhancing practical applications. The emergence of artificial intelligence (AI) technologies, coupled with the abundance of diverse real-world network data, has heralded a new era in complex network science research. This survey aims to systematically address the potential advantages of AI in overcoming the lingering challenges of complex network research. It endeavors to summarize the pivotal research problems and provide an exhaustive review of the corresponding methodologies and applications. Through this comprehensive survey-the first of its kind on AI for complex networks-we expect to provide valuable insights that will drive further research and advancement in this interdisciplinary field.
Multi-Robot Localization and Target Tracking with Connectivity Maintenance and Collision Avoidance
Oct 10, 2022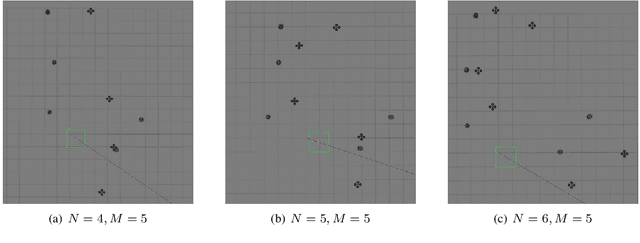
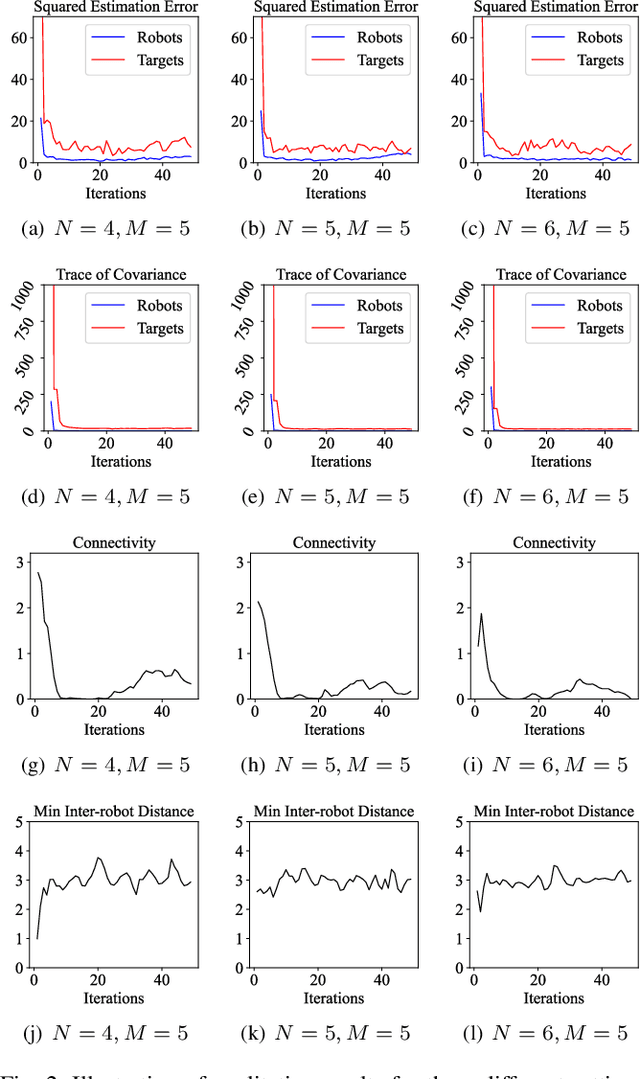
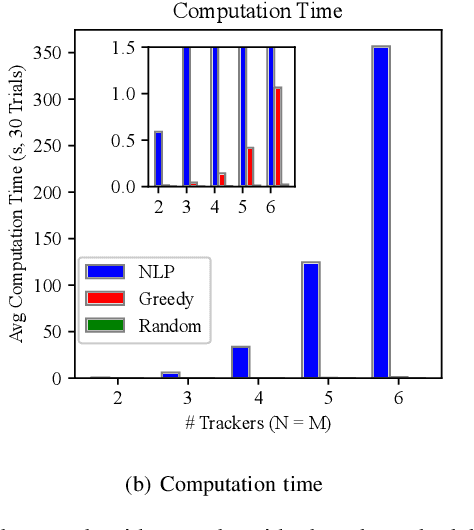
We study the problem that requires a team of robots to perform joint localization and target tracking task while ensuring team connectivity and collision avoidance. The problem can be formalized as a nonlinear, non-convex optimization program, which is typically hard to solve. To this end, we design a two-staged approach that utilizes a greedy algorithm to optimize the joint localization and target tracking performance and applies control barrier functions to ensure safety constraints, i.e., maintaining connectivity of the robot team and preventing inter-robot collisions. Simulated Gazebo experiments verify the effectiveness of the proposed approach. We further compare our greedy algorithm to a non-linear optimization solver and a random algorithm, in terms of the joint localization and tracking quality as well as the computation time. The results demonstrate that our greedy algorithm achieves high task quality and runs efficiently.
