 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUI-Mem: Self-Evolving Experience Memory for Online Reinforcement Learning in Mobile GUI Agents
Feb 05, 2026Online Reinforcement Learning (RL) offers a promising paradigm for enhancing GUI agents through direct environment interaction. However, its effectiveness is severely hindered by inefficient credit assignment in long-horizon tasks and repetitive errors across tasks due to the lack of experience transfer. To address these challenges, we propose UI-Mem, a novel framework that enhances GUI online RL with a Hierarchical Experience Memory. Unlike traditional replay buffers, our memory accumulates structured knowledge, including high-level workflows, subtask skills, and failure patterns. These experiences are stored as parameterized templates that enable cross-task and cross-application transfer. To effectively integrate memory guidance into online RL, we introduce Stratified Group Sampling, which injects varying levels of guidance across trajectories within each rollout group to maintain outcome diversity, driving the unguided policy toward internalizing guided behaviors. Furthermore, a Self-Evolving Loop continuously abstracts novel strategies and errors to keep the memory aligned with the agent's evolving policy. Experiments on online GUI benchmarks demonstrate that UI-Mem significantly outperforms traditional RL baselines and static reuse strategies, with strong generalization to unseen applications. Project page: https://ui-mem.github.io
Bi-directional Bias Attribution: Debiasing Large Language Models without Modifying Prompts
Feb 04, 2026Large language models (LLMs) have demonstrated impressive capabilities across a wide range of natural language processing tasks. However, their outputs often exhibit social biases, raising fairness concerns. Existing debiasing methods, such as fine-tuning on additional datasets or prompt engineering, face scalability issues or compromise user experience in multi-turn interactions. To address these challenges, we propose a framework for detecting stereotype-inducing words and attributing neuron-level bias in LLMs, without the need for fine-tuning or prompt modification. Our framework first identifies stereotype-inducing adjectives and nouns via comparative analysis across demographic groups. We then attribute biased behavior to specific neurons using two attribution strategies based on integrated gradients. Finally, we mitigate bias by directly intervening on their activations at the projection layer. Experiments on three widely used LLMs demonstrate that our method effectively reduces bias while preserving overall model performance. Code is available at the github link: https://github.com/XMUDeepLIT/Bi-directional-Bias-Attribution.
LENS: Learning to Segment Anything with Unified Reinforced Reasoning
Aug 19, 2025Text-prompted image segmentation enables fine-grained visual understanding and is critical for applications such as human-computer interaction and robotics. However, existing supervised fine-tuning methods typically ignore explicit chain-of-thought (CoT) reasoning at test time, which limits their ability to generalize to unseen prompts and domains. To address this issue, we introduce LENS, a scalable reinforcement-learning framework that jointly optimizes the reasoning process and segmentation in an end-to-end manner. We propose unified reinforcement-learning rewards that span sentence-, box-, and segment-level cues, encouraging the model to generate informative CoT rationales while refining mask quality. Using a publicly available 3-billion-parameter vision-language model, i.e., Qwen2.5-VL-3B-Instruct, LENS achieves an average cIoU of 81.2% on the RefCOCO, RefCOCO+, and RefCOCOg benchmarks, outperforming the strong fine-tuned method, i.e., GLaMM, by up to 5.6%. These results demonstrate that RL-driven CoT reasoning serves as a robust prior for text-prompted segmentation and offers a practical path toward more generalizable Segment Anything models. Code is available at https://github.com/hustvl/LENS.
UI-Genie: A Self-Improving Approach for Iteratively Boosting MLLM-based Mobile GUI Agents
May 27, 2025In this paper, we introduce UI-Genie, a self-improving framework addressing two key challenges in GUI agents: verification of trajectory outcome is challenging and high-quality training data are not scalable. These challenges are addressed by a reward model and a self-improving pipeline, respectively. The reward model, UI-Genie-RM, features an image-text interleaved architecture that efficiently pro- cesses historical context and unifies action-level and task-level rewards. To sup- port the training of UI-Genie-RM, we develop deliberately-designed data genera- tion strategies including rule-based verification, controlled trajectory corruption, and hard negative mining. To address the second challenge, a self-improvement pipeline progressively expands solvable complex GUI tasks by enhancing both the agent and reward models through reward-guided exploration and outcome verification in dynamic environments. For training the model, we generate UI- Genie-RM-517k and UI-Genie-Agent-16k, establishing the first reward-specific dataset for GUI agents while demonstrating high-quality synthetic trajectory gen- eration without manual annotation. Experimental results show that UI-Genie achieves state-of-the-art performance across multiple GUI agent benchmarks with three generations of data-model self-improvement. We open-source our complete framework implementation and generated datasets to facilitate further research in https://github.com/Euphoria16/UI-Genie.
