 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaOD: Dynamic Origin-Destination Flow Generation with Discrete-to-Continuous Temporal Semantic Modeling
Jun 08, 2026Dynamic origin-destination (OD) flow generation seeks to synthesize realistic mobility dynamics from temporal context alone, without relying on historical OD observations. A key challenge is to translate semantic temporal signals into temporally coherent OD patterns while preserving the inherent spatial heterogeneity of urban regions. We propose DynaOD, a semantic-driven framework that models temporal dynamics through two complementary perspectives: discrete directional trends that characterize qualitative shifts in urban activity patterns, and continuous temporal evolution that captures how such shifts unfold over time. By jointly encoding these temporal semantics, the framework constructs time-varying region representations that condition pretrained static OD generators in a lightweight and plug-and-play fashion. This modular design further supports scalable deployment and cross-city transferability. Extensive experiments on large-scale real-world datasets show that our method consistently outperforms representative baselines in both predictive accuracy and distributional fidelity. Code is publicly available at https://github.com/csjiezhao/DynaOD.
Inferring Network Evolutionary History via Structure-State Coupled Learning
Jan 05, 2026Inferring a network's evolutionary history from a single final snapshot with limited temporal annotations is fundamental yet challenging. Existing approaches predominantly rely on topology alone, which often provides insufficient and noisy cues. This paper leverages network steady-state dynamics -- converged node states under a given dynamical process -- as an additional and widely accessible observation for network evolution history inference. We propose CS$^2$, which explicitly models structure-state coupling to capture how topology modulates steady states and how the two signals jointly improve edge discrimination for formation-order recovery. Experiments on six real temporal networks, evaluated under multiple dynamical processes, show that CS$^2$ consistently outperforms strong baselines, improving pairwise edge precedence accuracy by 4.0% on average and global ordering consistency (Spearman-$ρ$) by 7.7% on average. CS$^2$ also more faithfully recovers macroscopic evolution trajectories such as clustering formation, degree heterogeneity, and hub growth. Moreover, a steady-state-only variant remains competitive when reliable topology is limited, highlighting steady states as an independent signal for evolution inference.
PhysFire-WM: A Physics-Informed World Model for Emulating Fire Spread Dynamics
Dec 19, 2025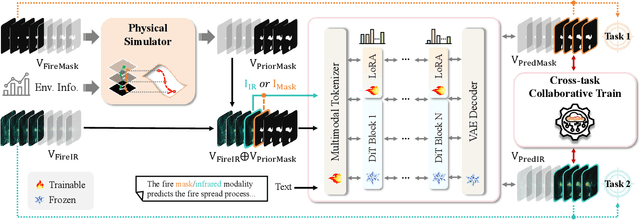
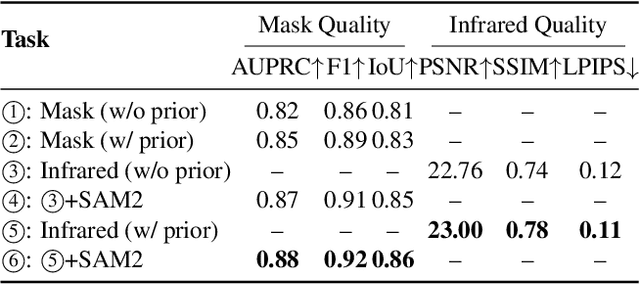
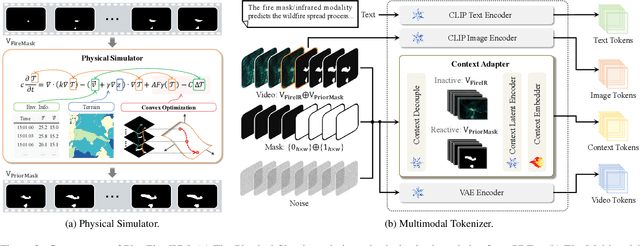
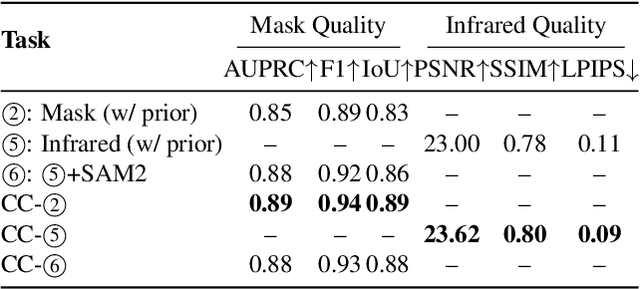
Fine-grained fire prediction plays a crucial role in emergency response. Infrared images and fire masks provide complementary thermal and boundary information, yet current methods are predominantly limited to binary mask modeling with inherent signal sparsity, failing to capture the complex dynamics of fire. While world models show promise in video generation, their physical inconsistencies pose significant challenges for fire forecasting. This paper introduces PhysFire-WM, a Physics-informed World Model for emulating