 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOLAR-RL: Semi-Online Long-horizon Assignment Reinforcement Learning
Apr 24, 2026As Multimodal Large Language Models (MLLMs) mature, GUI agents are evolving from static interactions to complex navigation. While Reinforcement Learning (RL) has emerged as a promising paradigm for training MLLM agents on dynamic GUI tasks, its effective application faces a dilemma. Standard Offline RL often relies on static step-level data, neglecting global trajectory semantics such as task completion and execution quality. Conversely, Online RL captures the long-term dynamics but suffers from high interaction costs and potential environmental instability. To bridge this gap, we propose SOLAR-RL (Semi-Online Long-horizon Assignment Reinforcement Learning). Instead of relying solely on expensive online interactions, our framework integrates global trajectory insights directly into the offline learning process. Specifically, we reconstruct diverse rollout candidates from static data, detect the first failure point using per-step validity signals, and retroactively assign dense step-level rewards with target-aligned shaping to reflect trajectory-level execution quality, effectively simulating online feedback without interaction costs. Extensive experiments demonstrate that SOLAR-RL significantly improves long-horizon task completion rates and robustness compared to strong baselines, offering a sample-efficient solution for autonomous GUI navigation.
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents
Apr 12, 2026Reinforcement learning (RL) has been widely used to train LLM agents for multi-turn interactive tasks, but its sample efficiency is severely limited by sparse rewards and long horizons. On-policy self-distillation (OPSD) alleviates this by providing dense token-level supervision from a privileged teacher that has access to ground-truth answers. However, such fixed privileged information cannot capture the diverse valid strategies in agent tasks, and naively combining OPSD with RL often leads to training collapse. To address these limitations, we introduce Skill-SD, a framework that turns the agent's own trajectories into dynamic training-only supervision. Completed trajectories are summarized into compact natural language skills that describe successful behaviors, mistakes, and workflows. These skills serve as dynamic privileged information conditioning only the teacher, while the student always acts under the plain task prompt and learns to internalize the guidance through distillation. To stabilize the training, we derive an importance-weighted reverse-KL loss to provide gradient-correct token-level distillation, and dynamically synchronize the teacher with the improving student. Experimental results on agentic benchmarks demonstrate that Skill-SD substantially outperforms the standard RL baseline, improving both vanilla GRPO (+14.0%/+10.9% on AppWorld/Sokoban) and vanilla OPD (+42.1%/+40.6%). Project page: https://k1xe.github.io/skill-sd/
UI-Mem: Self-Evolving Experience Memory for Online Reinforcement Learning in Mobile GUI Agents
Feb 05, 2026Online Reinforcement Learning (RL) offers a promising paradigm for enhancing GUI agents through direct environment interaction. However, its effectiveness is severely hindered by inefficient credit assignment in long-horizon tasks and repetitive errors across tasks due to the lack of experience transfer. To address these challenges, we propose UI-Mem, a novel framework that enhances GUI online RL with a Hierarchical Experience Memory. Unlike traditional replay buffers, our memory accumulates structured knowledge, including high-level workflows, subtask skills, and failure patterns. These experiences are stored as parameterized templates that enable cross-task and cross-application transfer. To effectively integrate memory guidance into online RL, we introduce Stratified Group Sampling, which injects varying levels of guidance across trajectories within each rollout group to maintain outcome diversity, driving the unguided policy toward internalizing guided behaviors. Furthermore, a Self-Evolving Loop continuously abstracts novel strategies and errors to keep the memory aligned with the agent's evolving policy. Experiments on online GUI benchmarks demonstrate that UI-Mem significantly outperforms traditional RL baselines and static reuse strategies, with strong generalization to unseen applications. Project page: https://ui-mem.github.io
UI-Genie: A Self-Improving Approach for Iteratively Boosting MLLM-based Mobile GUI Agents
May 27, 2025In this paper, we introduce UI-Genie, a self-improving framework addressing two key challenges in GUI agents: verification of trajectory outcome is challenging and high-quality training data are not scalable. These challenges are addressed by a reward model and a self-improving pipeline, respectively. The reward model, UI-Genie-RM, features an image-text interleaved architecture that efficiently pro- cesses historical context and unifies action-level and task-level rewards. To sup- port the training of UI-Genie-RM, we develop deliberately-designed data genera- tion strategies including rule-based verification, controlled trajectory corruption, and hard negative mining. To address the second challenge, a self-improvement pipeline progressively expands solvable complex GUI tasks by enhancing both the agent and reward models through reward-guided exploration and outcome verification in dynamic environments. For training the model, we generate UI- Genie-RM-517k and UI-Genie-Agent-16k, establishing the first reward-specific dataset for GUI agents while demonstrating high-quality synthetic trajectory gen- eration without manual annotation. Experimental results show that UI-Genie achieves state-of-the-art performance across multiple GUI agent benchmarks with three generations of data-model self-improvement. We open-source our complete framework implementation and generated datasets to facilitate further research in https://github.com/Euphoria16/UI-Genie.
