 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual and Fully Non-Autoregressive ASR with Large Language Model Fusion: A Comprehensive Study
Jan 23, 2024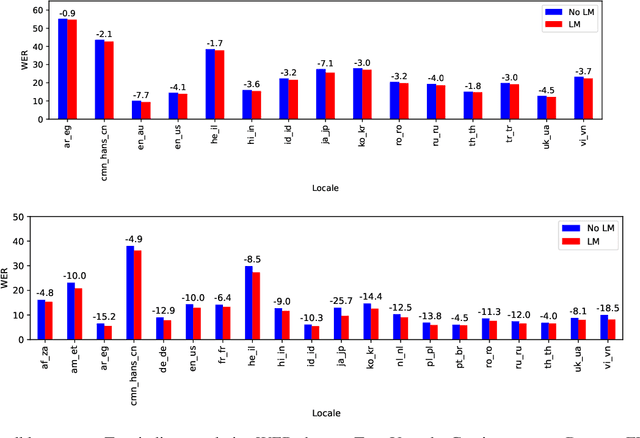
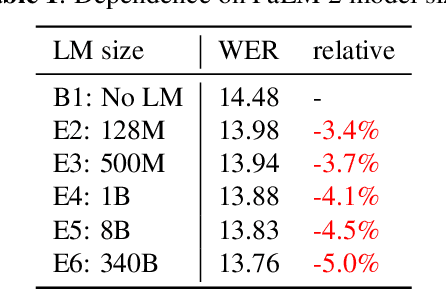
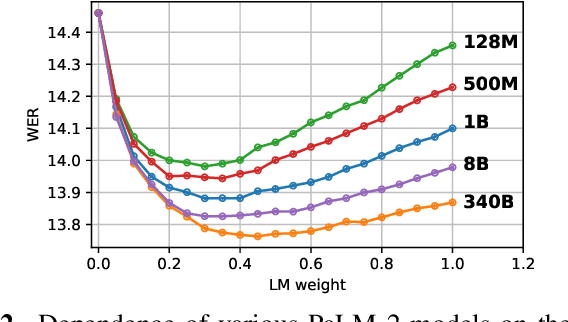
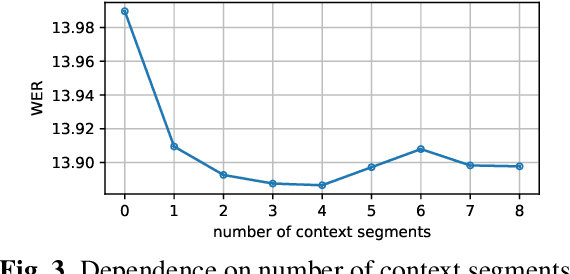
In the era of large models, the autoregressive nature of decoding often results in latency serving as a significant bottleneck. We propose a non-autoregressive LM-fused ASR system that effectively leverages the parallelization capabilities of accelerator hardware. Our approach combines the Universal Speech Model (USM) and the PaLM 2 language model in per-segment scoring mode, achieving an average relative WER improvement across all languages of 10.8% on FLEURS and 3.6% on YouTube captioning. Furthermore, our comprehensive ablation study analyzes key parameters such as LLM size, context length, vocabulary size, fusion methodology. For instance, we explore the impact of LLM size ranging from 128M to 340B parameters on ASR performance. This study provides valuable insights into the factors influencing the effectiveness of practical large-scale LM-fused speech recognition systems.
UserLibri: A Dataset for ASR Personalization Using Only Text
Jul 02, 2022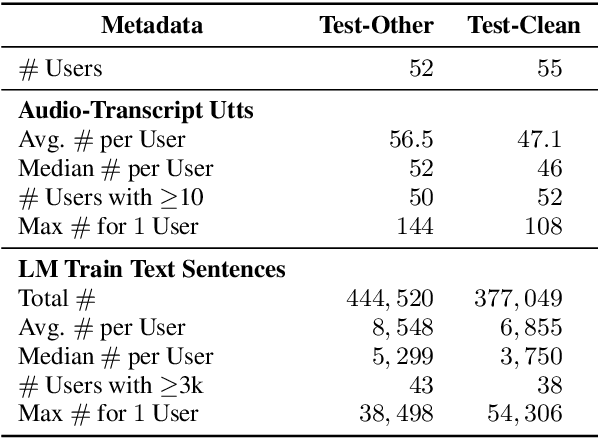
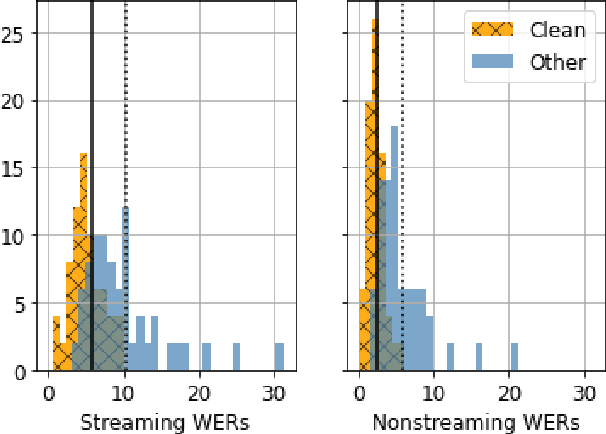
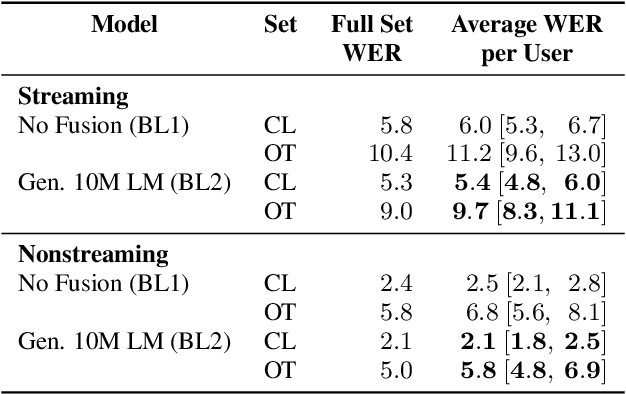
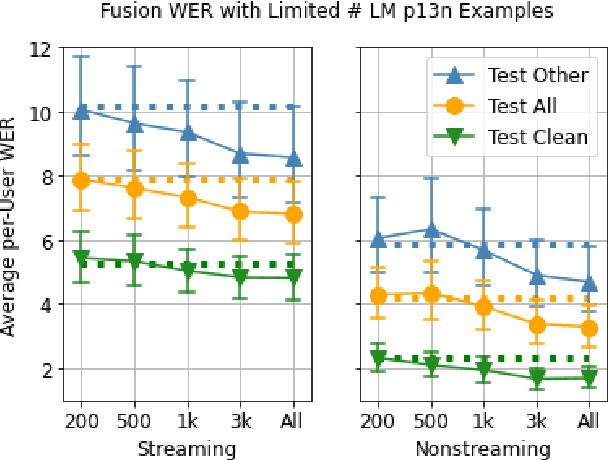
