 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHYDRA: Unifying Multi-modal Generation and Understanding via Representation-Harmonized Tokenization
Mar 17, 2026Unified Multimodal Models struggle to bridge the fundamental gap between the abstract representations needed for visual understanding and the detailed primitives required for generation. Existing approaches typically compromise by employing decoupled encoders, stacking representation encoder atop VAEs, or utilizing discrete quantization. However, these methods often disrupt information coherence and lead to optimization conflicts. To this end, we introduce HYDRA-TOK, a representation-harmonized pure ViT in the insight that visual modeling should evolve from generation to understanding. HYDRA-TOK reformulates the standard backbone into a progressive learner that transitions from a Gen-ViT, which captures structure-preserving primitives, to a Sem-ViT for semantic encoding. Crucially, this transition is mediated by a Generation-Semantic Bottleneck (GSB), which compresses features into a low-dimensional space to filter noise for robust synthesis, then restores dimensionality to empower complex semantic comprehension. Built upon this foundation, we present HYDRA, a native unified framework integrating perception and generation within a single parameter space. Extensive experiments establish HYDRA as a new state-of-the-art. It sets a benchmark in visual reconstruction (rFID 0.08) and achieves top-tier generation performance on GenEval (0.86), DPG-Bench (86.4), and WISE (0.53), while simultaneously outperforming previous native UMMs by an average of 10.0 points across eight challenging understanding benchmarks.
R$^2$Energy: A Large-Scale Benchmark for Robust Renewable Energy Forecasting under Diverse and Extreme Conditions
Feb 17, 2026The rapid expansion of renewable energy, particularly wind and solar power, has made reliable forecasting critical for power system operations. While recent deep learning models have achieved strong average accuracy, the increasing frequency and intensity of climate-driven extreme weather events pose severe threats to grid stability and operational security. Consequently, developing robust forecasting models that can withstand volatile conditions has become a paramount challenge. In this paper, we present R$^2$Energy, a large-scale benchmark for NWP-assisted renewable energy forecasting. It comprises over 10.7 million high-fidelity hourly records from 902 wind and solar stations across four provinces in China, providing the diverse meteorological conditions necessary to capture the wide-ranging variability of renewable generation. We further establish a standardized, leakage-free forecasting paradigm that grants all models identical access to future Numerical Weather Prediction (NWP) signals, enabling fair and reproducible comparison across state-of-the-art representative forecasting architectures. Beyond aggregate accuracy, we incorporate regime-wise evaluation with expert-aligned extreme weather annotations, uncovering a critical ``robustness gap'' typically obscured by average metrics. This gap reveals a stark robustness-complexity trade-off: under extreme conditions, a model's reliability is driven by its meteorological integration strategy rather than its architectural complexity. R$^2$Energy provides a principled foundation for evaluating and developing forecasting models for safety-critical power system applications.
Making Avatars Interact: Towards Text-Driven Human-Object Interaction for Controllable Talking Avatars
Feb 02, 2026Generating talking avatars is a fundamental task in video generation. Although existing methods can generate full-body talking avatars with simple human motion, extending this task to grounded human-object interaction (GHOI) remains an open challenge, requiring the avatar to perform text-aligned interactions with surrounding objects. This challenge stems from the need for environmental perception and the control-quality dilemma in GHOI generation. To address this, we propose a novel dual-stream framework, InteractAvatar, which decouples perception and planning from video synthesis for grounded human-object interaction. Leveraging detection to enhance environmental perception, we introduce a Perception and Interaction Module (PIM) to generate text-aligned interaction motions. Additionally, an Audio-Interaction Aware Generation Module (AIM) is proposed to synthesize vivid talking avatars performing object interactions. With a specially designed motion-to-video aligner, PIM and AIM share a similar network structure and enable parallel co-generation of motions and plausible videos, effectively mitigating the control-quality dilemma. Finally, we establish a benchmark, GroundedInter, for evaluating GHOI video generation. Extensive experiments and comparisons demonstrate the effectiveness of our method in generating grounded human-object interactions for talking avatars. Project page: https://interactavatar.github.io
StreamAvatar: Streaming Diffusion Models for Real-Time Interactive Human Avatars
Dec 26, 2025Real-time, streaming interactive avatars represent a critical yet challenging goal in digital human research. Although diffusion-based human avatar generation methods achieve remarkable success, their non-causal architecture and high computational costs make them unsuitable for streaming. Moreover, existing interactive approaches are typically limited to head-and-shoulder region, limiting their ability to produce gestures and body motions. To address these challenges, we propose a two-stage autoregressive adaptation and acceleration framework that applies autoregressive distillation and adversarial refinement to adapt a high-fidelity human video diffusion model for real-time, interactive streaming. To ensure long-term stability and consistency, we introduce three key components: a Reference Sink, a Reference-Anchored Positional Re-encoding (RAPR) strategy, and a Consistency-Aware Discriminator. Building on this framework, we develop a one-shot, interactive, human avatar model capable of generating both natural talking and listening behaviors with coherent gestures. Extensive experiments demonstrate that our method achieves state-of-the-art performance, surpassing existing approaches in generation quality, real-time efficiency, and interaction naturalness. Project page: https://streamavatar.github.io .
