 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDOL: Instant Photorealistic 3D Human Creation from a Single Image
Dec 19, 2024



Creating a high-fidelity, animatable 3D full-body avatar from a single image is a challenging task due to the diverse appearance and poses of humans and the limited availability of high-quality training data. To achieve fast and high-quality human reconstruction, this work rethinks the task from the perspectives of dataset, model, and representation. First, we introduce a large-scale HUman-centric GEnerated dataset, HuGe100K, consisting of 100K diverse, photorealistic sets of human images. Each set contains 24-view frames in specific human poses, generated using a pose-controllable image-to-multi-view model. Next, leveraging the diversity in views, poses, and appearances within HuGe100K, we develop a scalable feed-forward transformer model to predict a 3D human Gaussian representation in a uniform space from a given human image. This model is trained to disentangle human pose, body shape, clothing geometry, and texture. The estimated Gaussians can be animated without post-processing. We conduct comprehensive experiments to validate the effectiveness of the proposed dataset and method. Our model demonstrates the ability to efficiently reconstruct photorealistic humans at 1K resolution from a single input image using a single GPU instantly. Additionally, it seamlessly supports various applications, as well as shape and texture editing tasks.
Diffusion Model-Based Image Editing: A Survey
Feb 27, 2024



Denoising diffusion models have emerged as a powerful tool for various image generation and editing tasks, facilitating the synthesis of visual content in an unconditional or input-conditional manner. The core idea behind them is learning to reverse the process of gradually adding noise to images, allowing them to generate high-quality samples from a complex distribution. In this survey, we provide an exhaustive overview of existing methods using diffusion models for image editing, covering both theoretical and practical aspects in the field. We delve into a thorough analysis and categorization of these works from multiple perspectives, including learning strategies, user-input conditions, and the array of specific editing tasks that can be accomplished. In addition, we pay special attention to image inpainting and outpainting, and explore both earlier traditional context-driven and current multimodal conditional methods, offering a comprehensive analysis of their methodologies. To further evaluate the performance of text-guided image editing algorithms, we propose a systematic benchmark, EditEval, featuring an innovative metric, LMM Score. Finally, we address current limitations and envision some potential directions for future research. The accompanying repository is released at https://github.com/SiatMMLab/Awesome-Diffusion-Model-Based-Image-Editing-Methods.
GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning
Nov 21, 2023Recent advances in text-to-video generation have harnessed the power of diffusion models to create visually compelling content conditioned on text prompts. However, they usually encounter high computational costs and often struggle to produce videos with coherent physical motions. To tackle these issues, we propose GPT4Motion, a training-free framework that leverages the planning capability of large language models such as GPT, the physical simulation strength of Blender, and the excellent image generation ability of text-to-image diffusion models to enhance the quality of video synthesis. Specifically, GPT4Motion employs GPT-4 to generate a Blender script based on a user textual prompt, which commands Blender's built-in physics engine to craft fundamental scene components that encapsulate coherent physical motions across frames. Then these components are inputted into Stable Diffusion to generate a video aligned with the textual prompt. Experimental results on three basic physical motion scenarios, including rigid object drop and collision, cloth draping and swinging, and liquid flow, demonstrate that GPT4Motion can generate high-quality videos efficiently in maintaining motion coherency and entity consistency. GPT4Motion offers new insights in text-to-video research, enhancing its quality and broadening its horizon for future explorations.
Graph Edit Distance Learning via Different Attention
Aug 26, 2023Recently, more and more research has focused on using Graph Neural Networks (GNN) to solve the Graph Similarity Computation problem (GSC), i.e., computing the Graph Edit Distance (GED) between two graphs. These methods treat GSC as an end-to-end learnable task, and the core of their architecture is the feature fusion modules to interact with the features of two graphs. Existing methods consider that graph-level embedding is difficult to capture the differences in local small structures between two graphs, and thus perform fine-grained feature fusion on node-level embedding can improve the accuracy, but leads to greater time and memory consumption in the training and inference phases. However, this paper proposes a novel graph-level fusion module Different Attention (DiffAtt), and demonstrates that graph-level fusion embeddings can substantially outperform these complex node-level fusion embeddings. We posit that the relative difference structure of the two graphs plays an important role in calculating their GED values. To this end, DiffAtt uses the difference between two graph-level embeddings as an attentional mechanism to capture the graph structural difference of the two graphs. Based on DiffAtt, a new GSC method, named Graph Edit Distance Learning via Different Attention (REDRAFT), is proposed, and experimental results demonstrate that REDRAFT achieves state-of-the-art performance in 23 out of 25 metrics in five benchmark datasets. Especially on MSE, it respectively outperforms the second best by 19.9%, 48.8%, 29.1%, 31.6%, and 2.2%. Moreover, we propose a quantitative test Remaining Subgraph Alignment Test (RESAT) to verify that among all graph-level fusion modules, the fusion embedding generated by DiffAtt can best capture the structural differences between two graphs.
