 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Accuracy Limits of Sequential Recommender Systems: An Entropy-Based Approach
Mar 30, 2026Sequential recommender systems have achieved steady gains in offline accuracy, yet it remains unclear how close current models are to the intrinsic accuracy limit imposed by the data. A reliable, model-agnostic estimate of this ceiling would enable principled difficulty assessment and headroom estimation before costly model development. Existing predictability analyses typically combine entropy estimation with Fano's inequality inversion; however, in recommendation they are hindered by sensitivity to candidate-space specification and distortion from Fano-based scaling in low-predictability regimes. We develop an entropy-induced, training-free approach for quantifying accuracy limits in sequential recommendation, yielding a candidate-size-agnostic estimate. Experiments on controlled synthetic generators and diverse real-world benchmarks show that the estimator tracks oracle-controlled difficulty more faithfully than baselines, remains insensitive to candidate-set size, and achieves high rank consistency with best-achieved offline accuracy across state-of-the-art sequential recommenders (Spearman rho up to 0.914). It also supports user-group diagnostics by stratifying users by novelty preference, long-tail exposure, and activity, revealing systematic predictability differences. Furthermore, predictability can guide training data selection: training sets constructed from high-predictability users yield strong downstream performance under reduced data budgets. Overall, the proposed estimator provides a practical reference for assessing attainable accuracy limits, supporting user-group diagnostics, and informing data-centric decisions in sequential recommendation.
HVR-Met: A Hypothesis-Verification-Replaning Agentic System for Extreme Weather Diagnosis
Mar 01, 2026While deep learning-based weather forecasting paradigms have made significant strides, addressing extreme weather diagnostics remains a formidable challenge. This gap exists primarily because the diagnostic process demands sophisticated multi-step logical reasoning, dynamic tool invocation, and expert-level prior judgment. Although agents possess inherent advantages in task decomposition and autonomous execution, current architectures are still hampered by critical bottlenecks: inadequate expert knowledge integration, a lack of professional-grade iterative reasoning loops, and the absence of fine-grained validation and evaluation systems for complex workflows under extreme conditions. To this end, we propose HVR-Met, a multi-agent meteorological diagnostic system characterized by the deep integration of expert knowledge. Its central innovation is the ``Hypothesis-Verification-Replanning'' closed-loop mechanism, which facilitates sophisticated iterative reasoning for anomalous meteorological signals during extreme weather events. To bridge gaps within existing evaluation frameworks, we further introduce a novel benchmark focused on atomic-level subtasks. Experimental evidence demonstrates that the system excels in complex diagnostic scenarios.
Inferring Network Evolutionary History via Structure-State Coupled Learning
Jan 05, 2026Inferring a network's evolutionary history from a single final snapshot with limited temporal annotations is fundamental yet challenging. Existing approaches predominantly rely on topology alone, which often provides insufficient and noisy cues. This paper leverages network steady-state dynamics -- converged node states under a given dynamical process -- as an additional and widely accessible observation for network evolution history inference. We propose CS$^2$, which explicitly models structure-state coupling to capture how topology modulates steady states and how the two signals jointly improve edge discrimination for formation-order recovery. Experiments on six real temporal networks, evaluated under multiple dynamical processes, show that CS$^2$ consistently outperforms strong baselines, improving pairwise edge precedence accuracy by 4.0% on average and global ordering consistency (Spearman-$ρ$) by 7.7% on average. CS$^2$ also more faithfully recovers macroscopic evolution trajectories such as clustering formation, degree heterogeneity, and hub growth. Moreover, a steady-state-only variant remains competitive when reliable topology is limited, highlighting steady states as an independent signal for evolution inference.