Fire spread dynamics. Our approach internalizes combustion dynamics by encoding structured priors from a Physical Simulator to rectify physical discrepancies, coupled with a Cross-task Collaborative Training strategy (CC-Train) that alleviates the issue of limited information in mask-based modeling. Through parameter sharing and gradient coordination, CC-Train effectively integrates thermal radiation dynamics and spatial boundary delineation, enhancing both physical realism and geometric accuracy. Extensive experiments on a fine-grained multimodal fire dataset demonstrate the superior accuracy of PhysFire-WM in fire spread prediction. Validation underscores the importance of physical priors and cross-task collaboration, providing new insights for applying physics-informed world models to disaster prediction.
Context-Aware Sentiment Forecasting via LLM-based Multi-Perspective Role-Playing Agents
May 30, 2025User sentiment on social media reveals the underlying social trends, crises, and needs. Researchers have analyzed users' past messages to trace the evolution of sentiments and reconstruct sentiment dynamics. However, predicting the imminent sentiment of an ongoing event is rarely studied. In this paper, we address the problem of \textbf{sentiment forecasting} on social media to predict the user's future sentiment in response to the development of the event. We extract sentiment-related features to enhance the modeling skill and propose a multi-perspective role-playing framework to simulate the process of human response. Our preliminary results show significant improvement in sentiment forecasting on both microscopic and macroscopic levels.
KEVER^2: Knowledge-Enhanced Visual Emotion Reasoning and Retrieval
May 30, 2025Understanding what emotions images evoke in their viewers is a foundational goal in human-centric visual computing. While recent advances in vision-language models (VLMs) have shown promise for visual emotion analysis (VEA), several key challenges remain unresolved. Emotional cues in images are often abstract, overlapping, and entangled, making them difficult to model and interpret. Moreover, VLMs struggle to align these complex visual patterns with emotional semantics due to limited supervision and sparse emotional grounding. Finally, existing approaches lack structured affective knowledge to resolve ambiguity and ensure consistent emotional reasoning across diverse visual domains. To address these limitations, we propose \textbf{K-EVER\textsuperscript{2}}, a knowledge-enhanced framework for emotion reasoning and retrieval. Our approach introduces a semantically structured formulation of visual emotion cues and integrates external affective knowledge through multimodal alignment. Without relying on handcrafted labels or direct emotion supervision, K-EVER\textsuperscript{2} achieves robust and interpretable emotion predictions across heterogeneous image types. We validate our framework on three representative benchmarks, Emotion6, EmoSet, and M-Disaster, covering social media imagery, human-centric scenes, and disaster contexts. K-EVER\textsuperscript{2} consistently outperforms strong CNN and VLM baselines, achieving up to a \textbf{19\% accuracy gain} for specific emotions and a \textbf{12.3\% average accuracy gain} across all emotion categories. Our results demonstrate a scalable and generalizable solution for advancing emotional understanding of visual content.