Adaptive Markup Language Generation for Contextually-Grounded Visual Document Understanding
May 08, 2025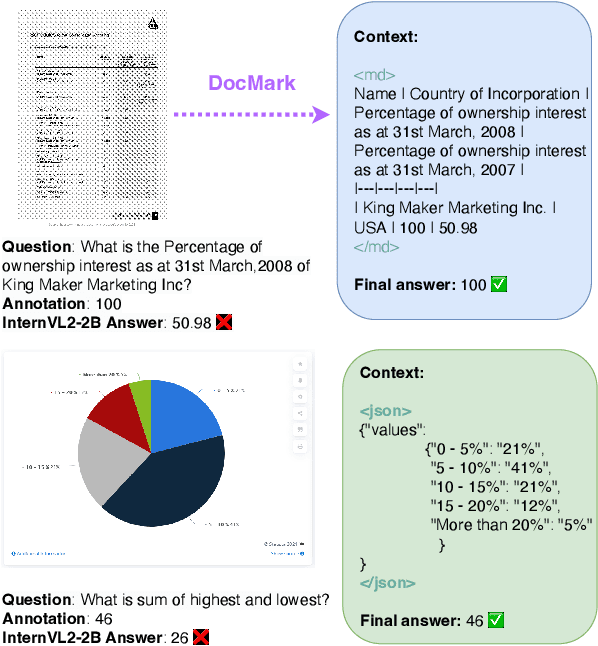
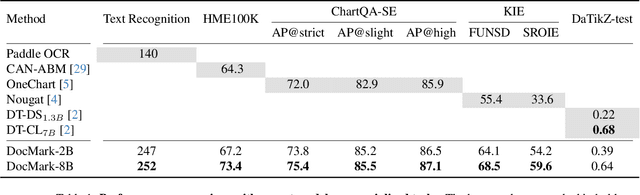
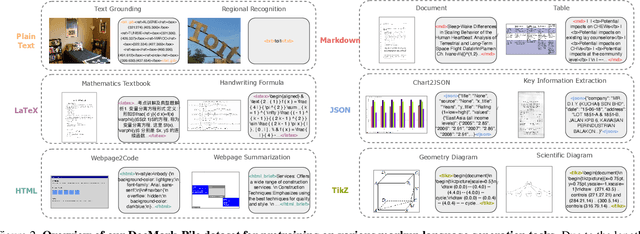
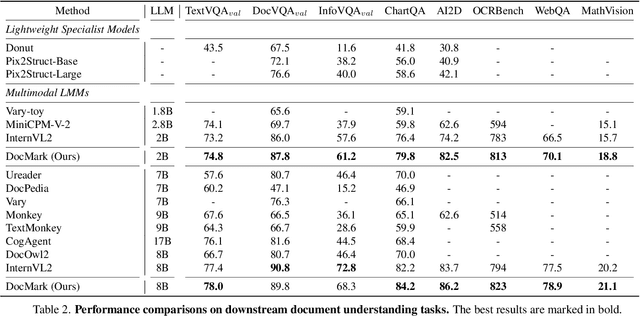
Visual Document Understanding has become essential with the increase of text-rich visual content. This field poses significant challenges due to the need for effective integration of visual perception and textual comprehension, particularly across diverse document types with complex layouts. Moreover, existing fine-tuning datasets for this domain often fall short in providing the detailed contextual information for robust understanding, leading to hallucinations and limited comprehension of spatial relationships among visual elements. To address these challenges, we propose an innovative pipeline that utilizes adaptive generation of markup languages, such as Markdown, JSON, HTML, and TiKZ, to build highly structured document representations and deliver contextually-grounded responses. We introduce two fine-grained structured datasets: DocMark-Pile, comprising approximately 3.8M pretraining data pairs for document parsing, and DocMark-Instruct, featuring 624k fine-tuning data annotations for grounded instruction following. Extensive experiments demonstrate that our proposed model significantly outperforms existing state-of-theart MLLMs across a range of visual document understanding benchmarks, facilitating advanced reasoning and comprehension capabilities in complex visual scenarios. Our code and models are released at https://github. com/Euphoria16/DocMark.
