 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWIST: Web-Grounded Iterative Self-Play Tree for Domain-Targeted Reasoning Improvement
Mar 22, 2026Recent progress in reinforcement learning with verifiable rewards (RLVR) offers a practical path to self-improvement of language models, but existing methods face a key trade-off: endogenous self-play can drift over iterations, while corpus-grounded approaches rely on curated data environments. We present \textbf{WIST}, a \textbf{W}eb-grounded \textbf{I}terative \textbf{S}elf-play \textbf{T}ree framework for domain-targeted reasoning improvement that learns directly from the open web without requiring any pre-arranged domain corpus. WIST incrementally expands a domain tree for exploration, and retrieves and cleans path-consistent web corpus to construct a controllable training environment. It then performs Challenger--Solver self-play with verifiable rewards, and feeds learnability signals back to update node posteriors and guide subsequent exploration through an adaptive curriculum. Across four backbones, WIST consistently improves over the base models and typically outperforms both purely endogenous self-evolution and corpus-grounded self-play baselines, with the Overall gains reaching \textbf{+9.8} (\textit{Qwen3-4B-Base}) and \textbf{+9.7} (\textit{OctoThinker-8B}). WIST is also domain-steerable, improving \textit{Qwen3-8B-Base} by \textbf{+14.79} in medicine and \textit{Qwen3-4B-Base} by \textbf{+5.28} on PhyBench. Ablations further confirm the importance of WIST's key components for stable open-web learning. Our Code is available at https://github.com/lfy-123/WIST.
MARTI-MARS$^2$: Scaling Multi-Agent Self-Search via Reinforcement Learning for Code Generation
Feb 08, 2026While the complex reasoning capability of Large Language Models (LLMs) has attracted significant attention, single-agent systems often encounter inherent performance ceilings in complex tasks such as code generation. Multi-agent collaboration offers a promising avenue to transcend these boundaries. However, existing frameworks typically rely on prompt-based test-time interactions or multi-role configurations trained with homogeneous parameters, limiting error correction capabilities and strategic diversity. In this paper, we propose a Multi-Agent Reinforced Training and Inference Framework with Self-Search Scaling (MARTI-MARS2), which integrates policy learning with multi-agent tree search by formulating the multi-agent collaborative exploration process as a dynamic and learnable environment. By allowing agents to iteratively explore and refine within the environment, the framework facilitates evolution from parameter-sharing homogeneous multi-role training to heterogeneous multi-agent training, breaking through single-agent capability limits. We also introduce an efficient inference strategy MARTI-MARS2-T+ to fully exploit the scaling potential of multi-agent collaboration at test time. We conduct extensive experiments across varied model scales (8B, 14B, and 32B) on challenging code generation benchmarks. Utilizing two collaborating 32B models, MARTI-MARS2 achieves 77.7%, outperforming strong baselines like GPT-5.1. Furthermore, MARTI-MARS2 reveals a novel scaling law: shifting from single-agent to homogeneous multi-role and ultimately to heterogeneous multi-agent paradigms progressively yields higher RL performance ceilings, robust TTS capabilities, and greater policy diversity, suggesting that policy diversity is critical for scaling intelligence via multi-agent reinforcement learning.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
EdgeInfinite: A Memory-Efficient Infinite-Context Transformer for Edge Devices
Mar 28, 2025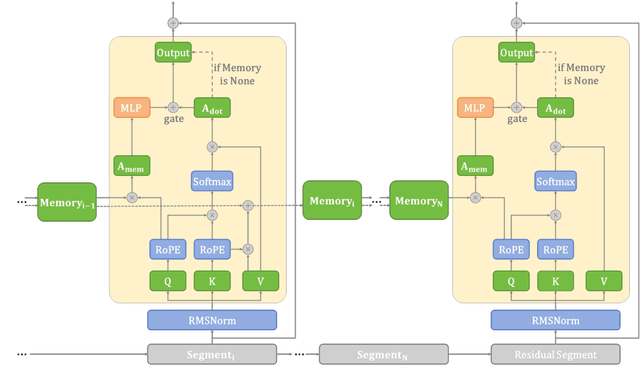
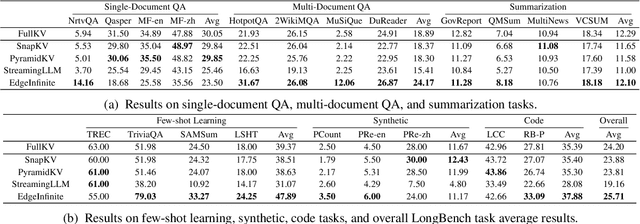
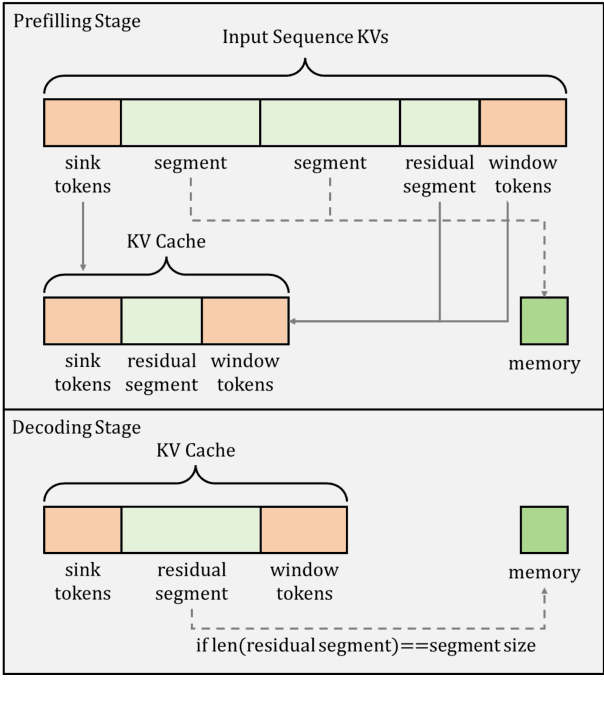
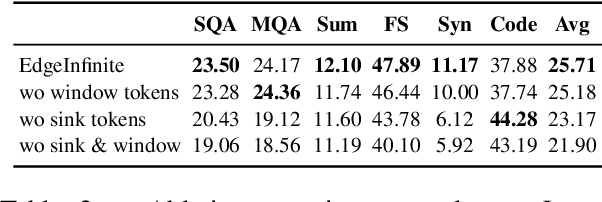
