 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural2Speech: A Transfer Learning Framework for Neural-Driven Speech Reconstruction
Oct 07, 2023Reconstructing natural speech from neural activity is vital for enabling direct communication via brain-computer interfaces. Previous efforts have explored the conversion of neural recordings into speech using complex deep neural network (DNN) models trained on extensive neural recording data, which is resource-intensive under regular clinical constraints. However, achieving satisfactory performance in reconstructing speech from limited-scale neural recordings has been challenging, mainly due to the complexity of speech representations and the neural data constraints. To overcome these challenges, we propose a novel transfer learning framework for neural-driven speech reconstruction, called Neural2Speech, which consists of two distinct training phases. First, a speech autoencoder is pre-trained on readily available speech corpora to decode speech waveforms from the encoded speech representations. Second, a lightweight adaptor is trained on the small-scale neural recordings to align the neural activity and the speech representation for decoding. Remarkably, our proposed Neural2Speech demonstrates the feasibility of neural-driven speech reconstruction even with only 20 minutes of intracranial data, which significantly outperforms existing baseline methods in terms of speech fidelity and intelligibility.
Do self-supervised speech and language models extract similar representations as human brain?
Oct 07, 2023



Speech and language models trained through self-supervised learning (SSL) demonstrate strong alignment with brain activity during speech and language perception. However, given their distinct training modalities, it remains unclear whether they correlate with the same neural aspects. We directly address this question by evaluating the brain prediction performance of two representative SSL models, Wav2Vec2.0 and GPT-2, designed for speech and language tasks. Our findings reveal that both models accurately predict speech responses in the auditory cortex, with a significant correlation between their brain predictions. Notably, shared speech contextual information between Wav2Vec2.0 and GPT-2 accounts for the majority of explained variance in brain activity, surpassing static semantic and lower-level acoustic-phonetic information. These results underscore the convergence of speech contextual representations in SSL models and their alignment with the neural network underlying speech perception, offering valuable insights into both SSL models and the neural basis of speech and language processing.
Neural Latent Aligner: Cross-trial Alignment for Learning Representations of Complex, Naturalistic Neural Data
Aug 12, 2023



Understanding the neural implementation of complex human behaviors is one of the major goals in neuroscience. To this end, it is crucial to find a true representation of the neural data, which is challenging due to the high complexity of behaviors and the low signal-to-ratio (SNR) of the signals. Here, we propose a novel unsupervised learning framework, Neural Latent Aligner (NLA), to find well-constrained, behaviorally relevant neural representations of complex behaviors. The key idea is to align representations across repeated trials to learn cross-trial consistent information. Furthermore, we propose a novel, fully differentiable time warping model (TWM) to resolve the temporal misalignment of trials. When applied to intracranial electrocorticography (ECoG) of natural speaking, our model learns better representations for decoding behaviors than the baseline models, especially in lower dimensional space. The TWM is empirically validated by measuring behavioral coherence between aligned trials. The proposed framework learns more cross-trial consistent representations than the baselines, and when visualized, the manifold reveals shared neural trajectories across trials.