Mamba Integrated with Physics Principles Masters Long-term Chaotic System Forecasting
May 29, 2025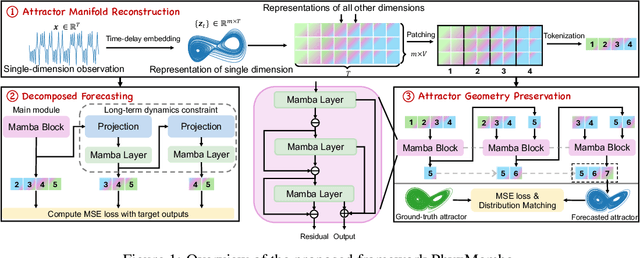
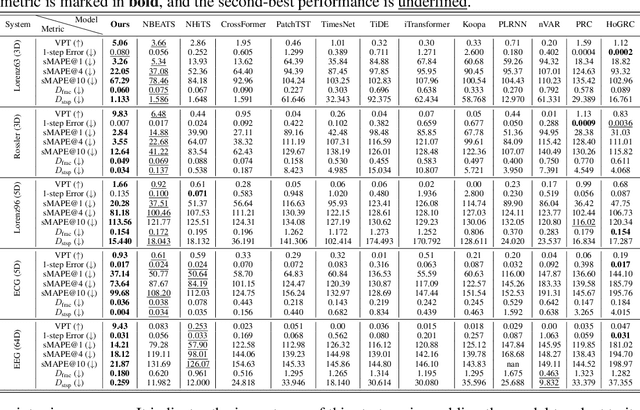
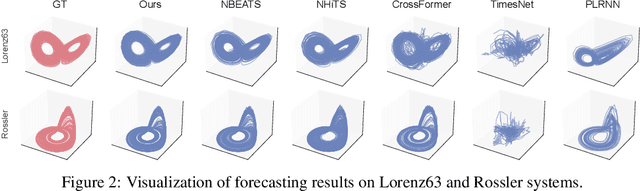
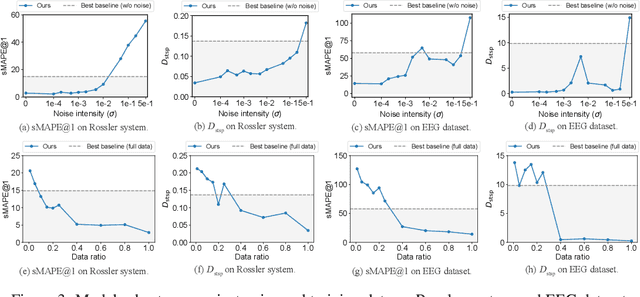
Long-term forecasting of chaotic systems from short-term observations remains a fundamental and underexplored challenge due to the intrinsic sensitivity to initial conditions and the complex geometry of strange attractors. Existing approaches often rely on long-term training data or focus on short-term sequence correlations, struggling to maintain predictive stability and dynamical coherence over extended horizons. We propose PhyxMamba, a novel framework that integrates a Mamba-based state-space model with physics-informed principles to capture the underlying dynamics of chaotic systems. By reconstructing the attractor manifold from brief observations using time-delay embeddings, PhyxMamba extracts global dynamical features essential for accurate forecasting. Our generative training scheme enables Mamba to replicate the physical process, augmented by multi-token prediction and attractor geometry regularization for physical constraints, enhancing prediction accuracy and preserving key statistical invariants. Extensive evaluations on diverse simulated and real-world chaotic systems demonstrate that PhyxMamba delivers superior long-term forecasting and faithfully captures essential dynamical invariants from short-term data. This framework opens new avenues for reliably predicting chaotic systems under observation-scarce conditions, with broad implications across climate science, neuroscience, epidemiology, and beyond. Our code is open-source at https://github.com/tsinghua-fib-lab/PhyxMamba.