Attention-aware Resource Allocation and QoE Analysis for Metaverse xURLLC Services
Aug 11, 2022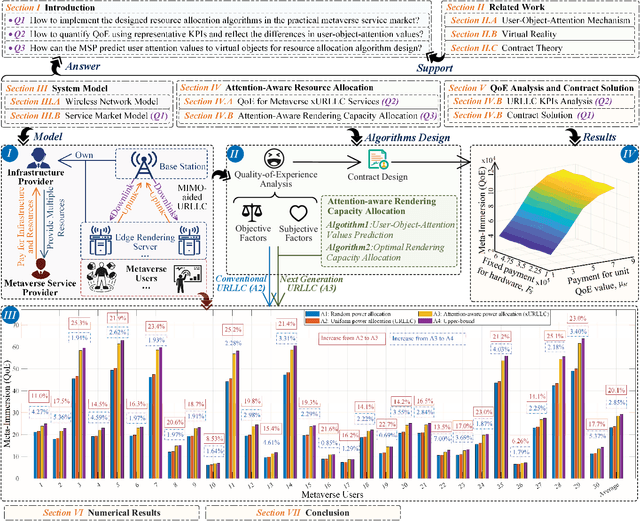
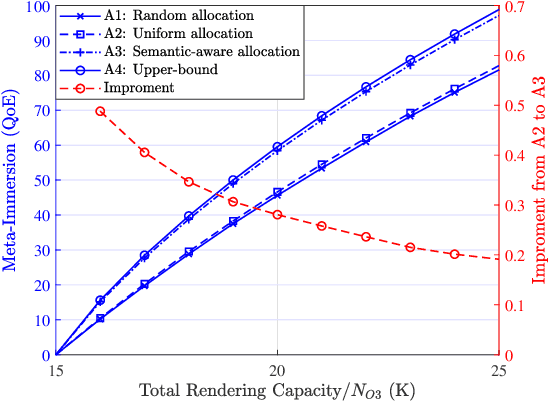
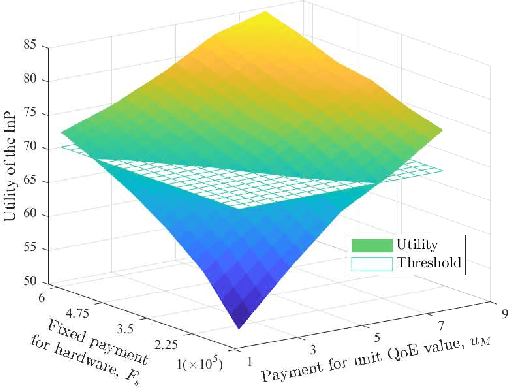
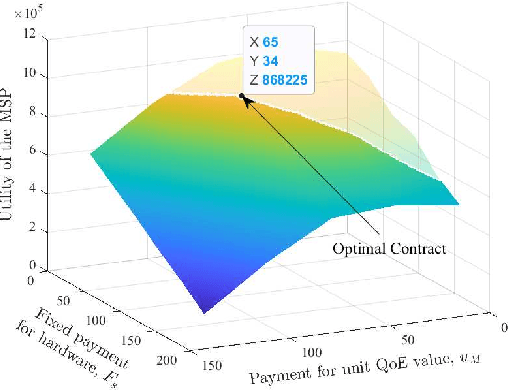
As a virtual world interacting with the real world, Metaverse encapsulates our expectations of the next-generation Internet, bringing new key performance indicators (KPIs). Especially, Metaverse services based on graphical technologies, e.g., virtual traveling, require the low latency of virtual object data transmitting and the high reliability of user instruction uploading. Although conventional ultra-reliable and low-latency communications (URLLC) can satisfy the vast majority of objective service KPIs, it is difficult to offer users a personalized immersive experience that is a distinctive feature of next-generation Internet services. Since the quality of experience (QoE) can be regarded as a comprehensive KPI, the URLLC is evolved towards the next generation URLLC (xURLLC) to achieve higher QoE for Metaverse services by allocating more resources to virtual objects in which users are more interested. In this paper, we study the interaction between the Metaverse service provider (MSP) and the network infrastructure provider (InP) to deploy Metaverse xURLLC services. An optimal contract design framework is provided. Specifically, the utility of the MSP, defined as a function of Metaverse users' QoE, is to be maximized, while ensuring the incentives of the InP. To model the QoE of Metaverse xURLLC services, we propose a novel metric named Meta-Immersion that incorporates both the objective network KPIs and subjective feelings of Metaverse users. Using a user-object-attention level (UOAL) dataset, we develop and validate an attention-aware rendering capacity allocation scheme to improve QoE. It is shown that an average of 20.1% QoE improvement is achieved by the xURLLC compared to the conventional URLLC with the uniform allocation scheme. A higher percentage of QoE improvement, e.g., 40%, is achieved when the total resources are limited.
