 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual and Fully Non-Autoregressive ASR with Large Language Model Fusion: A Comprehensive Study
Jan 23, 2024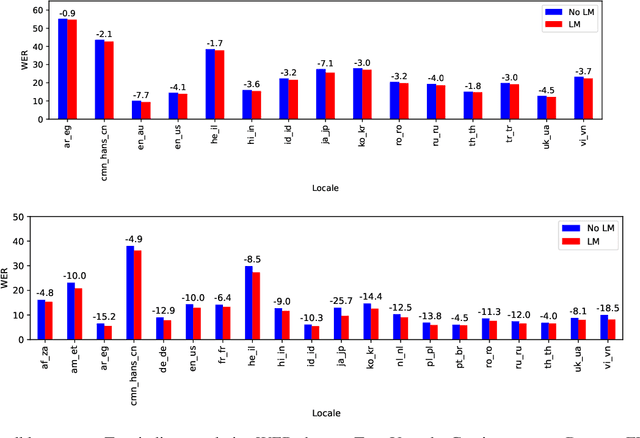
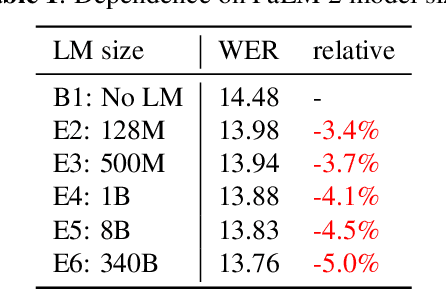
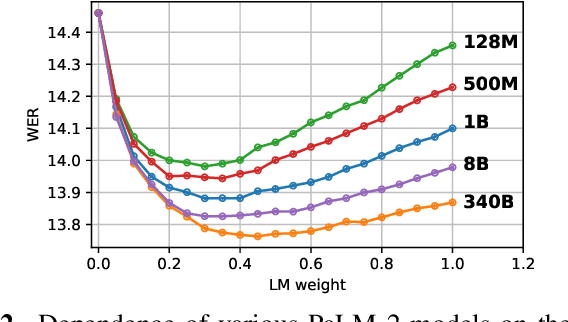
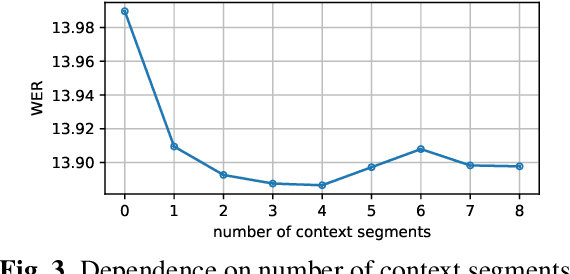
In the era of large models, the autoregressive nature of decoding often results in latency serving as a significant bottleneck. We propose a non-autoregressive LM-fused ASR system that effectively leverages the parallelization capabilities of accelerator hardware. Our approach combines the Universal Speech Model (USM) and the PaLM 2 language model in per-segment scoring mode, achieving an average relative WER improvement across all languages of 10.8% on FLEURS and 3.6% on YouTube captioning. Furthermore, our comprehensive ablation study analyzes key parameters such as LLM size, context length, vocabulary size, fusion methodology. For instance, we explore the impact of LLM size ranging from 128M to 340B parameters on ASR performance. This study provides valuable insights into the factors influencing the effectiveness of practical large-scale LM-fused speech recognition systems.