Adaptive Markup Language Generation for Contextually-Grounded Visual Document Understanding
May 08, 2025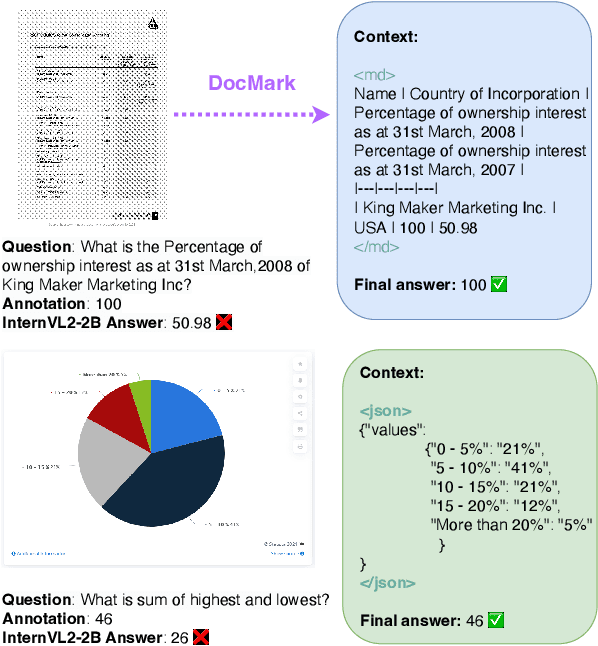
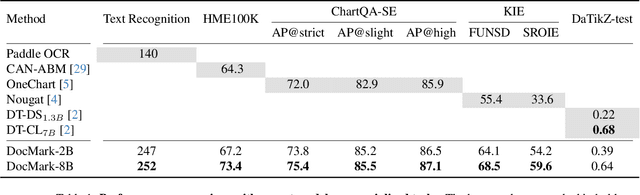
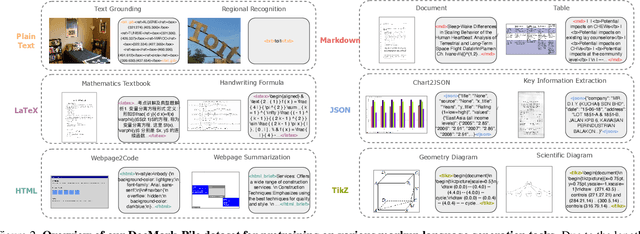
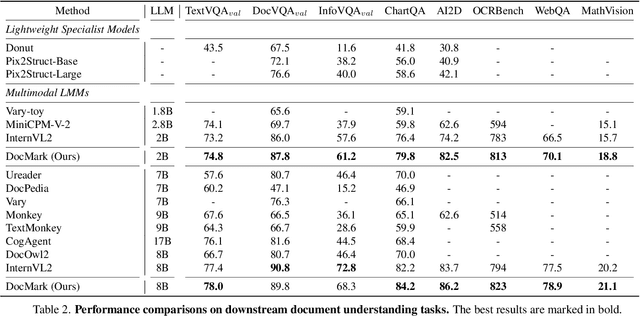
Visual Document Understanding has become essential with the increase of text-rich visual content. This field poses significant challenges due to the need for effective integration of visual perception and textual comprehension, particularly across diverse document types with complex layouts. Moreover, existing fine-tuning datasets for this domain often fall short in providing the detailed contextual information for robust understanding, leading to hallucinations and limited comprehension of spatial relationships among visual elements. To address these challenges, we propose an innovative pipeline that utilizes adaptive generation of markup languages, such as Markdown, JSON, HTML, and TiKZ, to build highly structured document representations and deliver contextually-grounded responses. We introduce two fine-grained structured datasets: DocMark-Pile, comprising approximately 3.8M pretraining data pairs for document parsing, and DocMark-Instruct, featuring 624k fine-tuning data annotations for grounded instruction following. Extensive experiments demonstrate that our proposed model significantly outperforms existing state-of-theart MLLMs across a range of visual document understanding benchmarks, facilitating advanced reasoning and comprehension capabilities in complex visual scenarios. Our code and models are released at https://github. com/Euphoria16/DocMark.