Personalization of speech models on mobile devices (on-device personalization) is an active area of research, but more often than not, mobile devices have more text-only data than paired audio-text data. We explore training a personalized language model on text-only data, used during inference to improve speech recognition performance for that user. We experiment on a user-clustered LibriSpeech corpus, supplemented with personalized text-only data for each user from Project Gutenberg. We release this User-Specific LibriSpeech (UserLibri) dataset to aid future personalization research. LibriSpeech audio-transcript pairs are grouped into 55 users from the test-clean dataset and 52 users from test-other. We are able to lower the average word error rate per user across both sets in streaming and nonstreaming models, including an improvement of 2.5 for the harder set of test-other users when streaming.
Prosody Transfer in Neural Text to Speech Using Global Pitch and Loudness Features
Nov 21, 2019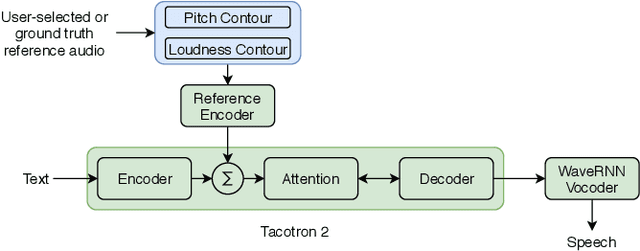
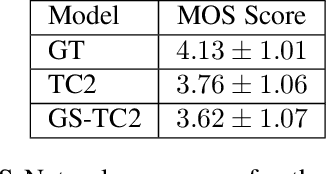

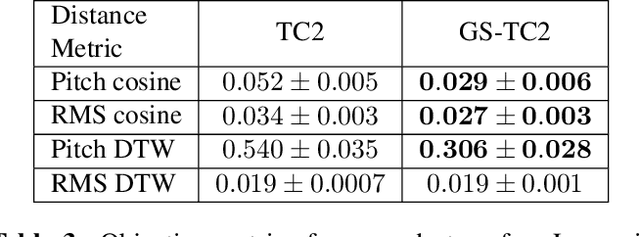
This paper presents a simple yet effective method to achieve prosody transfer from a reference speech signal to synthesized speech. The main idea is to incorporate well-known acoustic correlates of prosody such as pitch and loudness contours of the reference speech into a modern neural text-to-speech (TTS) synthesizer such as Tacotron2 (TC2). More specifically, a small set of acoustic features are extracted from the reference audio and then used to condition a TC2 synthesizer. The trained model is evaluated using subjective listening tests and novel objective evaluations of prosody transfer are proposed. Listening tests show that the synthesized speech is rated as highly natural and that prosody is successfully transferred from the reference speech signal to the synthesized signal.
