 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Steering: Learning with a Reference Model Improves Generalization Bounds and Scaling Laws
May 13, 2025This paper formalizes an emerging learning paradigm that uses a trained model as a reference to guide and enhance the training of a target model through strategic data selection or weighting, named $\textbf{model steering}$. While ad-hoc methods have been used in various contexts, including the training of large foundation models, its underlying principles remain insufficiently understood, leading to sub-optimal performance. In this work, we propose a theory-driven framework for model steering called $\textbf{DRRho risk minimization}$, which is rooted in Distributionally Robust Optimization (DRO). Through a generalization analysis, we provide theoretical insights into why this approach improves generalization and data efficiency compared to training without a reference model. To the best of our knowledge, this is the first time such theoretical insights are provided for the new learning paradigm, which significantly enhance our understanding and practice of model steering. Building on these insights and the connection between contrastive learning and DRO, we introduce a novel method for Contrastive Language-Image Pretraining (CLIP) with a reference model, termed DRRho-CLIP. Extensive experiments validate the theoretical insights, reveal a superior scaling law compared to CLIP without a reference model, and demonstrate its strength over existing heuristic approaches.
Cavia: Camera-controllable Multi-view Video Diffusion with View-Integrated Attention
Oct 14, 2024In recent years there have been remarkable breakthroughs in image-to-video generation. However, the 3D consistency and camera controllability of generated frames have remained unsolved. Recent studies have attempted to incorporate camera control into the generation process, but their results are often limited to simple trajectories or lack the ability to generate consistent videos from multiple distinct camera paths for the same scene. To address these limitations, we introduce Cavia, a novel framework for camera-controllable, multi-view video generation, capable of converting an input image into multiple spatiotemporally consistent videos. Our framework extends the spatial and temporal attention modules into view-integrated attention modules, improving both viewpoint and temporal consistency. This flexible design allows for joint training with diverse curated data sources, including scene-level static videos, object-level synthetic multi-view dynamic videos, and real-world monocular dynamic videos. To our best knowledge, Cavia is the first of its kind that allows the user to precisely specify camera motion while obtaining object motion. Extensive experiments demonstrate that Cavia surpasses state-of-the-art methods in terms of geometric consistency and perceptual quality. Project Page: https://ir1d.github.io/Cavia/
MMCOMPOSITION: Revisiting the Compositionality of Pre-trained Vision-Language Models
Oct 13, 2024



The advent of large Vision-Language Models (VLMs) has significantly advanced multimodal understanding, enabling more sophisticated and accurate integration of visual and textual information across various tasks, including image and video captioning, visual question answering, and cross-modal retrieval. Despite VLMs' superior capabilities, researchers lack a comprehensive understanding of their compositionality -- the ability to understand and produce novel combinations of known visual and textual components. Prior benchmarks provide only a relatively rough compositionality evaluation from the perspectives of objects, relations, and attributes while neglecting deeper reasoning about object interactions, counting, and complex compositions. However, compositionality is a critical ability that facilitates coherent reasoning and understanding across modalities for VLMs. To address this limitation, we propose MMCOMPOSITION, a novel human-annotated benchmark for comprehensively and accurately evaluating VLMs' compositionality. Our proposed benchmark serves as a complement to these earlier works. With MMCOMPOSITION, we can quantify and explore the compositionality of the mainstream VLMs. Surprisingly, we find GPT-4o's compositionality inferior to the best open-source model, and we analyze the underlying reasons. Our experimental analysis reveals the limitations of VLMs in fine-grained compositional perception and reasoning, and points to areas for improvement in VLM design and training. Resources available at: https://hanghuacs.github.io/MMComposition/
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Diffusion Model-Based Image Editing: A Survey
Feb 27, 2024