UniCO: Towards a Unified Model for Combinatorial Optimization Problems
May 07, 2025



Combinatorial Optimization (CO) encompasses a wide range of problems that arise in many real-world scenarios. While significant progress has been made in developing learning-based methods for specialized CO problems, a unified model with a single architecture and parameter set for diverse CO problems remains elusive. Such a model would offer substantial advantages in terms of efficiency and convenience. In this paper, we introduce UniCO, a unified model for solving various CO problems. Inspired by the success of next-token prediction, we frame each problem-solving process as a Markov Decision Process (MDP), tokenize the corresponding sequential trajectory data, and train the model using a transformer backbone. To reduce token length in the trajectory data, we propose a CO-prefix design that aggregates static problem features. To address the heterogeneity of state and action tokens within the MDP, we employ a two-stage self-supervised learning approach. In this approach, a dynamic prediction model is first trained and then serves as a pre-trained model for subsequent policy generation. Experiments across 10 CO problems showcase the versatility of UniCO, emphasizing its ability to generalize to new, unseen problems with minimal fine-tuning, achieving even few-shot or zero-shot performance. Our framework offers a valuable complement to existing neural CO methods that focus on optimizing performance for individual problems.
Causality Enhanced Origin-Destination Flow Prediction in Data-Scarce Cities
Mar 09, 2025Accurate origin-destination (OD) flow prediction is of great importance to developing cities, as it can contribute to optimize urban structures and layouts. However, with the common issues of missing regional features and lacking OD flow data, it is quite daunting to predict OD flow in developing cities. To address this challenge, we propose a novel Causality-Enhanced OD Flow Prediction (CE-OFP), a unified framework that aims to transfer urban knowledge between cities and achieve accuracy improvements in OD flow predictions across data-scarce cities. In specific, we propose a novel reinforcement learning model to discover universal causalities among urban features in data-rich cities and build corresponding causal graphs. Then, we further build Causality-Enhanced Variational Auto-Encoder (CE-VAE) to incorporate causal graphs for effective feature reconstruction in data-scarce cities. Finally, with the reconstructed features, we devise a knowledge distillation method with a graph attention network to migrate the OD prediction model from data-rich cities to data-scare cities. Extensive experiments on two pairs of real-world datasets validate that the proposed CE-OFP remarkably outperforms state-of-the-art baselines, which can reduce the RMSE of OD flow prediction for data-scarce cities by up to 11%.
EPR-GAIL: An EPR-Enhanced Hierarchical Imitation Learning Framework to Simulate Complex User Consumption Behaviors
Mar 09, 2025

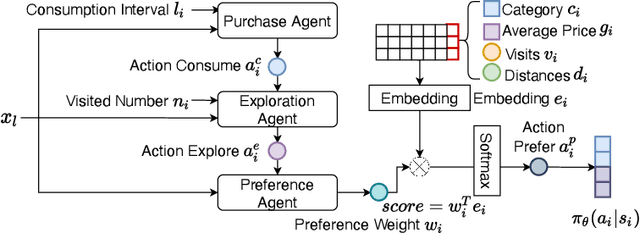

User consumption behavior data, which records individuals' online spending history at various types of stores, has been widely used in various applications, such as store recommendation, site selection, and sale forecasting. However, its high worth is limited due to deficiencies in data comprehensiveness and changes of application scenarios. Thus, generating high-quality sequential consumption data by simulating complex user consumption behaviors is of great importance to real-world applications. Two branches of existing sequence generation methods are both limited in quality. Model-based methods with simplified assumptions fail to model the complex decision process of user consumption, while data-driven methods that emulate real-world data are prone to noises, unobserved behaviors, and dynamic decision space. In this work, we propose to enhance the fidelity and trustworthiness of the data-driven Generative Adversarial Imitation Learning (GAIL) method by blending it with the Exploration and Preferential Return EPR model . The core idea of our EPR-GAIL framework is to model user consumption behaviors as a complex EPR decision process, which consists of purchase, exploration, and preference decisions. Specifically, we design the hierarchical policy function in the generator as a realization of the EPR decision process and employ the probability distributions of the EPR model to guide the reward function in the discriminator. Extensive experiments on two real-world datasets of user consumption behaviors on an online platform demonstrate that the EPR-GAIL framework outperforms the best state-of-the-art baseline by over 19\% in terms of data fidelity. Furthermore, the generated consumption behavior data can improve the performance of sale prediction and location recommendation by up to 35.29% and 11.19%, respectively, validating its advantage for practical applications.
