 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Neural Phone Recognition of Mixed-Source ECoG Signals
Dec 12, 2019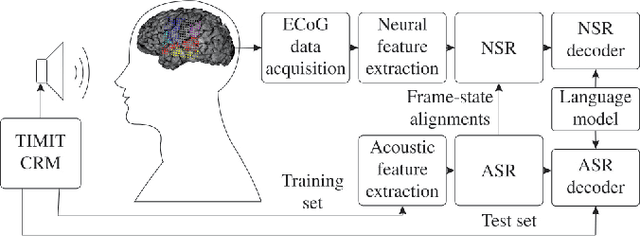

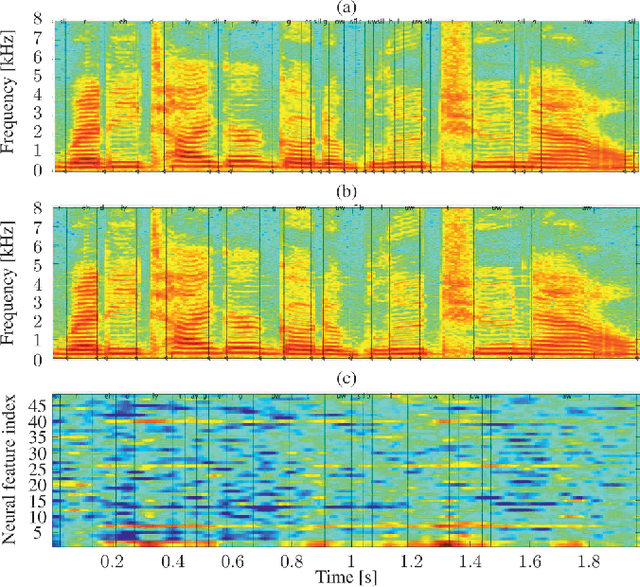
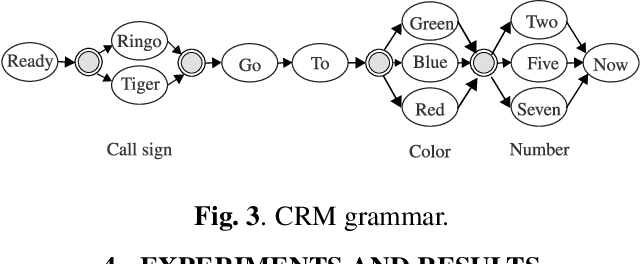
The emerging field of neural speech recognition (NSR) using electrocorticography has recently attracted remarkable research interest for studying how human brains recognize speech in quiet and noisy surroundings. In this study, we demonstrate the utility of NSR systems to objectively prove the ability of human beings to attend to a single speech source while suppressing the interfering signals in a simulated cocktail party scenario. The experimental results show that the relative degradation of the NSR system performance when tested in a mixed-source scenario is significantly lower than that of automatic speech recognition (ASR). In this paper, we have significantly enhanced the performance of our recently published framework by using manual alignments for initialization instead of the flat start technique. We have also improved the NSR system performance by accounting for the possible transcription mismatch between the acoustic and neural signals.