Denoising diffusion models have emerged as a powerful tool for various image generation and editing tasks, facilitating the synthesis of visual content in an unconditional or input-conditional manner. The core idea behind them is learning to reverse the process of gradually adding noise to images, allowing them to generate high-quality samples from a complex distribution. In this survey, we provide an exhaustive overview of existing methods using diffusion models for image editing, covering both theoretical and practical aspects in the field. We delve into a thorough analysis and categorization of these works from multiple perspectives, including learning strategies, user-input conditions, and the array of specific editing tasks that can be accomplished. In addition, we pay special attention to image inpainting and outpainting, and explore both earlier traditional context-driven and current multimodal conditional methods, offering a comprehensive analysis of their methodologies. To further evaluate the performance of text-guided image editing algorithms, we propose a systematic benchmark, EditEval, featuring an innovative metric, LMM Score. Finally, we address current limitations and envision some potential directions for future research. The accompanying repository is released at https://github.com/SiatMMLab/Awesome-Diffusion-Model-Based-Image-Editing-Methods.
Efficient-NeRF2NeRF: Streamlining Text-Driven 3D Editing with Multiview Correspondence-Enhanced Diffusion Models
Dec 26, 2023



The advancement of text-driven 3D content editing has been blessed by the progress from 2D generative diffusion models. However, a major obstacle hindering the widespread adoption of 3D content editing is its time-intensive processing. This challenge arises from the iterative and refining steps required to achieve consistent 3D outputs from 2D image-based generative models. Recent state-of-the-art methods typically require optimization time ranging from tens of minutes to several hours to edit a 3D scene using a single GPU. In this work, we propose that by incorporating correspondence regularization into diffusion models, the process of 3D editing can be significantly accelerated. This approach is inspired by the notion that the estimated samples during diffusion should be multiview-consistent during the diffusion generation process. By leveraging this multiview consistency, we can edit 3D content at a much faster speed. In most scenarios, our proposed technique brings a 10$\times$ speed-up compared to the baseline method and completes the editing of a 3D scene in 2 minutes with comparable quality.
Ferret: Refer and Ground Anything Anywhere at Any Granularity
Oct 11, 2023



We introduce Ferret, a new Multimodal Large Language Model (MLLM) capable of understanding spatial referring of any shape or granularity within an image and accurately grounding open-vocabulary descriptions. To unify referring and grounding in the LLM paradigm, Ferret employs a novel and powerful hybrid region representation that integrates discrete coordinates and continuous features jointly to represent a region in the image. To extract the continuous features of versatile regions, we propose a spatial-aware visual sampler, adept at handling varying sparsity across different shapes. Consequently, Ferret can accept diverse region inputs, such as points, bounding boxes, and free-form shapes. To bolster the desired capability of Ferret, we curate GRIT, a comprehensive refer-and-ground instruction tuning dataset including 1.1M samples that contain rich hierarchical spatial knowledge, with 95K hard negative data to promote model robustness. The resulting model not only achieves superior performance in classical referring and grounding tasks, but also greatly outperforms existing MLLMs in region-based and localization-demanded multimodal chatting. Our evaluations also reveal a significantly improved capability of describing image details and a remarkable alleviation in object hallucination. Code and data will be available at https://github.com/apple/ml-ferret
Efficient-3DiM: Learning a Generalizable Single-image Novel-view Synthesizer in One Day
Oct 04, 2023