Decentralized Risk-Aware Tracking of Multiple Targets
Aug 04, 2022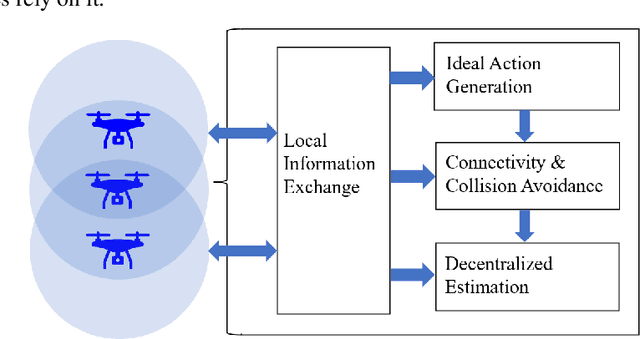
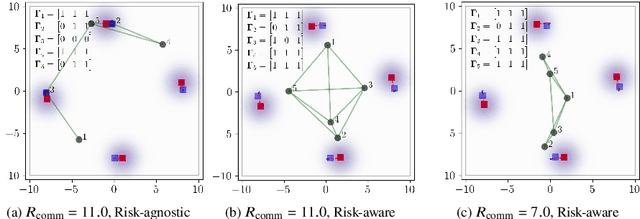
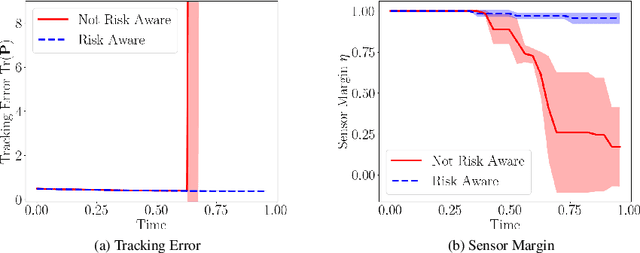
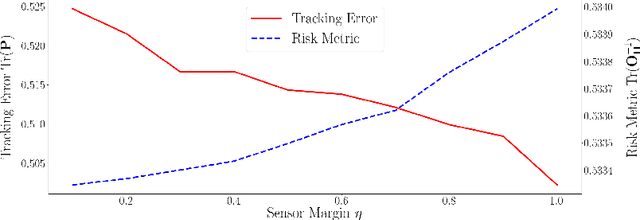
We consider the setting where a team of robots is tasked with tracking multiple targets with the following property: approaching the targets enables more accurate target position estimation, but also increases the risk of sensor failures. Therefore, it is essential to address the trade-off between tracking quality maximization and risk minimization. In our previous work, a centralized controller is developed to plan motions for all the robots -- however, this is not a scalable approach. Here, we present a decentralized and risk-aware multi-target tracking framework, in which each robot plans its motion trading off tracking accuracy maximization and aversion to risk, while only relying on its own information and information exchanged with its neighbors. We use the control barrier function to guarantee network connectivity throughout the tracking process. Extensive numerical experiments demonstrate that our system can achieve similar tracking accuracy and risk-awareness to its centralized counterpart.