 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Manipulation in Distributed Stochastic Gradient Descent with Strategic Agents: Truthful Incentives with Convergence Guarantees
Mar 30, 2026Distributed learning has gained significant attention due to its advantages in scalability, privacy, and fault tolerance.In this paradigm, multiple agents collaboratively train a global model by exchanging parameters only with their neighbors. However, a key vulnerability of existing distributed learning approaches is their implicit assumption that all agents behave honestly during gradient updates. In real-world scenarios, this assumption often breaks down, as selfish or strategic agents may be incentivized to manipulate gradients for personal gain, ultimately compromising the final learning outcome. In this work, we propose a fully distributed payment mechanism that, for the first time, guarantees both truthful behaviors and accurate convergence in distributed stochastic gradient descent. This represents a significant advancement, as it overcomes two major limitations of existing truthfulness mechanisms for collaborative learning:(1) reliance on a centralized server for payment collection, and (2) sacrificing convergence accuracy to guarantee truthfulness. In addition to characterizing the convergence rate under general convex and strongly convex conditions, we also prove that our approach guarantees the cumulative gain that an agent can obtain through strategic behavior remains finite, even as the number of iterations approaches infinity--a property unattainable by most existing truthfulness mechanisms. Our experimental results on standard machine learning tasks, evaluated on benchmark datasets, confirm the effectiveness of the proposed approach.
Provably Convergent Decentralized Optimization over Directed Graphs under Generalized Smoothness
Jan 07, 2026Decentralized optimization has become a fundamental tool for large-scale learning systems; however, most existing methods rely on the classical Lipschitz smoothness assumption, which is often violated in problems with rapidly varying gradients. Motivated by this limitation, we study decentralized optimization under the generalized $(L_0, L_1)$-smoothness framework, in which the Hessian norm is allowed to grow linearly with the gradient norm, thereby accommodating rapidly varying gradients beyond classical Lipschitz smoothness. We integrate gradient-tracking techniques with gradient clipping and carefully design the clipping threshold to ensure accurate convergence over directed communication graphs under generalized smoothness. In contrast to existing distributed optimization results under generalized smoothness that require a bounded gradient dissimilarity assumption, our results remain valid even when the gradient dissimilarity is unbounded, making the proposed framework more applicable to realistic heterogeneous data environments. We validate our approach via numerical experiments on standard benchmark datasets, including LIBSVM and CIFAR-10, using regularized logistic regression and convolutional neural networks, demonstrating superior stability and faster convergence over existing methods.
Provable Acceleration of Distributed Optimization with Local Updates
Jan 06, 2026In conventional distributed optimization, each agent performs a single local update between two communication rounds with its neighbors to synchronize solutions. Inspired by the success of using multiple local updates in federated learning, incorporating local updates into distributed optimization has recently attracted increasing attention. However, unlike federated learning, where multiple local updates can accelerate learning by improving gradient estimation under mini-batch settings, it remains unclear whether similar benefits hold in distributed optimization when gradients are exact. Moreover, existing theoretical results typically require reducing the step size when multiple local updates are employed, which can entirely offset any potential benefit of these additional local updates and obscure their true impact on convergence. In this paper, we focus on the classic DIGing algorithm and leverage the tight performance bounds provided by Performance Estimation Problems (PEP) to show that incorporating local updates can indeed accelerate distributed optimization. To the best of our knowledge, this is the first rigorous demonstration of such acceleration for a broad class of objective functions. Our analysis further reveals that, under an appropriate step size, performing only two local updates is sufficient to achieve the maximal possible improvement, and that additional local updates provide no further gains. Because more updates increase computational cost, these findings offer practical guidance for efficient implementation. Extensive experiments on both synthetic and real-world datasets corroborate the theoretical findings.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Experimental Study of Decentralized Robot Network Coordination
Jul 05, 2024Synchronization and desynchronization in networks is a highly studied topic in many electrical systems, but there is a distinct lack of research on this topic with respect to robotics. Creating an effective decentralized synchronization algorithm for a robotic network would allow multiple robots to work together to achieve a task and would be able to adapt to the addition or loss of robots in real-time. The purpose of this study is to improve algorithms implemented developed by the authors for this purpose and experimentally evaluate these methods. The most effective algorithm for synchronization and desynchronization found in a former study were modified to improve testing and vary its methods of calculation. A multi-robot platform composed of multiple Roomba robots was used in the experimental study. Observation of data showed how adjusting parameters of the algorithms affected both the time to reach a desired state of synchronization or desynchronization and how the network maintained this state. Testing three different methods on each algorithm showed differing results. Future work in cooperative robotics will likely see success using these algorithms to accomplish a variety of tasks.