* Accepted at ICML 2023
On Neural Phone Recognition of Mixed-Source ECoG Signals
Dec 12, 2019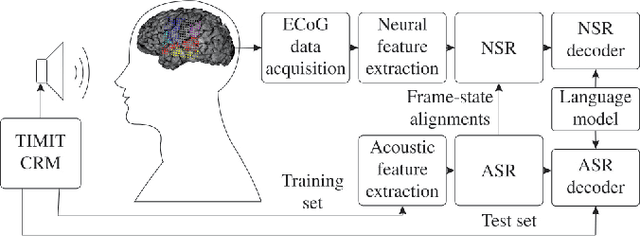

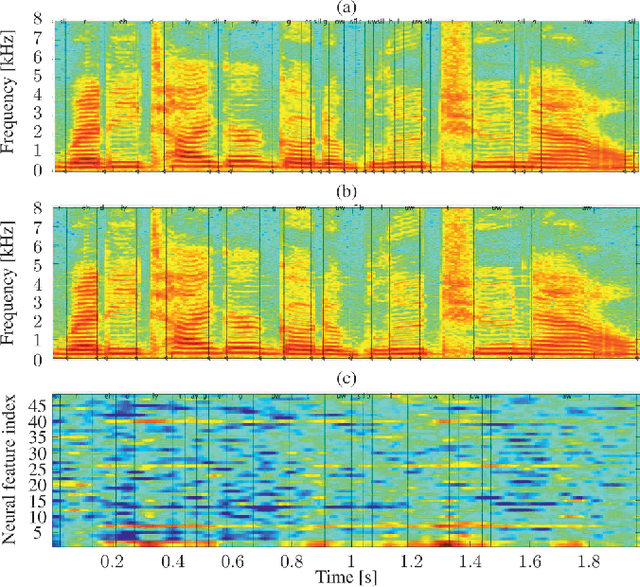
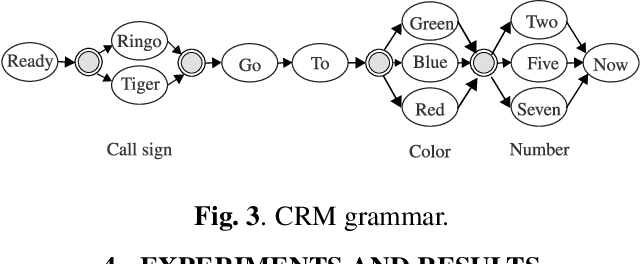
The emerging field of neural speech recognition (NSR) using electrocorticography has recently attracted remarkable research interest for studying how human brains recognize speech in quiet and noisy surroundings. In this study, we demonstrate the utility of NSR systems to objectively prove the ability of human beings to attend to a single speech source while suppressing the interfering signals in a simulated cocktail party scenario. The experimental results show that the relative degradation of the NSR system performance when tested in a mixed-source scenario is significantly lower than that of automatic speech recognition (ASR). In this paper, we have significantly enhanced the performance of our recently published framework by using manual alignments for initialization instead of the flat start technique. We have also improved the NSR system performance by accounting for the possible transcription mismatch between the acoustic and neural signals.
Brain2Char: A Deep Architecture for Decoding Text from Brain Recordings
Sep 03, 2019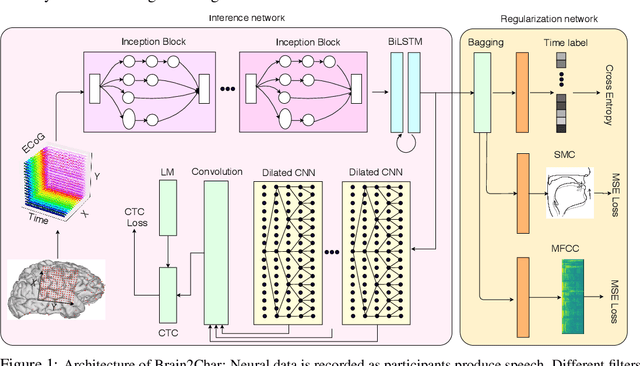

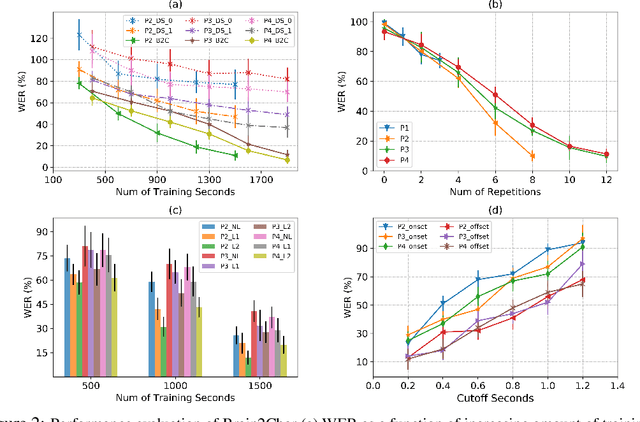

Decoding language representations directly from the brain can enable new Brain-Computer Interfaces (BCI) for high bandwidth human-human and human-machine communication. Clinically, such technologies can restore communication in people with neurological conditions affecting their ability to speak. In this study, we propose a novel deep network architecture Brain2Char, for directly decoding text (specifically character sequences) from direct brain recordings (called Electrocorticography, ECoG). Brain2Char framework combines state-of-the-art deep learning modules --- 3D Inception layers for multiband spatiotemporal feature extraction from neural data and bidirectional recurrent layers, dilated convolution layers followed by language model weighted beam search to decode character sequences, optimizing a connectionist temporal classification (CTC) loss. Additionally, given the highly non-linear transformations that underlie the conversion of cortical function to character sequences, we perform regularizations on the network's latent representations motivated by insights into cortical encoding of speech production and artifactual aspects specific to ECoG data acquisition. To do this, we impose auxiliary losses on latent representations for articulatory movements, speech acoustics and session specific non-linearities. In 3 participants tested here, Brain2Char achieves 10.6\%, 8.5\% and 7.0\% Word Error Rates (WER) respectively on vocabulary sizes ranging from 1200 to 1900 words. Brain2Char also performs well when 2 participants silently mimed sentences. These results set a new state-of-the-art on decoding text from brain and demonstrate the potential of Brain2Char as a high-performance communication BCI.