PixelHacker: Image Inpainting with Structural and Semantic Consistency
Apr 30, 2025Image inpainting is a fundamental research area between image editing and image generation. Recent state-of-the-art (SOTA) methods have explored novel attention mechanisms, lightweight architectures, and context-aware modeling, demonstrating impressive performance. However, they often struggle with complex structure (e.g., texture, shape, spatial relations) and semantics (e.g., color consistency, object restoration, and logical correctness), leading to artifacts and inappropriate generation. To address this challenge, we design a simple yet effective inpainting paradigm called latent categories guidance, and further propose a diffusion-based model named PixelHacker. Specifically, we first construct a large dataset containing 14 million image-mask pairs by annotating foreground and background (potential 116 and 21 categories, respectively). Then, we encode potential foreground and background representations separately through two fixed-size embeddings, and intermittently inject these features into the denoising process via linear attention. Finally, by pre-training on our dataset and fine-tuning on open-source benchmarks, we obtain PixelHacker. Extensive experiments show that PixelHacker comprehensively outperforms the SOTA on a wide range of datasets (Places2, CelebA-HQ, and FFHQ) and exhibits remarkable consistency in both structure and semantics. Project page at https://hustvl.github.io/PixelHacker.
EdgeInfinite: A Memory-Efficient Infinite-Context Transformer for Edge Devices
Mar 28, 2025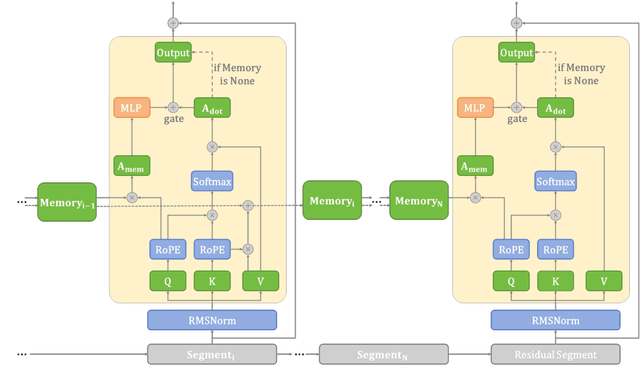
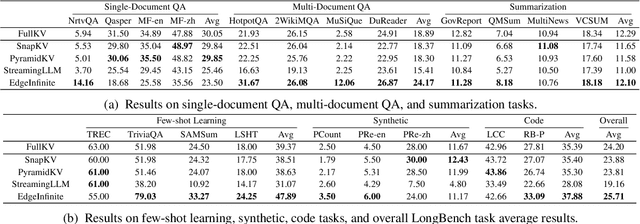
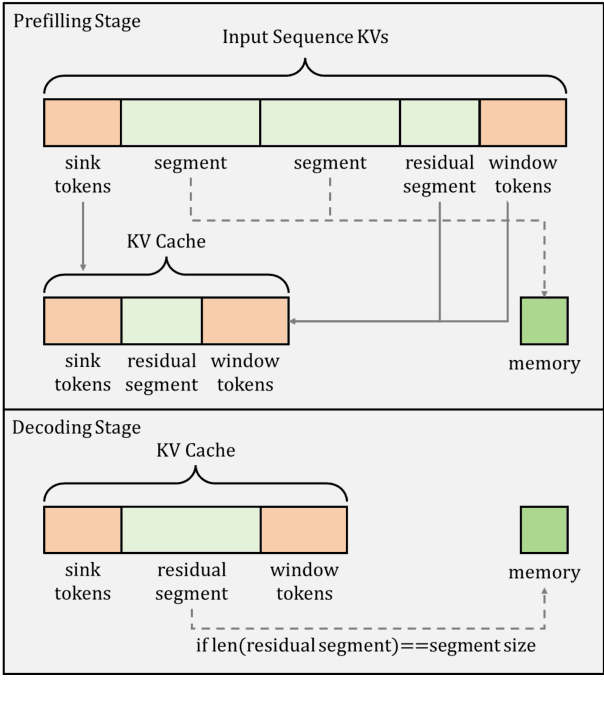
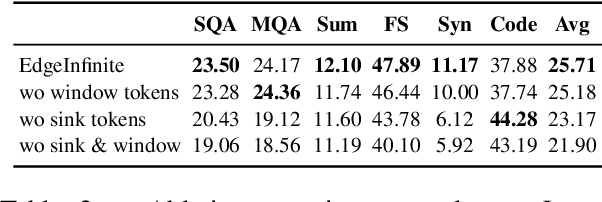
Transformer-based large language models (LLMs) encounter challenges in processing long sequences on edge devices due to the quadratic complexity of attention mechanisms and growing memory demands from Key-Value (KV) cache. Existing KV cache optimizations struggle with irreversible token eviction in long-output tasks, while alternative sequence modeling architectures prove costly to adopt within established Transformer infrastructure. We present EdgeInfinite, a memory-efficient solution for infinite contexts that integrates compressed memory into Transformer-based LLMs through a trainable memory-gating module. This approach maintains full compatibility with standard Transformer architectures, requiring fine-tuning only a small part of parameters, and enables selective activation of the memory-gating module for long and short context task routing. The experimental result shows that EdgeInfinite achieves comparable performance to baseline Transformer-based LLM on long context benchmarks while optimizing memory consumption and time to first token.