Transformer-based large language models (LLMs) encounter challenges in processing long sequences on edge devices due to the quadratic complexity of attention mechanisms and growing memory demands from Key-Value (KV) cache. Existing KV cache optimizations struggle with irreversible token eviction in long-output tasks, while alternative sequence modeling architectures prove costly to adopt within established Transformer infrastructure. We present EdgeInfinite, a memory-efficient solution for infinite contexts that integrates compressed memory into Transformer-based LLMs through a trainable memory-gating module. This approach maintains full compatibility with standard Transformer architectures, requiring fine-tuning only a small part of parameters, and enables selective activation of the memory-gating module for long and short context task routing. The experimental result shows that EdgeInfinite achieves comparable performance to baseline Transformer-based LLM on long context benchmarks while optimizing memory consumption and time to first token.
SmartBench: Is Your LLM Truly a Good Chinese Smartphone Assistant?
Mar 08, 2025Large Language Models (LLMs) have become integral to daily life, especially advancing as intelligent assistants through on-device deployment on smartphones. However, existing LLM evaluation benchmarks predominantly focus on objective tasks like mathematics and coding in English, which do not necessarily reflect the practical use cases of on-device LLMs in real-world mobile scenarios, especially for Chinese users. To address these gaps, we introduce SmartBench, the first benchmark designed to evaluate the capabilities of on-device LLMs in Chinese mobile contexts. We analyze functionalities provided by representative smartphone manufacturers and divide them into five categories: text summarization, text Q\&A, information extraction, content creation, and notification management, further detailed into 20 specific tasks. For each task, we construct high-quality datasets comprising 50 to 200 question-answer pairs that reflect everyday mobile interactions, and we develop automated evaluation criteria tailored for these tasks. We conduct comprehensive evaluations of on-device LLMs and MLLMs using SmartBench and also assess their performance after quantized deployment on real smartphone NPUs. Our contributions provide a standardized framework for evaluating on-device LLMs in Chinese, promoting further development and optimization in this critical area. Code and data will be available at https://github.com/Lucky-Lance/SmartBench.
GenieBlue: Integrating both Linguistic and Multimodal Capabilities for Large Language Models on Mobile Devices
Mar 08, 2025Recent advancements in Multimodal Large Language Models (MLLMs) have enabled their deployment on mobile devices. However, challenges persist in maintaining strong language capabilities and ensuring hardware compatibility, both of which are crucial for user experience and practical deployment efficiency. In our deployment process, we observe that existing MLLMs often face performance degradation on pure language tasks, and the current NPU platforms on smartphones do not support the MoE architecture, which is commonly used to preserve pure language capabilities during multimodal training. To address these issues, we systematically analyze methods to maintain pure language capabilities during the training of MLLMs, focusing on both training data and model architecture aspects. Based on these analyses, we propose GenieBlue, an efficient MLLM structural design that integrates both linguistic and multimodal capabilities for LLMs on mobile devices. GenieBlue freezes the original LLM parameters during MLLM training to maintain pure language capabilities. It acquires multimodal capabilities by duplicating specific transformer blocks for full fine-tuning and integrating lightweight LoRA modules. This approach preserves language capabilities while achieving comparable multimodal performance through extensive training. Deployed on smartphone NPUs, GenieBlue demonstrates efficiency and practicality for applications on mobile devices.