Spiking Linear Dynamical Systems on Neuromorphic Hardware for Low-Power Brain-Machine Interfaces
Jun 05, 2018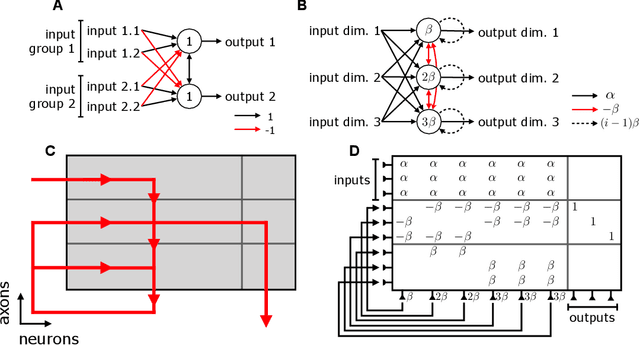
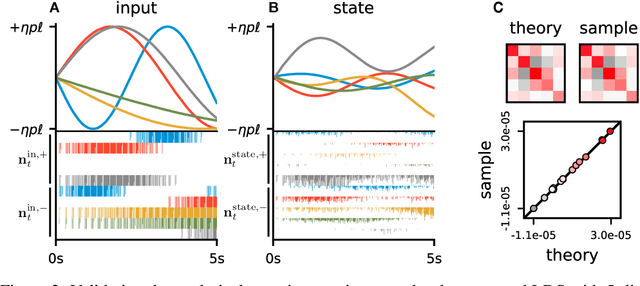
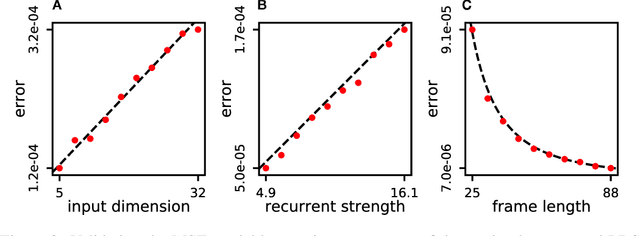
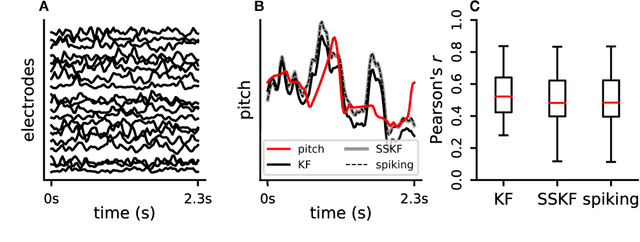
Neuromorphic architectures achieve low-power operation by using many simple spiking neurons in lieu of traditional hardware. Here, we develop methods for precise linear computations in spiking neural networks and use these methods to map the evolution of a linear dynamical system (LDS) onto an existing neuromorphic chip: IBM's TrueNorth. We analytically characterize, and numerically validate, the discrepancy between the spiking LDS state sequence and that of its non-spiking counterpart. These analytical results shed light on the multiway tradeoff between time, space, energy, and accuracy in neuromorphic computation. To demonstrate the utility of our work, we implemented a neuromorphic Kalman filter (KF) and used it for offline decoding of human vocal pitch from neural data. The neuromorphic KF could be used for low-power filtering in domains beyond neuroscience, such as navigation or robotics.