Context-Aware Attention for Understanding Twitter Abuse
Sep 24, 2018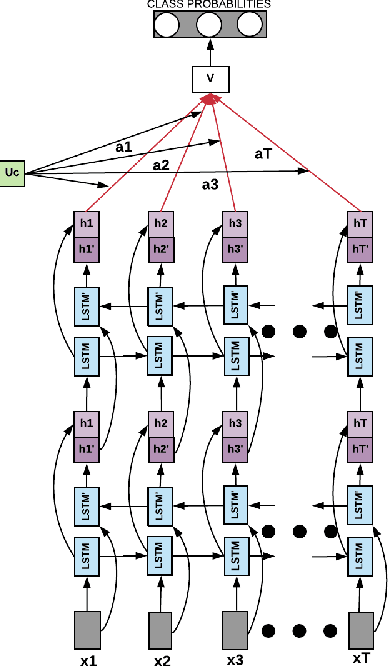
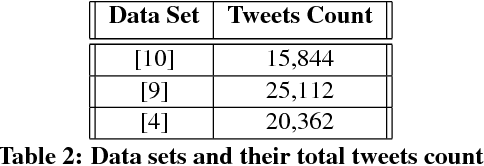
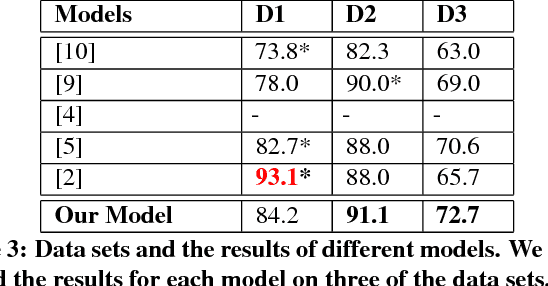

The original goal of any social media platform is to facilitate users to indulge in healthy and meaningful conversations. But more often than not, it has been found that it becomes an avenue for wanton attacks. We want to alleviate this issue and hence we try to provide a detailed analysis of how abusive behavior can be monitored in Twitter. The complexity of the natural language constructs makes this task challenging. We show how applying contextual attention to Long Short Term Memory networks help us give near state of art results on multiple benchmarks abuse detection data sets from Twitter.
A Hybrid Variational Autoencoder for Collaborative Filtering
Sep 23, 2018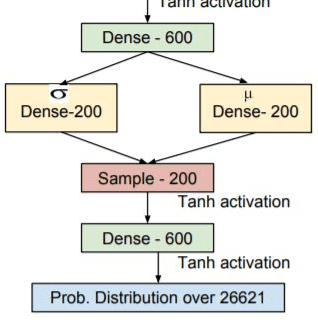
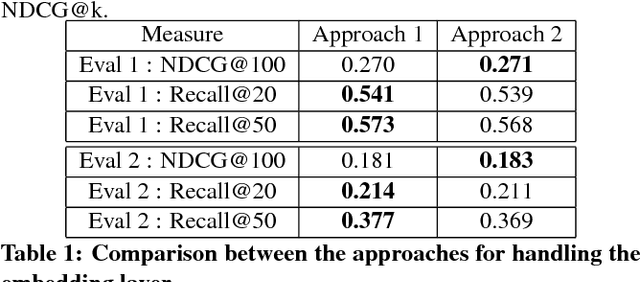
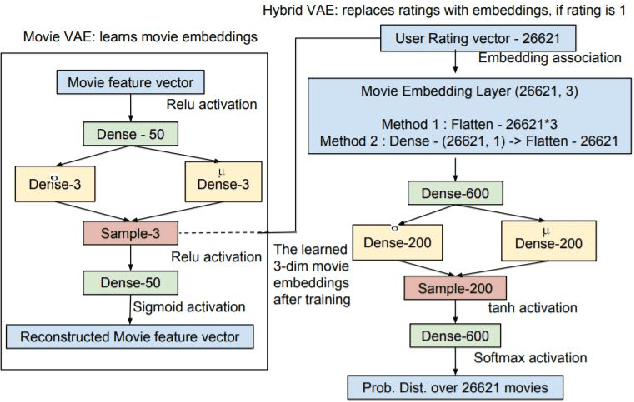
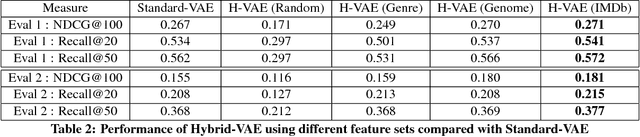
In today's day and age when almost every industry has an online presence with users interacting in online marketplaces, personalized recommendations have become quite important. Traditionally, the problem of collaborative filtering has been tackled using Matrix Factorization which is linear in nature. We extend the work of [11] on using variational autoencoders (VAEs) for collaborative filtering with implicit feedback by proposing a hybrid, multi-modal approach. Our approach combines movie embeddings (learned from a sibling VAE network) with user ratings from the Movielens 20M dataset and applies it to the task of movie recommendation. We empirically show how the VAE network is empowered by incorporating movie embeddings. We also visualize movie and user embeddings by clustering their latent representations obtained from a VAE.