S2LIC: Learned Image Compression with the SwinV2 Block, Adaptive Channel-wise and Global-inter Attention Context
Mar 21, 2024
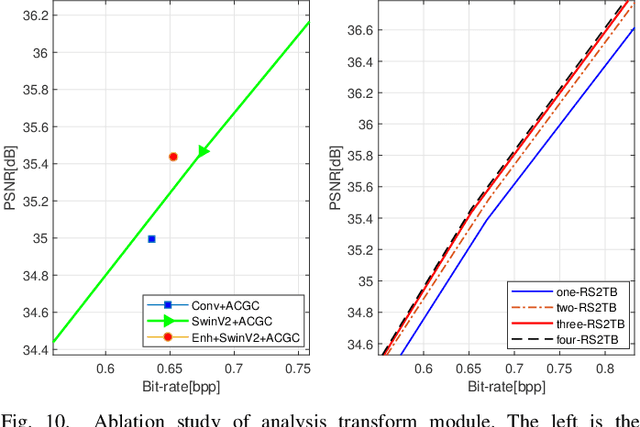


Recently, deep learning technology has been successfully applied in the field of image compression, leading to superior rate-distortion performance. It is crucial to design an effective and efficient entropy model to estimate the probability distribution of the latent representation. However, the majority of entropy models primarily focus on one-dimensional correlation processing between channel and spatial information. In this paper, we propose an Adaptive Channel-wise and Global-inter attention Context (ACGC) entropy model, which can efficiently achieve dual feature aggregation in both inter-slice and intraslice contexts. Specifically, we divide the latent representation into different slices and then apply the ACGC model in a parallel checkerboard context to achieve faster decoding speed and higher rate-distortion performance. In order to capture redundant global features across different slices, we utilize deformable attention in adaptive global-inter attention to dynamically refine the attention weights based on the actual spatial relationships and context. Furthermore, in the main transformation structure, we propose a high-performance S2LIC model. We introduce the residual SwinV2 Transformer model to capture global feature information and utilize a dense block network as the feature enhancement module to improve the nonlinear representation of the image within the transformation structure. Experimental results demonstrate that our method achieves faster encoding and decoding speeds and outperforms VTM-17.1 and some recent learned image compression methods in both PSNR and MS-SSIM metrics.
Quantization Avoids Saddle Points in Distributed Optimization
Mar 15, 2024Distributed nonconvex optimization underpins key functionalities of numerous distributed systems, ranging from power systems, smart buildings, cooperative robots, vehicle networks to sensor networks. Recently, it has also merged as a promising solution to handle the enormous growth in data and model sizes in deep learning. A fundamental problem in distributed nonconvex optimization is avoiding convergence to saddle points, which significantly degrade optimization accuracy. We discover that the process of quantization, which is necessary for all digital communications, can be exploited to enable saddle-point avoidance. More specifically, we propose a stochastic quantization scheme and prove that it can effectively escape saddle points and ensure convergence to a second-order stationary point in distributed nonconvex optimization. With an easily adjustable quantization granularity, the approach allows a user to control the number of bits sent per iteration and, hence, to aggressively reduce the communication overhead. Numerical experimental results using distributed optimization and learning problems on benchmark datasets confirm the effectiveness of the approach.
Privacy-Preserving Distributed Optimization and Learning
Feb 29, 2024Distributed optimization and learning has recently garnered great attention due to its wide applications in sensor networks, smart grids, machine learning, and so forth. Despite rapid development, existing distributed optimization and learning algorithms require each agent to exchange messages with its neighbors, which may expose sensitive information and raise significant privacy concerns. In this survey paper, we overview privacy-preserving distributed optimization and learning methods. We first discuss cryptography, differential privacy, and other techniques that can be used for privacy preservation and indicate their pros and cons for privacy protection in distributed optimization and learning. We believe that among these approaches, differential privacy is most promising due to its low computational and communication complexities, which are extremely appealing for modern learning based applications with high dimensions of optimization variables. We then introduce several differential-privacy algorithms that can simultaneously ensure privacy and optimization accuracy. Moreover, we provide example applications in several machine learning problems to confirm the real-world effectiveness of these algorithms. Finally, we highlight some challenges in this research domain and discuss future directions.
