 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking Turns: Benchmarking Audio Foundation Models on Turn-Taking Dynamics
Mar 03, 2025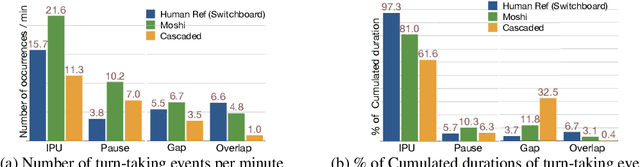

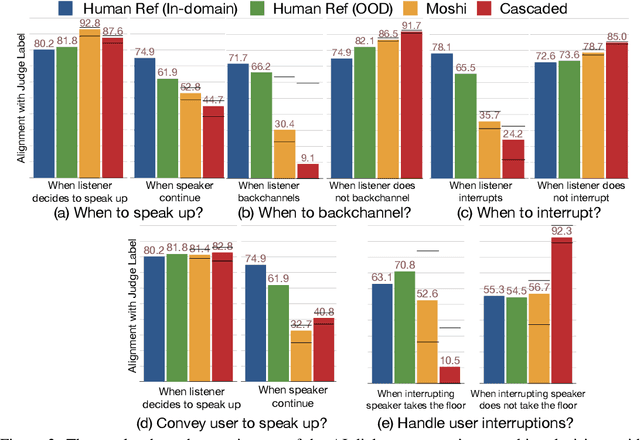

The recent wave of audio foundation models (FMs) could provide new capabilities for conversational modeling. However, there have been limited efforts to evaluate these audio FMs comprehensively on their ability to have natural and interactive conversations. To engage in meaningful conversation with the end user, we would want the FMs to additionally perform a fluent succession of turns without too much overlapping speech or long stretches of silence. Inspired by this, we ask whether the recently proposed audio FMs can understand, predict, and perform turn-taking events? To answer this, we propose a novel evaluation protocol that can assess spoken dialog system's turn-taking capabilities using a supervised model as a judge that has been trained to predict turn-taking events in human-human conversations. Using this protocol, we present the first comprehensive user study that evaluates existing spoken dialogue systems on their ability to perform turn-taking events and reveal many interesting insights, such as they sometimes do not understand when to speak up, can interrupt too aggressively and rarely backchannel. We further evaluate multiple open-source and proprietary audio FMs accessible through APIs on carefully curated test benchmarks from Switchboard to measure their ability to understand and predict turn-taking events and identify significant room for improvement. We will open source our evaluation platform to promote the development of advanced conversational AI systems.
TIS-DPO: Token-level Importance Sampling for Direct Preference Optimization With Estimated Weights
Oct 06, 2024

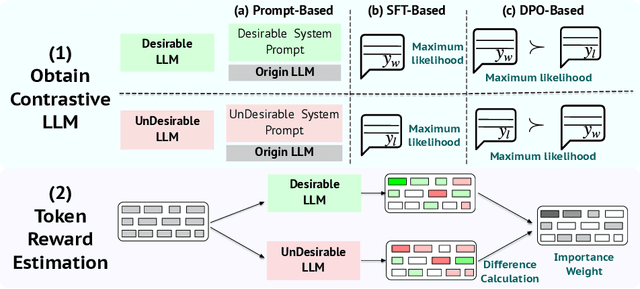
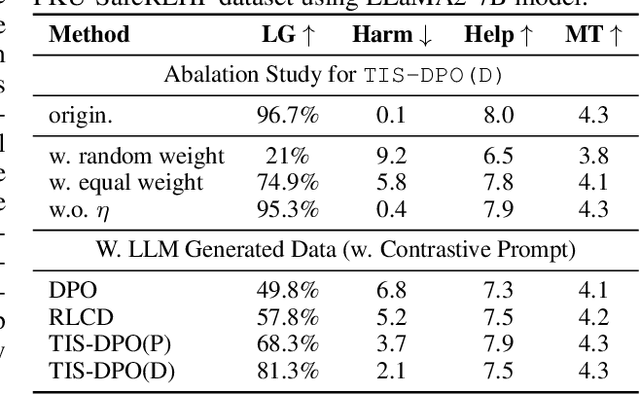
Direct Preference Optimization (DPO) has been widely adopted for preference alignment of Large Language Models (LLMs) due to its simplicity and effectiveness. However, DPO is derived as a bandit problem in which the whole response is treated as a single arm, ignoring the importance differences between tokens, which may affect optimization efficiency and make it difficult to achieve optimal results. In this work, we propose that the optimal data for DPO has equal expected rewards for each token in winning and losing responses, as there is no difference in token importance. However, since the optimal dataset is unavailable in practice, we propose using the original dataset for importance sampling to achieve unbiased optimization. Accordingly, we propose a token-level importance sampling DPO objective named TIS-DPO that assigns importance weights to each token based on its reward. Inspired by previous works, we estimate the token importance weights using the difference in prediction probabilities from a pair of contrastive LLMs. We explore three methods to construct these contrastive LLMs: (1) guiding the original LLM with contrastive prompts, (2) training two separate LLMs using winning and losing responses, and (3) performing forward and reverse DPO training with winning and losing responses. Experiments show that TIS-DPO significantly outperforms various baseline methods on harmlessness and helpfulness alignment and summarization tasks. We also visualize the estimated weights, demonstrating their ability to identify key token positions.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Direct Large Language Model Alignment Through Self-Rewarding Contrastive Prompt Distillation
Feb 19, 2024