Causal Discovery and Inference towards Urban Elements and Associated Factors
Mar 09, 2025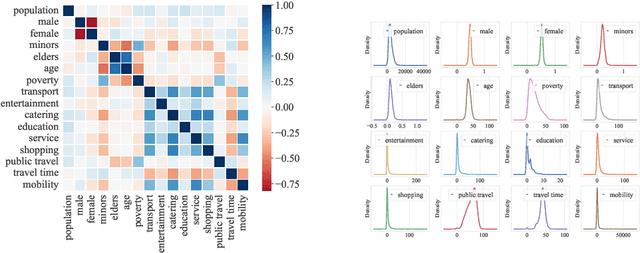
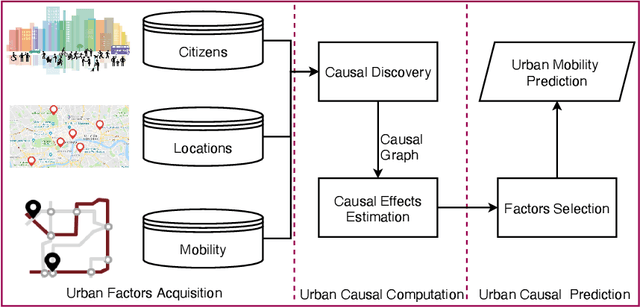
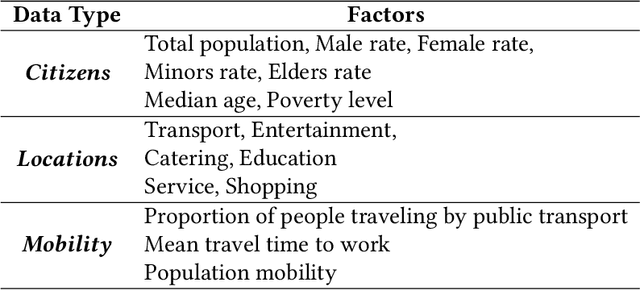
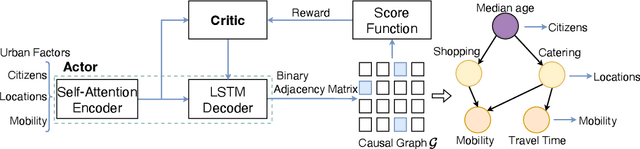
To uncover the city's fundamental functioning mechanisms, it is important to acquire a deep understanding of complicated relationships among citizens, location, and mobility behaviors. Previous research studies have applied direct correlation analysis to investigate such relationships. Nevertheless, due to the ubiquitous confounding effects, empirical correlation analysis may not accurately reflect underlying causal relationships among basic urban elements. In this paper, we propose a novel urban causal computing framework to comprehensively explore causalities and confounding effects among a variety of factors across different types of urban elements. In particular, we design a reinforcement learning algorithm to discover the potential causal graph, which depicts the causal relations between urban factors. The causal graph further serves as the guidance for estimating causal effects between pair-wise urban factors by propensity score matching. After removing the confounding effects from correlations, we leverage significance levels of causal effects in downstream urban mobility prediction tasks. Experimental studies on open-source urban datasets show that the discovered causal graph demonstrates a hierarchical structure, where citizens affect locations, and they both cause changes in urban mobility behaviors. Experimental results in urban mobility prediction tasks further show that the proposed method can effectively reduce confounding effects and enhance performance of urban computing tasks.