E2E Segmentation in a Two-Pass Cascaded Encoder ASR Model
Nov 28, 2022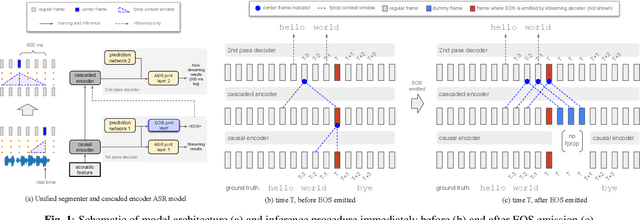
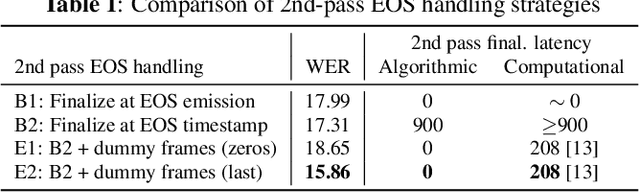
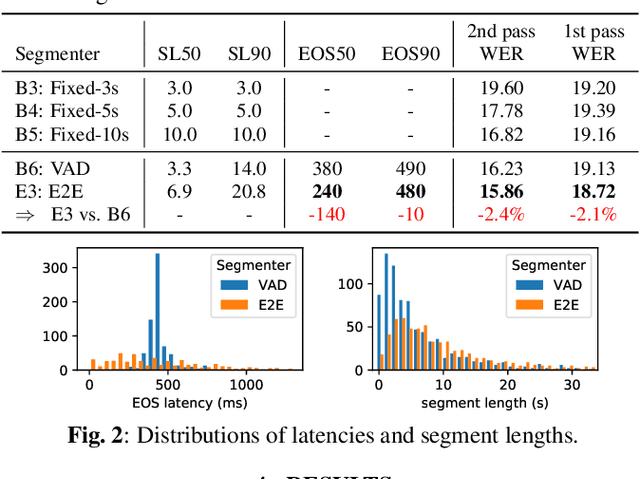

We explore unifying a neural segmenter with two-pass cascaded encoder ASR into a single model. A key challenge is allowing the segmenter (which runs in real-time, synchronously with the decoder) to finalize the 2nd pass (which runs 900 ms behind real-time) without introducing user-perceived latency or deletion errors during inference. We propose a design where the neural segmenter is integrated with the causal 1st pass decoder to emit a end-of-segment (EOS) signal in real-time. The EOS signal is then used to finalize the non-causal 2nd pass. We experiment with different ways to finalize the 2nd pass, and find that a novel dummy frame injection strategy allows for simultaneous high quality 2nd pass results and low finalization latency. On a real-world long-form captioning task (YouTube), we achieve 2.4% relative WER and 140 ms EOS latency gains over a baseline VAD-based segmenter with the same cascaded encoder.
On Neural Phone Recognition of Mixed-Source ECoG Signals
Dec 12, 2019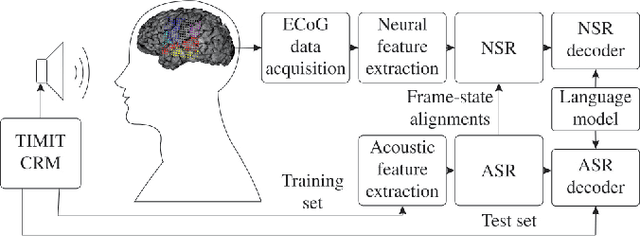

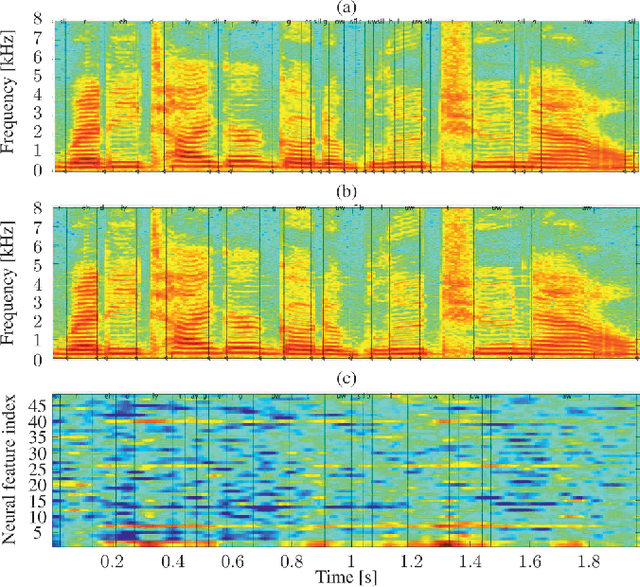
The emerging field of neural speech recognition (NSR) using electrocorticography has recently attracted remarkable research interest for studying how human brains recognize speech in quiet and noisy surroundings. In this study, we demonstrate the utility of NSR systems to objectively prove the ability of human beings to attend to a single speech source while suppressing the interfering signals in a simulated cocktail party scenario. The experimental results show that the relative degradation of the NSR system performance when tested in a mixed-source scenario is significantly lower than that of automatic speech recognition (ASR). In this paper, we have significantly enhanced the performance of our recently published framework by using manual alignments for initialization instead of the flat start technique. We have also improved the NSR system performance by accounting for the possible transcription mismatch between the acoustic and neural signals.