ActAvatar: Temporally-Aware Precise Action Control for Talking Avatars
Dec 22, 2025Despite significant advances in talking avatar generation, existing methods face critical challenges: insufficient text-following capability for diverse actions, lack of temporal alignment between actions and audio content, and dependency on additional control signals such as pose skeletons. We present ActAvatar, a framework that achieves phase-level precision in action control through textual guidance by capturing both action semantics and temporal context. Our approach introduces three core innovations: (1) Phase-Aware Cross-Attention (PACA), which decomposes prompts into a global base block and temporally-anchored phase blocks, enabling the model to concentrate on phase-relevant tokens for precise temporal-semantic alignment; (2) Progressive Audio-Visual Alignment, which aligns modality influence with the hierarchical feature learning process-early layers prioritize text for establishing action structure while deeper layers emphasize audio for refining lip movements, preventing modality interference; (3) A two-stage training strategy that first establishes robust audio-visual correspondence on diverse data, then injects action control through fine-tuning on structured annotations, maintaining both audio-visual alignment and the model's text-following capabilities. Extensive experiments demonstrate that ActAvatar significantly outperforms state-of-the-art methods in both action control and visual quality.
Pack and Force Your Memory: Long-form and Consistent Video Generation
Oct 02, 2025Long-form video generation presents a dual challenge: models must capture long-range dependencies while preventing the error accumulation inherent in autoregressive decoding. To address these challenges, we make two contributions. First, for dynamic context modeling, we propose MemoryPack, a learnable context-retrieval mechanism that leverages both textual and image information as global guidance to jointly model short- and long-term dependencies, achieving minute-level temporal consistency. This design scales gracefully with video length, preserves computational efficiency, and maintains linear complexity. Second, to mitigate error accumulation, we introduce Direct Forcing, an efficient single-step approximating strategy that improves training-inference alignment and thereby curtails error propagation during inference. Together, MemoryPack and Direct Forcing substantially enhance the context consistency and reliability of long-form video generation, advancing the practical usability of autoregressive video models.
Arbitrary Generative Video Interpolation
Oct 01, 2025Video frame interpolation (VFI), which generates intermediate frames from given start and end frames, has become a fundamental function in video generation applications. However, existing generative VFI methods are constrained to synthesize a fixed number of intermediate frames, lacking the flexibility to adjust generated frame rates or total sequence duration. In this work, we present ArbInterp, a novel generative VFI framework that enables efficient interpolation at any timestamp and of any length. Specifically, to support interpolation at any timestamp, we propose the Timestamp-aware Rotary Position Embedding (TaRoPE), which modulates positions in temporal RoPE to align generated frames with target normalized timestamps. This design enables fine-grained control over frame timestamps, addressing the inflexibility of fixed-position paradigms in prior work. For any-length interpolation, we decompose long-sequence generation into segment-wise frame synthesis. We further design a novel appearance-motion decoupled conditioning strategy: it leverages prior segment endpoints to enforce appearance consistency and temporal semantics to maintain motion coherence, ensuring seamless spatiotemporal transitions across segments. Experimentally, we build comprehensive benchmarks for multi-scale frame interpolation (2x to 32x) to assess generalizability across arbitrary interpolation factors. Results show that ArbInterp outperforms prior methods across all scenarios with higher fidelity and more seamless spatiotemporal continuity. Project website: https://mcg-nju.github.io/ArbInterp-Web/.
UniCO: Towards a Unified Model for Combinatorial Optimization Problems
May 07, 2025



Combinatorial Optimization (CO) encompasses a wide range of problems that arise in many real-world scenarios. While significant progress has been made in developing learning-based methods for specialized CO problems, a unified model with a single architecture and parameter set for diverse CO problems remains elusive. Such a model would offer substantial advantages in terms of efficiency and convenience. In this paper, we introduce UniCO, a unified model for solving various CO problems. Inspired by the success of next-token prediction, we frame each problem-solving process as a Markov Decision Process (MDP), tokenize the corresponding sequential trajectory data, and train the model using a transformer backbone. To reduce token length in the trajectory data, we propose a CO-prefix design that aggregates static problem features. To address the heterogeneity of state and action tokens within the MDP, we employ a two-stage self-supervised learning approach. In this approach, a dynamic prediction model is first trained and then serves as a pre-trained model for subsequent policy generation. Experiments across 10 CO problems showcase the versatility of UniCO, emphasizing its ability to generalize to new, unseen problems with minimal fine-tuning, achieving even few-shot or zero-shot performance. Our framework offers a valuable complement to existing neural CO methods that focus on optimizing performance for individual problems.