Aligning large language models (LLMs) with human expectations without human-annotated preference data is an important problem. In this paper, we propose a method to evaluate the response preference by using the output probabilities of response pairs under contrastive prompt pairs, which could achieve better performance on LLaMA2-7B and LLaMA2-13B compared to RLAIF. Based on this, we propose an automatic alignment method, Direct Large Model Alignment (DLMA). First, we use contrastive prompt pairs to automatically generate preference data. Then, we continue to evaluate the generated preference data using contrastive prompt pairs and calculate a self-rewarding score. Finally, we use the DPO algorithm to effectively align LLMs by combining this self-rewarding score. In the experimental stage, our DLMA method could surpass the \texttt{RLHF} method without relying on human-annotated preference data.
Instruction-Following Speech Recognition
Sep 18, 2023Conventional end-to-end Automatic Speech Recognition (ASR) models primarily focus on exact transcription tasks, lacking flexibility for nuanced user interactions. With the advent of Large Language Models (LLMs) in speech processing, more organic, text-prompt-based interactions have become possible. However, the mechanisms behind these models' speech understanding and "reasoning" capabilities remain underexplored. To study this question from the data perspective, we introduce instruction-following speech recognition, training a Listen-Attend-Spell model to understand and execute a diverse set of free-form text instructions. This enables a multitude of speech recognition tasks -- ranging from transcript manipulation to summarization -- without relying on predefined command sets. Remarkably, our model, trained from scratch on Librispeech, interprets and executes simple instructions without requiring LLMs or pre-trained speech modules. It also offers selective transcription options based on instructions like "transcribe first half and then turn off listening," providing an additional layer of privacy and safety compared to existing LLMs. Our findings highlight the significant potential of instruction-following training to advance speech foundation models.
Less is More: Removing Text-regions Improves CLIP Training Efficiency and Robustness
May 08, 2023