Multilingual and Fully Non-Autoregressive ASR with Large Language Model Fusion: A Comprehensive Study
Jan 23, 2024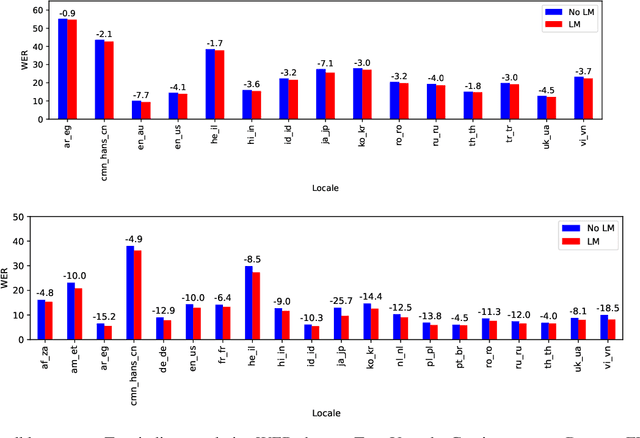
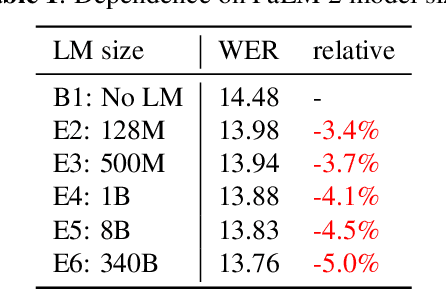
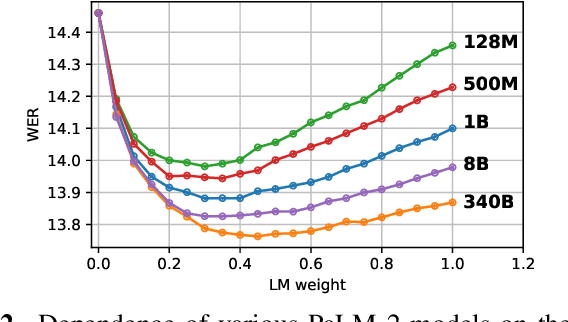
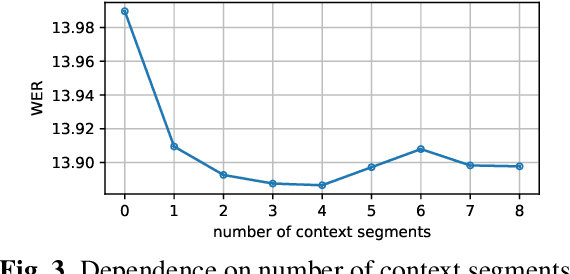
In the era of large models, the autoregressive nature of decoding often results in latency serving as a significant bottleneck. We propose a non-autoregressive LM-fused ASR system that effectively leverages the parallelization capabilities of accelerator hardware. Our approach combines the Universal Speech Model (USM) and the PaLM 2 language model in per-segment scoring mode, achieving an average relative WER improvement across all languages of 10.8% on FLEURS and 3.6% on YouTube captioning. Furthermore, our comprehensive ablation study analyzes key parameters such as LLM size, context length, vocabulary size, fusion methodology. For instance, we explore the impact of LLM size ranging from 128M to 340B parameters on ASR performance. This study provides valuable insights into the factors influencing the effectiveness of practical large-scale LM-fused speech recognition systems.