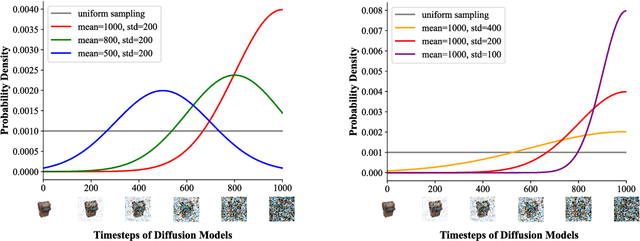
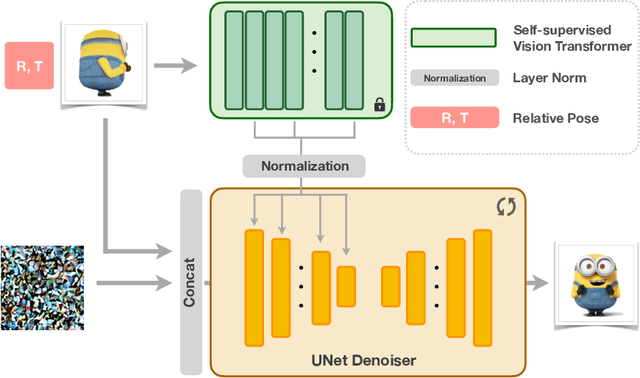
The task of novel view synthesis aims to generate unseen perspectives of an object or scene from a limited set of input images. Nevertheless, synthesizing novel views from a single image still remains a significant challenge in the realm of computer vision. Previous approaches tackle this problem by adopting mesh prediction, multi-plain image construction, or more advanced techniques such as neural radiance fields. Recently, a pre-trained diffusion model that is specifically designed for 2D image synthesis has demonstrated its capability in producing photorealistic novel views, if sufficiently optimized on a 3D finetuning task. Although the fidelity and generalizability are greatly improved, training such a powerful diffusion model requires a vast volume of training data and model parameters, resulting in a notoriously long time and high computational costs. To tackle this issue, we propose Efficient-3DiM, a simple but effective framework to learn a single-image novel-view synthesizer. Motivated by our in-depth analysis of the inference process of diffusion models, we propose several pragmatic strategies to reduce the training overhead to a manageable scale, including a crafted timestep sampling strategy, a superior 3D feature extractor, and an enhanced training scheme. When combined, our framework is able to reduce the total training time from 10 days to less than 1 day, significantly accelerating the training process under the same computational platform (one instance with 8 Nvidia A100 GPUs). Comprehensive experiments are conducted to demonstrate the efficiency and generalizability of our proposed method.
Instruction-Following Speech Recognition
Sep 18, 2023Conventional end-to-end Automatic Speech Recognition (ASR) models primarily focus on exact transcription tasks, lacking flexibility for nuanced user interactions. With the advent of Large Language Models (LLMs) in speech processing, more organic, text-prompt-based interactions have become possible. However, the mechanisms behind these models' speech understanding and "reasoning" capabilities remain underexplored. To study this question from the data perspective, we introduce instruction-following speech recognition, training a Listen-Attend-Spell model to understand and execute a diverse set of free-form text instructions. This enables a multitude of speech recognition tasks -- ranging from transcript manipulation to summarization -- without relying on predefined command sets. Remarkably, our model, trained from scratch on Librispeech, interprets and executes simple instructions without requiring LLMs or pre-trained speech modules. It also offers selective transcription options based on instructions like "transcribe first half and then turn off listening," providing an additional layer of privacy and safety compared to existing LLMs. Our findings highlight the significant potential of instruction-following training to advance speech foundation models.
RoomDreamer: Text-Driven 3D Indoor Scene Synthesis with Coherent Geometry and Texture
May 18, 2023



The techniques for 3D indoor scene capturing are widely used, but the meshes produced leave much to be desired. In this paper, we propose "RoomDreamer", which leverages powerful natural language to synthesize a new room with a different style. Unlike existing image synthesis methods, our work addresses the challenge of synthesizing both geometry and texture aligned to the input scene structure and prompt simultaneously. The key insight is that a scene should be treated as a whole, taking into account both scene texture and geometry. The proposed framework consists of two significant components: Geometry Guided Diffusion and Mesh Optimization. Geometry Guided Diffusion for 3D Scene guarantees the consistency of the scene style by applying the 2D prior to the entire scene simultaneously. Mesh Optimization improves the geometry and texture jointly and eliminates the artifacts in the scanned scene. To validate the proposed method, real indoor scenes scanned with smartphones are used for extensive experiments, through which the effectiveness of our method is demonstrated.