The CLIP (Contrastive Language-Image Pre-training) model and its variants are becoming the de facto backbone in many applications. However, training a CLIP model from hundreds of millions of image-text pairs can be prohibitively expensive. Furthermore, the conventional CLIP model doesn't differentiate between the visual semantics and meaning of text regions embedded in images. This can lead to non-robustness when the text in the embedded region doesn't match the image's visual appearance. In this paper, we discuss two effective approaches to improve the efficiency and robustness of CLIP training: (1) augmenting the training dataset while maintaining the same number of optimization steps, and (2) filtering out samples that contain text regions in the image. By doing so, we significantly improve the classification and retrieval accuracy on public benchmarks like ImageNet and CoCo. Filtering out images with text regions also protects the model from typographic attacks. To verify this, we build a new dataset named ImageNet with Adversarial Text Regions (ImageNet-Attr). Our filter-based CLIP model demonstrates a top-1 accuracy of 68.78\%, outperforming previous models whose accuracy was all below 50\%.
E2E Segmenter: Joint Segmenting and Decoding for Long-Form ASR
Apr 22, 2022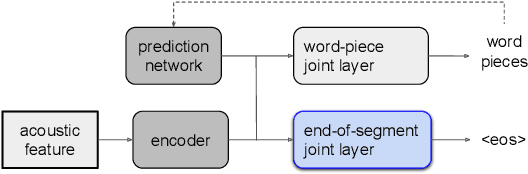
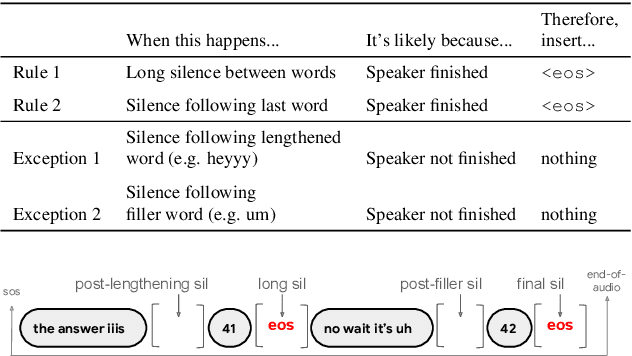
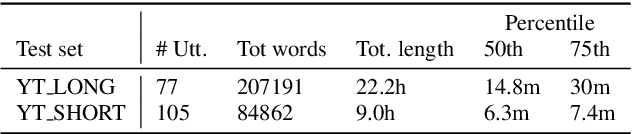
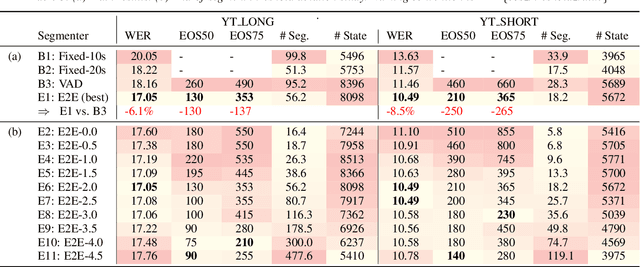
Improving the performance of end-to-end ASR models on long utterances ranging from minutes to hours in length is an ongoing challenge in speech recognition. A common solution is to segment the audio in advance using a separate voice activity detector (VAD) that decides segment boundary locations based purely on acoustic speech/non-speech information. VAD segmenters, however, may be sub-optimal for real-world speech where, e.g., a complete sentence that should be taken as a whole may contain hesitations in the middle ("set an alarm for... 5 o'clock"). We propose to replace the VAD with an end-to-end ASR model capable of predicting segment boundaries in a streaming fashion, allowing the segmentation decision to be conditioned not only on better acoustic features but also on semantic features from the decoded text with negligible extra computation. In experiments on real world long-form audio (YouTube) with lengths of up to 30 minutes, we demonstrate 8.5% relative WER improvement and 250 ms reduction in median end-of-segment latency compared to the VAD segmenter baseline on a state-of-the-art Conformer RNN-T model.
Unsupervised Data Selection via Discrete Speech Representation for ASR
Apr 05, 2022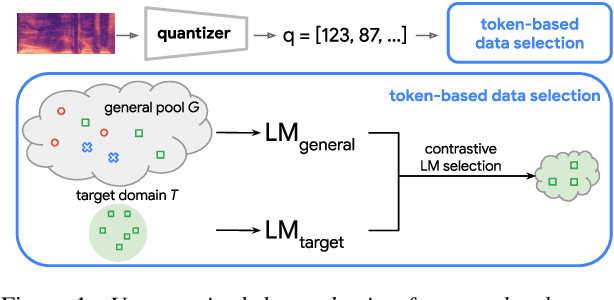