WaveDM: Wavelet-Based Diffusion Models for Image Restoration
May 23, 2023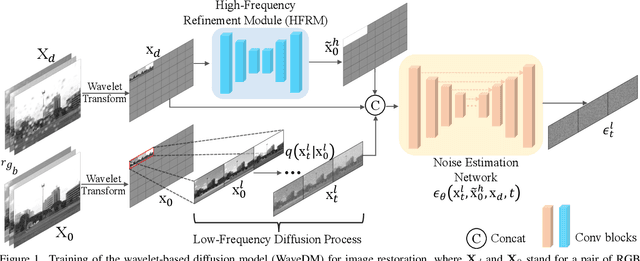
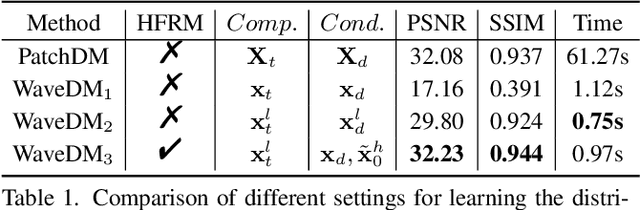
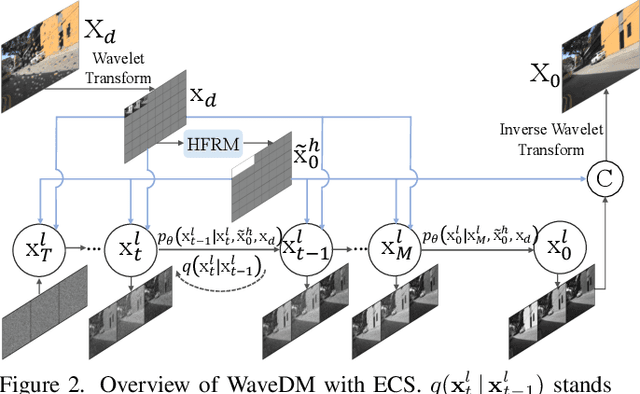
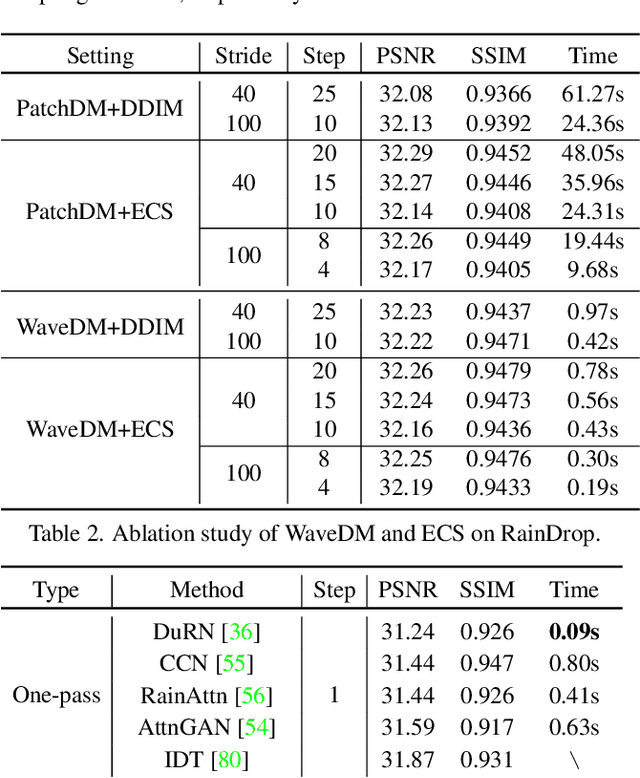
Latest diffusion-based methods for many image restoration tasks outperform traditional models, but they encounter the long-time inference problem. To tackle it, this paper proposes a Wavelet-Based Diffusion Model (WaveDM) with an Efficient Conditional Sampling (ECS) strategy. WaveDM learns the distribution of clean images in the wavelet domain conditioned on the wavelet spectrum of degraded images after wavelet transform, which is more time-saving in each step of sampling than modeling in the spatial domain. In addition, ECS follows the same procedure as the deterministic implicit sampling in the initial sampling period and then stops to predict clean images directly, which reduces the number of total sampling steps to around 5. Evaluations on four benchmark datasets including image raindrop removal, defocus deblurring, demoir\'eing, and denoising demonstrate that WaveDM achieves state-of-the-art performance with the efficiency that is comparable to traditional one-pass methods and over 100 times faster than existing image restoration methods using vanilla diffusion models.