GenieBlue: Integrating both Linguistic and Multimodal Capabilities for Large Language Models on Mobile Devices
Mar 08, 2025Recent advancements in Multimodal Large Language Models (MLLMs) have enabled their deployment on mobile devices. However, challenges persist in maintaining strong language capabilities and ensuring hardware compatibility, both of which are crucial for user experience and practical deployment efficiency. In our deployment process, we observe that existing MLLMs often face performance degradation on pure language tasks, and the current NPU platforms on smartphones do not support the MoE architecture, which is commonly used to preserve pure language capabilities during multimodal training. To address these issues, we systematically analyze methods to maintain pure language capabilities during the training of MLLMs, focusing on both training data and model architecture aspects. Based on these analyses, we propose GenieBlue, an efficient MLLM structural design that integrates both linguistic and multimodal capabilities for LLMs on mobile devices. GenieBlue freezes the original LLM parameters during MLLM training to maintain pure language capabilities. It acquires multimodal capabilities by duplicating specific transformer blocks for full fine-tuning and integrating lightweight LoRA modules. This approach preserves language capabilities while achieving comparable multimodal performance through extensive training. Deployed on smartphone NPUs, GenieBlue demonstrates efficiency and practicality for applications on mobile devices.
BlueLM-V-3B: Algorithm and System Co-Design for Multimodal Large Language Models on Mobile Devices
Nov 16, 2024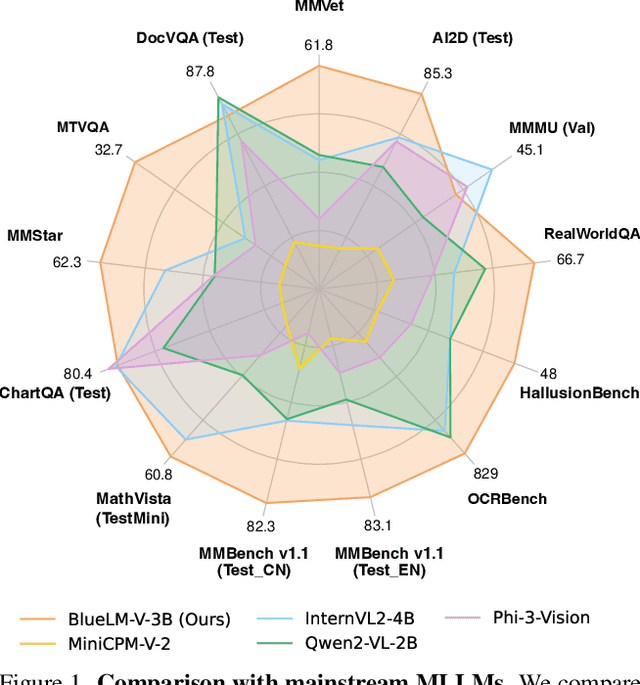
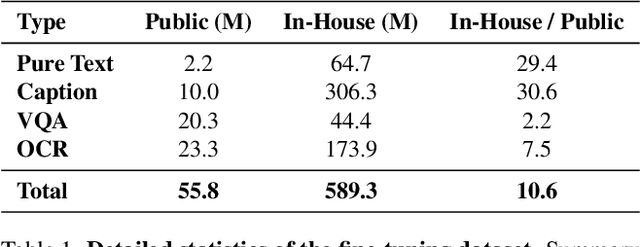
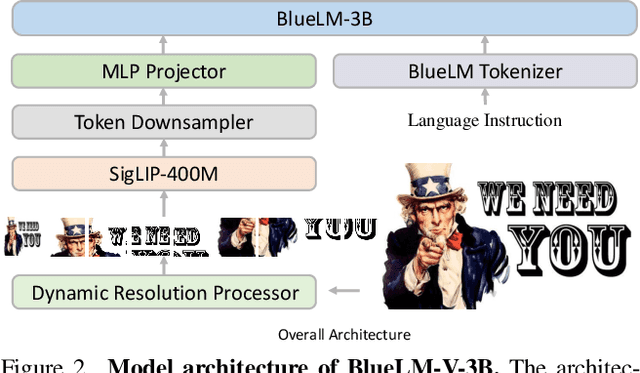

The emergence and growing popularity of multimodal large language models (MLLMs) have significant potential to enhance various aspects of daily life, from improving communication to facilitating learning and problem-solving. Mobile phones, as essential daily companions, represent the most effective and accessible deployment platform for MLLMs, enabling seamless integration into everyday tasks. However, deploying MLLMs on mobile phones presents challenges due to limitations in memory size and computational capability, making it difficult to achieve smooth