PID-controlled Langevin Dynamics for Faster Sampling of Generative Models
Nov 16, 2025Langevin dynamics sampling suffers from extremely low generation speed, fundamentally limited by numerous fine-grained iterations to converge to the target distribution. We introduce PID-controlled Langevin Dynamics (PIDLD), a novel sampling acceleration algorithm that reinterprets the sampling process using control-theoretic principles. By treating energy gradients as feedback signals, PIDLD combines historical gradients (the integral term) and gradient trends (the derivative term) to efficiently traverse energy landscapes and adaptively stabilize, thereby significantly reducing the number of iterations required to produce high-quality samples. Our approach requires no additional training, datasets, or prior information, making it immediately integrable with any Langevin-based method. Extensive experiments across image generation and reasoning tasks demonstrate that PIDLD achieves higher quality with fewer steps, making Langevin-based generative models more practical for efficiency-critical applications. The implementation can be found at \href{https://github.com/tsinghua-fib-lab/PIDLD}{https://github.com/tsinghua-fib-lab/PIDLD}.
Fine-Tuning Flow Matching via Maximum Likelihood Estimation of Reconstructions
Oct 02, 2025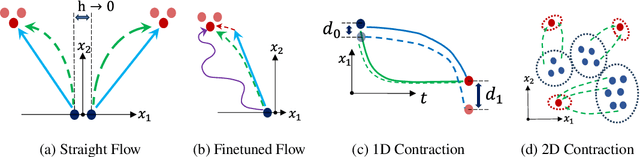
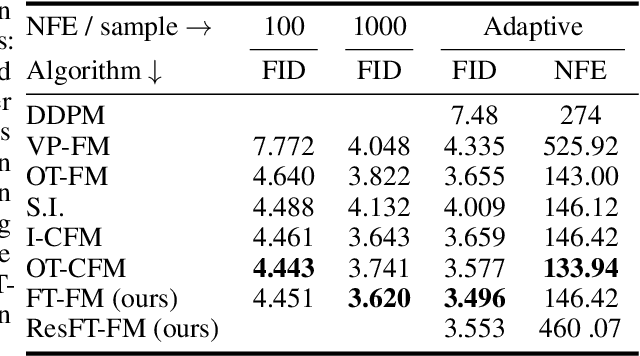
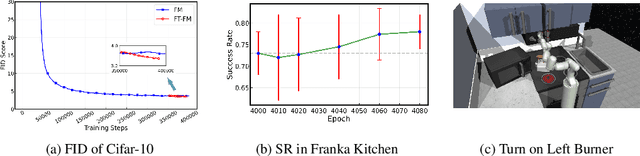

Flow Matching (FM) algorithm achieves remarkable results in generative tasks especially in robotic manipulation. Building upon the foundations of diffusion models, the simulation-free paradigm of FM enables simple and efficient training, but inherently introduces a train-inference gap. Specifically, we cannot assess the model's output during the training phase. In contrast, other generative models including Variational Autoencoder (VAE), Normalizing Flow and Generative Adversarial Networks (GANs) directly optimize on the reconstruction loss. Such a gap is particularly evident in scenarios that demand high precision, such as robotic manipulation. Moreover, we show that FM's over-pursuit of straight predefined paths may introduce some serious problems such as stiffness into the system. These motivate us to fine-tune FM via Maximum Likelihood Estimation of reconstructions - an approach made feasible by FM's underlying smooth ODE formulation, in contrast to the stochastic differential equations (SDEs) used in diffusion models. This paper first theoretically analyzes the relation between training loss and inference error in FM. Then we propose a method of fine-tuning FM via Maximum Likelihood Estimation of reconstructions, which includes both straightforward fine-tuning and residual-based fine-tuning approaches. Furthermore, through specifically designed architectures, the residual-based fine-tuning can incorporate the contraction property into the model, which is crucial for the model's robustness and interpretability. Experimental results in image generation and robotic manipulation verify that our method reliably improves the inference performance of FM.