UrbanPlanBench: A Comprehensive Urban Planning Benchmark for Evaluating Large Language Models
Apr 23, 2025
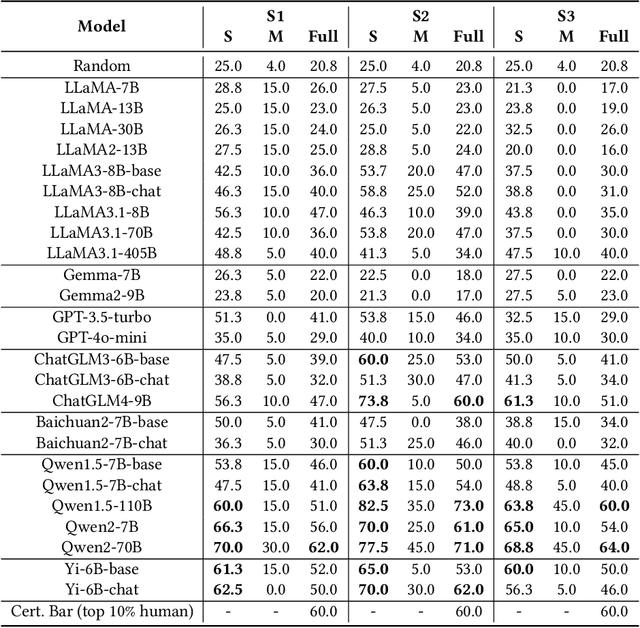


The advent of Large Language Models (LLMs) holds promise for revolutionizing various fields traditionally dominated by human expertise. Urban planning, a professional discipline that fundamentally shapes our daily surroundings, is one such field heavily relying on multifaceted domain knowledge and experience of human experts. The extent to which LLMs can assist human practitioners in urban planning remains largely unexplored. In this paper, we introduce a comprehensive benchmark, UrbanPlanBench, tailored to evaluate the efficacy of LLMs in urban planning, which encompasses fundamental principles, professional knowledge, and management and regulations, aligning closely with the qualifications expected of human planners. Through extensive evaluation, we reveal a significant imbalance in the acquisition of planning knowledge among LLMs, with even the most proficient models falling short of meeting professional standards. For instance, we observe that 70% of LLMs achieve subpar performance in understanding planning regulations compared to other aspects. Besides the benchmark, we present the largest-ever supervised fine-tuning (SFT) dataset, UrbanPlanText, comprising over 30,000 instruction pairs sourced from urban planning exams and textbooks. Our findings demonstrate that fine-tuned models exhibit enhanced performance in memorization tests and comprehension of urban planning knowledge, while there exists significant room for improvement, particularly in tasks requiring domain-specific terminology and reasoning. By making our benchmark, dataset, and associated evaluation and fine-tuning toolsets publicly available at https://github.com/tsinghua-fib-lab/PlanBench, we aim to catalyze the integration of LLMs into practical urban planning, fostering a symbiotic collaboration between human expertise and machine intelligence.
Motion-Aware Generative Frame Interpolation
Jan 07, 2025Generative frame interpolation, empowered by large-scale pre-trained video generation models, has demonstrated remarkable advantages in complex scenes. However, existing methods heavily rely on the generative model to independently infer the correspondences between input frames, an ability that is inadequately developed during pre-training. In this work, we propose a novel framework, termed Motion-aware Generative frame interpolation (MoG), to significantly enhance the model's motion awareness by integrating explicit motion guidance. Specifically we investigate two key questions: what can serve as an effective motion guidance, and how we can seamlessly embed this guidance into the generative model. For the first question, we reveal that the intermediate flow from flow-based interpolation models could efficiently provide task-oriented motion guidance. Regarding the second, we first obtain guidance-based representations of intermediate frames by warping input frames' representations using guidance, and then integrate them into the model at both latent and feature levels. To demonstrate the versatility of our method, we train MoG on both real-world and animation datasets. Comprehensive evaluations show that our MoG significantly outperforms the existing methods in both domains, achieving superior video quality and improved fidelity.