Locally Differentially Private Gradient Tracking for Distributed Online Learning over Directed Graphs
Oct 29, 2023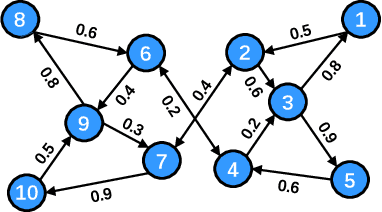
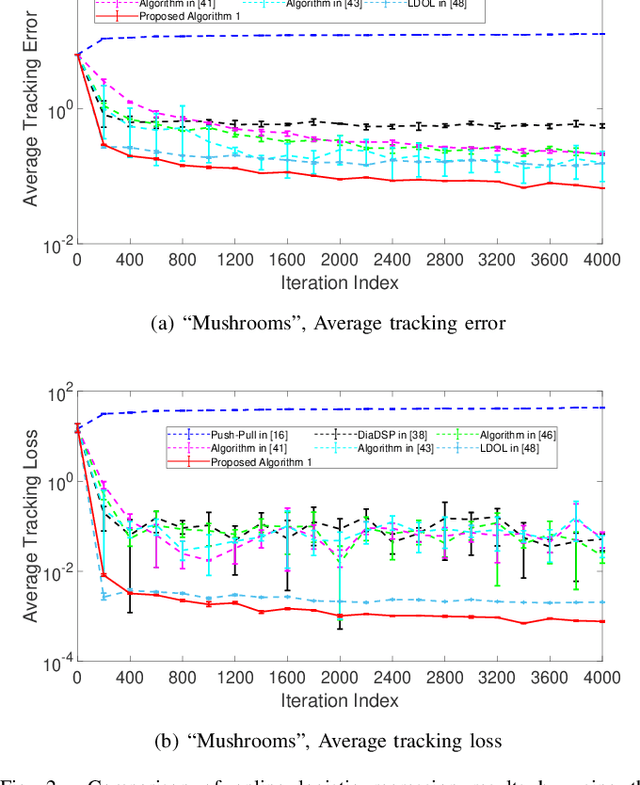
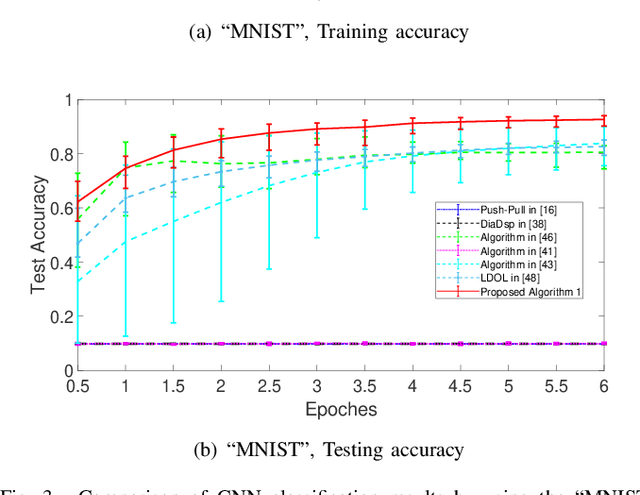
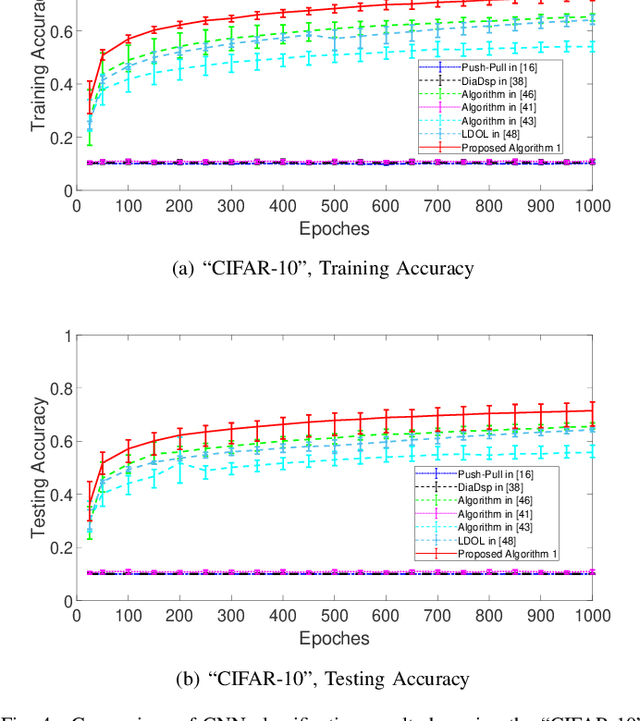
Distributed online learning has been proven extremely effective in solving large-scale machine learning problems over streaming data. However, information sharing between learners in distributed learning also raises concerns about the potential leakage of individual learners' sensitive data. To mitigate this risk, differential privacy, which is widely regarded as the "gold standard" for privacy protection, has been widely employed in many existing results on distributed online learning. However, these results often face a fundamental tradeoff between learning accuracy and privacy. In this paper, we propose a locally differentially private gradient tracking based distributed online learning algorithm that successfully circumvents this tradeoff. We prove that the proposed algorithm converges in mean square to the exact optimal solution while ensuring rigorous local differential privacy, with the cumulative privacy budget guaranteed to be finite even when the number of iterations tends to infinity. The algorithm is applicable even when the communication graph among learners is directed. To the best of our knowledge, this is the first result that simultaneously ensures learning accuracy and rigorous local differential privacy in distributed online learning over directed graphs. We evaluate our algorithm's performance by using multiple benchmark machine-learning applications, including logistic regression of the "Mushrooms" dataset and CNN-based image classification of the "MNIST" and "CIFAR-10" datasets, respectively. The experimental results confirm that the proposed algorithm outperforms existing counterparts in both training and testing accuracies.