MoveFM-R: Advancing Mobility Foundation Models via Language-driven Semantic Reasoning
Sep 26, 2025Mobility Foundation Models (MFMs) have advanced the modeling of human movement patterns, yet they face a ceiling due to limitations in data scale and semantic understanding. While Large Language Models (LLMs) offer powerful semantic reasoning, they lack the innate understanding of spatio-temporal statistics required for generating physically plausible mobility trajectories. To address these gaps, we propose MoveFM-R, a novel framework that unlocks the full potential of mobility foundation models by leveraging language-driven semantic reasoning capabilities. It tackles two key challenges: the vocabulary mismatch between continuous geographic coordinates and discrete language tokens, and the representation gap between the latent vectors of MFMs and the semantic world of LLMs. MoveFM-R is built on three core innovations: a semantically enhanced location encoding to bridge the geography-language gap, a progressive curriculum to align the LLM's reasoning with mobility patterns, and an interactive self-reflection mechanism for conditional trajectory generation. Extensive experiments demonstrate that MoveFM-R significantly outperforms existing MFM-based and LLM-based baselines. It also shows robust generalization in zero-shot settings and excels at generating realistic trajectories from natural language instructions. By synthesizing the statistical power of MFMs with the deep semantic understanding of LLMs, MoveFM-R pioneers a new paradigm that enables a more comprehensive, interpretable, and powerful modeling of human mobility. The implementation of MoveFM-R is available online at https://anonymous.4open.science/r/MoveFM-R-CDE7/.
UniMove: A Unified Model for Multi-city Human Mobility Prediction
Aug 09, 2025Human mobility prediction is vital for urban planning, transportation optimization, and personalized services. However, the inherent randomness, non-uniform time intervals, and complex patterns of human mobility, compounded by the heterogeneity introduced by varying city structures, infrastructure, and population densities, present significant challenges in modeling. Existing solutions often require training separate models for each city due to distinct spatial representations and geographic coverage. In this paper, we propose UniMove, a unified model for multi-city human mobility prediction, addressing two challenges: (1) constructing universal spatial representations for effective token sharing across cities, and (2) modeling heterogeneous mobility patterns from varying city characteristics. We propose a trajectory-location dual-tower architecture, with a location tower for universal spatial encoding and a trajectory tower for sequential mobility modeling. We also design MoE Transformer blocks to adaptively select experts to handle diverse movement patterns. Extensive experiments across multiple datasets from diverse cities demonstrate that UniMove truly embodies the essence of a unified model. By enabling joint training on multi-city data with mutual data enhancement, it significantly improves mobility prediction accuracy by over 10.2\%. UniMove represents a key advancement toward realizing a true foundational model with a unified architecture for human mobility. We release the implementation at https://github.com/tsinghua-fib-lab/UniMove/.
Mamba Integrated with Physics Principles Masters Long-term Chaotic System Forecasting
May 29, 2025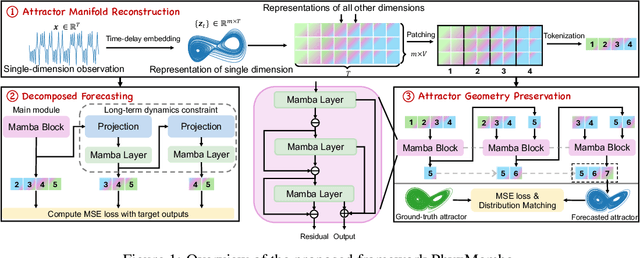
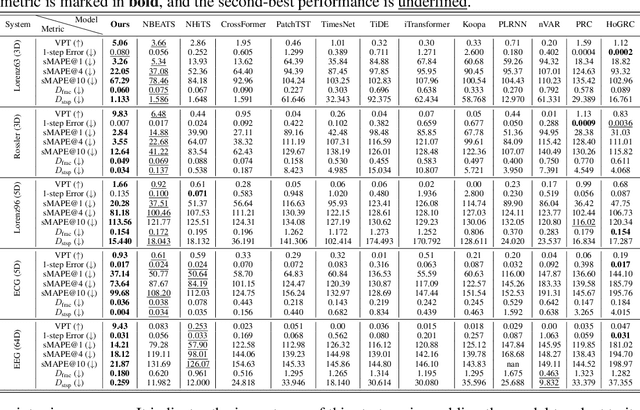
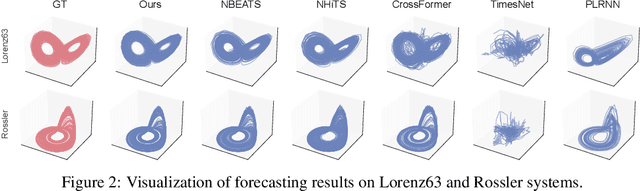
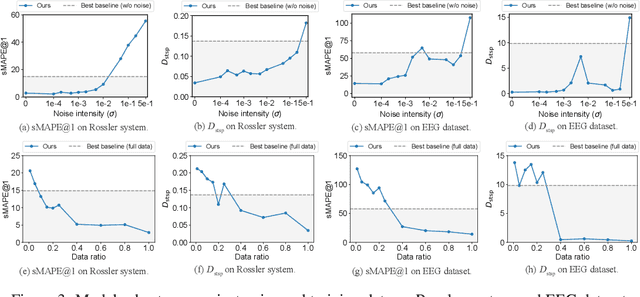