Fast and Slow Gradient Approximation for Binary Neural Network Optimization
Dec 16, 2024



Binary Neural Networks (BNNs) have garnered significant attention due to their immense potential for deployment on edge devices. However, the non-differentiability of the quantization function poses a challenge for the optimization of BNNs, as its derivative cannot be backpropagated. To address this issue, hypernetwork based methods, which utilize neural networks to learn the gradients of non-differentiable quantization functions, have emerged as a promising approach due to their adaptive learning capabilities to reduce estimation errors. However, existing hypernetwork based methods typically rely solely on current gradient information, neglecting the influence of historical gradients. This oversight can lead to accumulated gradient errors when calculating gradient momentum during optimization. To incorporate historical gradient information, we design a Historical Gradient Storage (HGS) module, which models the historical gradient sequence to generate the first-order momentum required for optimization. To further enhance gradient generation in hypernetworks, we propose a Fast and Slow Gradient Generation (FSG) method. Additionally, to produce more precise gradients, we introduce Layer Recognition Embeddings (LRE) into the hypernetwork, facilitating the generation of layer-specific fine gradients. Extensive comparative experiments on the CIFAR-10 and CIFAR-100 datasets demonstrate that our method achieves faster convergence and lower loss values, outperforming existing baselines.Code is available at http://github.com/two-tiger/FSG .
Less is More: Efficient Model Merging with Binary Task Switch
Nov 24, 2024As an effective approach to equip models with multi-task capabilities without additional training, model merging has garnered significant attention. However, existing methods face challenges of redundant parameter conflicts and the excessive storage burden of parameters. In this work, through controlled experiments, we reveal that for task vectors, only those parameters with magnitudes above a certain threshold contribute positively to the task, exhibiting a pulse-like characteristic. We then attempt leveraging this characteristic to binarize the task vectors and reduce storage overhead. Further controlled experiments show that the binarized task vectors incur almost no decrease in fine-tuning and merging performance, and even exhibit stronger performance improvements as the proportion of redundant parameters increases. Based on these insights, we propose Task Switch (T-Switch), which decomposes task vectors into three components: 1) an activation switch instantiated by a binarized mask vector, 2) a polarity switch instantiated by a binarized sign vector, and 3) a scaling knob instantiated by a scalar coefficient. By storing task vectors in a binarized form, T-Switch alleviates parameter conflicts while ensuring efficient task parameter storage. Furthermore, to enable automated switch combination in T-Switch, we further introduce Auto-Switch, which enables training-free switch combination via retrieval from a small query set. Experiments indicate that our methods achieve significant performance improvements over existing baselines, requiring only 1-3% of the storage space of full-precision parameters.
Online DPO: Online Direct Preference Optimization with Fast-Slow Chasing
Jun 08, 2024Direct Preference Optimization (DPO) improves the alignment of large language models (LLMs) with human values by training directly on human preference datasets, eliminating the need for reward models. However, due to the presence of cross-domain human preferences, direct continual training can lead to catastrophic forgetting, limiting DPO's performance and efficiency. Inspired by intraspecific competition driving species evolution, we propose a Online Fast-Slow chasing DPO (OFS-DPO) for preference alignment, simulating competition through fast and slow chasing among models to facilitate rapid adaptation. Specifically, we first derive the regret upper bound for online learning, validating our motivation with a min-max optimization pattern. Based on this, we introduce two identical modules using Low-rank Adaptive (LoRA) with different optimization speeds to simulate intraspecific competition, and propose a new regularization term to guide their learning. To further mitigate catastrophic forgetting in cross-domain scenarios, we extend the OFS-DPO with LoRA modules combination strategy, resulting in the Cross domain Online Fast-Slow chasing DPO (COFS-DPO). This method leverages linear combinations of fast modules parameters from different task domains, fully utilizing historical information to achive continual value alignment. Experimental results show that OFS-DPO outperforms DPO in in-domain alignment, while COFS-DPO excels in cross-domain continual learning scenarios.