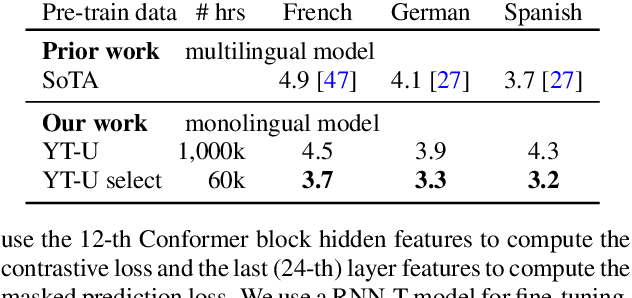
Self-supervised learning of speech representations has achieved impressive results in improving automatic speech recognition (ASR). In this paper, we show that data selection is important for self-supervised learning. We propose a simple and effective unsupervised data selection method which selects acoustically similar speech to a target domain. It takes the discrete speech representation available in common self-supervised learning frameworks as input, and applies a contrastive data selection method on the discrete tokens. Through extensive empirical studies we show that our proposed method reduces the amount of required pre-training data and improves the downstream ASR performance. Pre-training on a selected subset of 6% of the general data pool results in 11.8% relative improvements in LibriSpeech test-other compared to pre-training on the full set. On Multilingual LibriSpeech French, German, and Spanish test sets, selecting 6% data for pre-training reduces word error rate by more than 15% relatively compared to the full set, and achieves competitive results compared to current state-of-the-art performances.
Improving the fusion of acoustic and text representations in RNN-T
Jan 25, 2022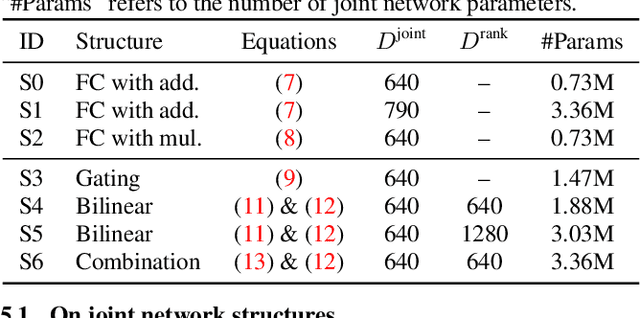
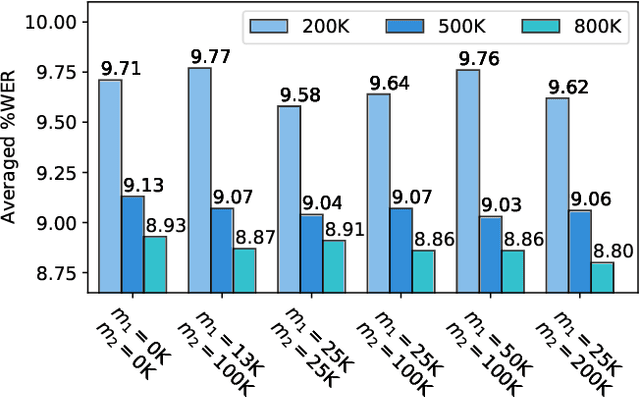
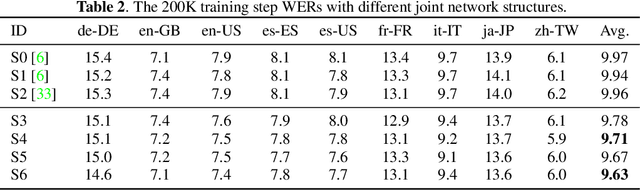
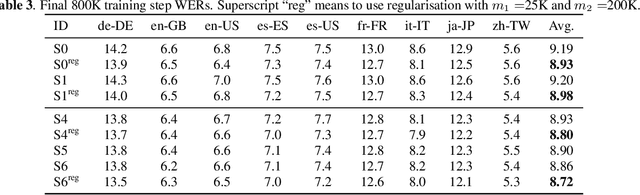
The recurrent neural network transducer (RNN-T) has recently become the mainstream end-to-end approach for streaming automatic speech recognition (ASR). To estimate the output distributions over subword units, RNN-T uses a fully connected layer as the joint network to fuse the acoustic representations extracted using the acoustic encoder with the text representations obtained using the prediction network based on the previous subword units. In this paper, we propose to use gating, bilinear pooling, and a combination of them in the joint network to produce more expressive representations to feed into the output layer. A regularisation method is also proposed to enable better acoustic encoder training by reducing the gradients back-propagated into the prediction network at the beginning of RNN-T training. Experimental results on a multilingual ASR setting for voice search over nine languages show that the joint use of the proposed methods can result in 4%--5% relative word error rate reductions with only a few million extra parameters.
Input Length Matters: An Empirical Study Of RNN-T And MWER Training For Long-form Telephony Speech Recognition
Oct 08, 2021
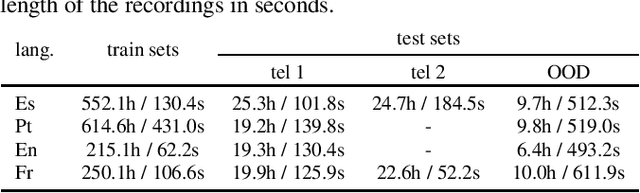


End-to-end models have achieved state-of-the-art results on several automatic speech recognition tasks. However, they perform poorly when evaluated on long-form data, e.g., minutes long conversational telephony audio. One reason the model fails on long-form speech is that it has only seen short utterances during training. This paper presents an empirical study on the effect of training utterance length on the word error rate (WER) for RNN-transducer (RNN-T) model. We compare two widely used training objectives, log loss (or RNN-T loss) and minimum word error rate (MWER) loss. We conduct experiments on telephony datasets in four languages. Our experiments show that for both losses, the WER on long-form speech reduces substantially as the training utterance length increases. The average relative WER gain is 15.7% for log loss and 8.8% for MWER loss. When training on short utterances, MWER loss leads to a lower WER than the log loss. Such difference between the two losses diminishes when the input length increases.