Long-term forecasting of chaotic systems from short-term observations remains a fundamental and underexplored challenge due to the intrinsic sensitivity to initial conditions and the complex geometry of strange attractors. Existing approaches often rely on long-term training data or focus on short-term sequence correlations, struggling to maintain predictive stability and dynamical coherence over extended horizons. We propose PhyxMamba, a novel framework that integrates a Mamba-based state-space model with physics-informed principles to capture the underlying dynamics of chaotic systems. By reconstructing the attractor manifold from brief observations using time-delay embeddings, PhyxMamba extracts global dynamical features essential for accurate forecasting. Our generative training scheme enables Mamba to replicate the physical process, augmented by multi-token prediction and attractor geometry regularization for physical constraints, enhancing prediction accuracy and preserving key statistical invariants. Extensive evaluations on diverse simulated and real-world chaotic systems demonstrate that PhyxMamba delivers superior long-term forecasting and faithfully captures essential dynamical invariants from short-term data. This framework opens new avenues for reliably predicting chaotic systems under observation-scarce conditions, with broad implications across climate science, neuroscience, epidemiology, and beyond. Our code is open-source at https://github.com/tsinghua-fib-lab/PhyxMamba.
TrajMoE: Spatially-Aware Mixture of Experts for Unified Human Mobility Modeling
May 24, 2025Modeling human mobility across diverse cities is essential for applications such as urban planning, transportation optimization, and personalized services. However, generalization remains challenging due to heterogeneous spatial representations and mobility patterns across cities. Existing methods typically rely on numerical coordinates or require training city-specific models, limiting their scalability and transferability. We propose TrajMoE, a unified and scalable model for cross-city human mobility modeling. TrajMoE addresses two key challenges: (1) inconsistent spatial semantics across cities, and (2) diverse urban mobility patterns. To tackle these, we begin by designing a spatial semantic encoder that learns transferable location representations from POI-based functional semantics and visit patterns. Furthermore, we design a Spatially-Aware Mixture-of-Experts (SAMoE) Transformer that injects structured priors into experts specialized in distinct mobility semantics, along with a shared expert to capture city-invariant patterns and enable adaptive cross-city generalization. Extensive experiments demonstrate that TrajMoE achieves up to 27% relative improvement over competitive mobility foundation models after only one epoch of fine-tuning, and consistently outperforms full-data baselines using merely 5% of target city data. These results establish TrajMoE as a significant step toward realizing a truly generalizable, transferable, and pretrainable foundation model for human mobility.
Tuning Language Models for Robust Prediction of Diverse User Behaviors
May 23, 2025Predicting user behavior is essential for intelligent assistant services, yet deep learning models often struggle to capture long-tailed behaviors. Large language models (LLMs), with their pretraining on vast corpora containing rich behavioral knowledge, offer promise. However, existing fine-tuning approaches tend to overfit to frequent ``anchor'' behaviors, reducing their ability to predict less common ``tail'' behaviors. In this paper, we introduce BehaviorLM, a progressive fine-tuning approach that addresses this issue. In the first stage, LLMs are fine-tuned on anchor behaviors while preserving general behavioral knowledge. In the second stage, fine-tuning uses a balanced subset of all behaviors based on sample difficulty to improve tail behavior predictions without sacrificing anchor performance. Experimental results on two real-world datasets demonstrate that BehaviorLM robustly predicts both anchor and tail behaviors and effectively leverages LLM behavioral knowledge to master tail behavior prediction with few-shot examples.