GroundingSuite: Measuring Complex Multi-Granular Pixel Grounding
Mar 13, 2025Pixel grounding, encompassing tasks such as Referring Expression Segmentation (RES), has garnered considerable attention due to its immense potential for bridging the gap between vision and language modalities. However, advancements in this domain are currently constrained by limitations inherent in existing datasets, including limited object categories, insufficient textual diversity, and a scarcity of high-quality annotations. To mitigate these limitations, we introduce GroundingSuite, which comprises: (1) an automated data annotation framework leveraging multiple Vision-Language Model (VLM) agents; (2) a large-scale training dataset encompassing 9.56 million diverse referring expressions and their corresponding segmentations; and (3) a meticulously curated evaluation benchmark consisting of 3,800 images. The GroundingSuite training dataset facilitates substantial performance improvements, enabling models trained on it to achieve state-of-the-art results. Specifically, a cIoU of 68.9 on gRefCOCO and a gIoU of 55.3 on RefCOCOm. Moreover, the GroundingSuite annotation framework demonstrates superior efficiency compared to the current leading data annotation method, i.e., $4.5 \times$ faster than the GLaMM.
GenieBlue: Integrating both Linguistic and Multimodal Capabilities for Large Language Models on Mobile Devices
Mar 08, 2025Recent advancements in Multimodal Large Language Models (MLLMs) have enabled their deployment on mobile devices. However, challenges persist in maintaining strong language capabilities and ensuring hardware compatibility, both of which are crucial for user experience and practical deployment efficiency. In our deployment process, we observe that existing MLLMs often face performance degradation on pure language tasks, and the current NPU platforms on smartphones do not support the MoE architecture, which is commonly used to preserve pure language capabilities during multimodal training. To address these issues, we systematically analyze methods to maintain pure language capabilities during the training of MLLMs, focusing on both training data and model architecture aspects. Based on these analyses, we propose GenieBlue, an efficient MLLM structural design that integrates both linguistic and multimodal capabilities for LLMs on mobile devices. GenieBlue freezes the original LLM parameters during MLLM training to maintain pure language capabilities. It acquires multimodal capabilities by duplicating specific transformer blocks for full fine-tuning and integrating lightweight LoRA modules. This approach preserves language capabilities while achieving comparable multimodal performance through extensive training. Deployed on smartphone NPUs, GenieBlue demonstrates efficiency and practicality for applications on mobile devices.
SmartBench: Is Your LLM Truly a Good Chinese Smartphone Assistant?
Mar 08, 2025Large Language Models (LLMs) have become integral to daily life, especially advancing as intelligent assistants through on-device deployment on smartphones. However, existing LLM evaluation benchmarks predominantly focus on objective tasks like mathematics and coding in English, which do not necessarily reflect the practical use cases of on-device LLMs in real-world mobile scenarios, especially for Chinese users. To address these gaps, we introduce SmartBench, the first benchmark designed to evaluate the capabilities of on-device LLMs in Chinese mobile contexts. We analyze functionalities provided by representative smartphone manufacturers and divide them into five categories: text summarization, text Q\&A, information extraction, content creation, and notification management, further detailed into 20 specific tasks. For each task, we construct high-quality datasets comprising 50 to 200 question-answer pairs that reflect everyday mobile interactions, and we develop automated evaluation criteria tailored for these tasks. We conduct comprehensive evaluations of on-device LLMs and MLLMs using SmartBench and also assess their performance after quantized deployment on real smartphone NPUs. Our contributions provide a standardized framework for evaluating on-device LLMs in Chinese, promoting further development and optimization in this critical area. Code and data will be available at https://github.com/Lucky-Lance/SmartBench.