and real-time processing without extensive optimization. In this paper, we present BlueLM-V-3B, an algorithm and system co-design approach specifically tailored for the efficient deployment of MLLMs on mobile platforms. To be specific, we redesign the dynamic resolution scheme adopted by mainstream MLLMs and implement system optimization for hardware-aware deployment to optimize model inference on mobile phones. BlueLM-V-3B boasts the following key highlights: (1) Small Size: BlueLM-V-3B features a language model with 2.7B parameters and a vision encoder with 400M parameters. (2) Fast Speed: BlueLM-V-3B achieves a generation speed of 24.4 token/s on the MediaTek Dimensity 9300 processor with 4-bit LLM weight quantization. (3) Strong Performance: BlueLM-V-3B has attained the highest average score of 66.1 on the OpenCompass benchmark among models with $\leq$ 4B parameters and surpassed a series of models with much larger parameter sizes (e.g., MiniCPM-V-2.6, InternVL2-8B).
TerDiT: Ternary Diffusion Models with Transformers
May 23, 2024



Recent developments in large-scale pre-trained text-to-image diffusion models have significantly improved the generation of high-fidelity images, particularly with the emergence of diffusion models based on transformer architecture (DiTs). Among these diffusion models, diffusion transformers have demonstrated superior image generation capabilities, boosting lower FID scores and higher scalability. However, deploying large-scale DiT models can be expensive due to their extensive parameter numbers. Although existing research has explored efficient deployment techniques for diffusion models such as model quantization, there is still little work concerning DiT-based models. To tackle this research gap, in this paper, we propose TerDiT, a quantization-aware training (QAT) and efficient deployment scheme for ternary diffusion models with transformers. We focus on the ternarization of DiT networks and scale model sizes from 600M to 4.2B. Our work contributes to the exploration of efficient deployment strategies for large-scale DiT models, demonstrating the feasibility of training extremely low-bit diffusion transformer models from scratch while maintaining competitive image generation capacities compared to full-precision models. Code will be available at https://github.com/Lucky-Lance/TerDiT.
GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning
Nov 21, 2023Recent advances in text-to-video generation have harnessed the power of diffusion models to create visually compelling content conditioned on text prompts. However, they usually encounter high computational costs and often struggle to produce videos with coherent physical motions. To tackle these issues, we propose GPT4Motion, a training-free framework that leverages the planning capability of large language models such as GPT, the physical simulation strength of Blender, and the excellent image generation ability of text-to-image diffusion models to enhance the quality of video synthesis. Specifically, GPT4Motion employs GPT-4 to generate a Blender script based on a user textual prompt, which commands Blender's built-in physics engine to craft fundamental scene components that encapsulate coherent physical motions across frames. Then these components are inputted into Stable Diffusion to generate a video aligned with the textual prompt. Experimental results on three basic physical motion scenarios, including rigid object drop and collision, cloth draping and swinging, and liquid flow, demonstrate that GPT4Motion can generate high-quality videos efficiently in maintaining motion coherency and entity consistency. GPT4Motion offers new insights in text-to-video research, enhancing its quality and broadening its horizon for future explorations.
ImageBind-LLM: Multi-modality Instruction Tuning
Sep 11, 2023
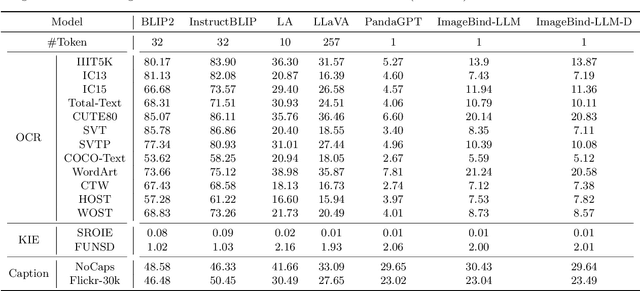
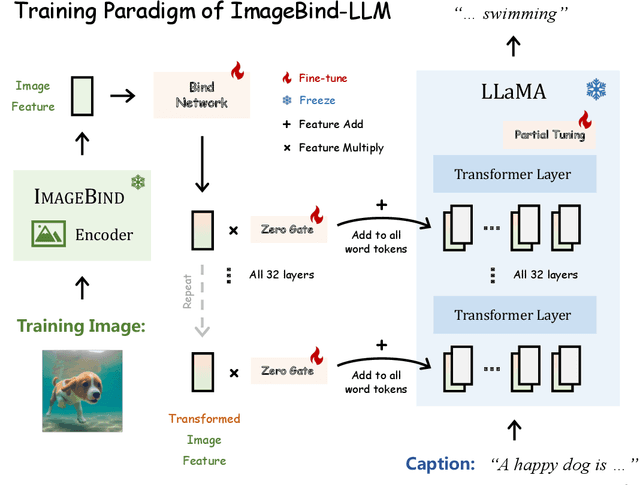
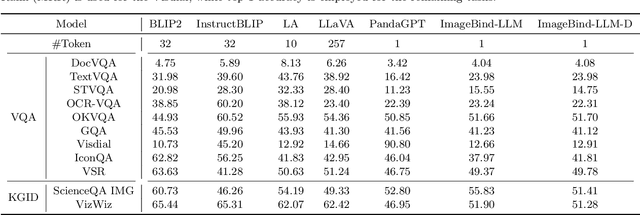
We present ImageBind-LLM, a multi-modality instruction tuning method of large language models (LLMs) via ImageBind. Existing works mainly focus on language and image instruction tuning, different from which, our ImageBind-LLM can respond to multi-modality conditions, including audio, 3D point clouds, video, and their embedding-space arithmetic by only image-text alignment training. During training, we adopt a learnable bind network to align the embedding space between LLaMA and ImageBind's image encoder. Then, the image features transformed by the bind network are added to word tokens of all layers in LLaMA, which progressively injects visual instructions via an attention-free and zero-initialized gating mechanism. Aided by the joint embedding of ImageBind, the simple image-text training enables our model to exhibit superior multi-modality instruction-following capabilities. During inference, the multi-modality inputs are fed into the corresponding ImageBind encoders, and processed by a proposed visual cache model for further cross-modal embedding enhancement. The training-free cache model retrieves from three million image features extracted by ImageBind, which effectively mitigates the training-inference modality discrepancy. Notably, with our approach, ImageBind-LLM can respond to instructions of diverse modalities and demonstrate significant language generation quality. Code is released at https://github.com/OpenGVLab/LLaMA-Adapter.