Deep learning as a tool for neural data analysis: speech classification and cross-frequency coupling in human sensorimotor cortex
Mar 26, 2018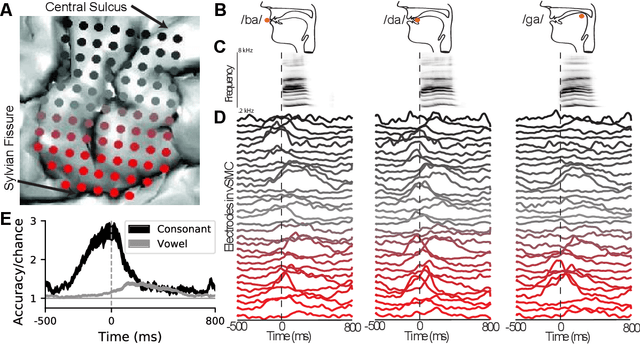
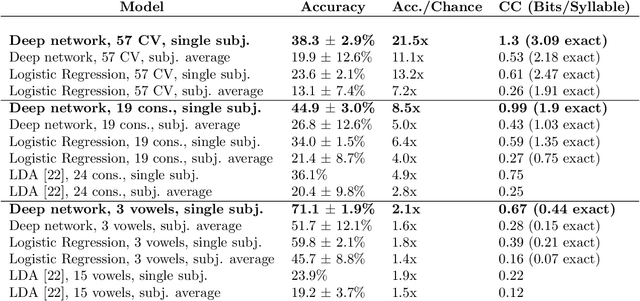
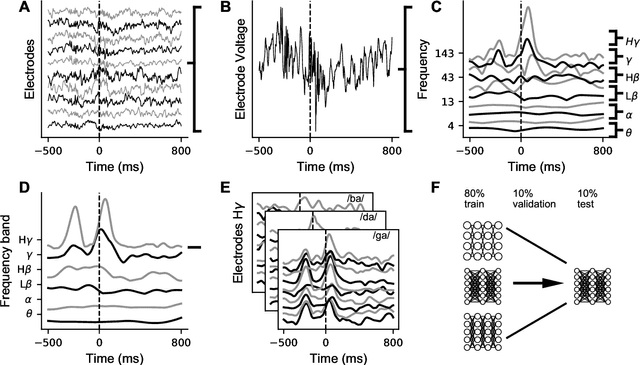
A fundamental challenge in neuroscience is to understand what structure in the world is represented in spatially distributed patterns of neural activity from multiple single-trial measurements. This is often accomplished by learning a simple, linear transformations between neural features and features of the sensory stimuli or motor task. While successful in some early sensory processing areas, linear mappings are unlikely to be ideal tools for elucidating nonlinear, hierarchical representations of higher-order brain areas during complex tasks, such as the production of speech by humans. Here, we apply deep networks to predict produced speech syllables from cortical surface electric potentials recorded from human sensorimotor cortex. We found that deep networks had higher decoding prediction accuracy compared to baseline models, and also exhibited greater improvements in accuracy with increasing dataset size. We further demonstrate that deep network's confusions revealed hierarchical latent structure in the neural data, which recapitulated the underlying articulatory nature of speech motor control. Finally, we used deep networks to compare task-relevant information in different neural frequency bands, and found that the high-gamma band contains the vast majority of information relevant for the speech prediction task, with little-to-no additional contribution from lower-frequencies. Together, these results demonstrate the utility of deep networks as a data analysis tool for neuroscience.
Union of Intersections (UoI) for Interpretable Data Driven Discovery and Prediction
Nov 02, 2017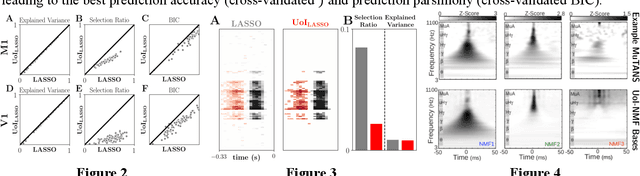
The increasing size and complexity of scientific data could dramatically enhance discovery and prediction for basic scientific applications. Realizing this potential, however, requires novel statistical analysis methods that are both interpretable and predictive. We introduce Union of Intersections (UoI), a flexible, modular, and scalable framework for enhanced model selection and estimation. Methods based on UoI perform model selection and model estimation through intersection and union operations, respectively. We show that UoI-based methods achieve low-variance and nearly unbiased estimation of a small number of interpretable features, while maintaining high-quality prediction accuracy. We perform extensive numerical investigation to evaluate a UoI algorithm ($UoI_{Lasso}$) on synthetic and real data. In doing so, we demonstrate the extraction of interpretable functional networks from human electrophysiology recordings as well as accurate prediction of phenotypes from genotype-phenotype data with reduced features. We also show (with the $UoI_{L1Logistic}$ and $UoI_{CUR}$ variants of the basic framework) improved prediction parsimony for classification and matrix factorization on several benchmark biomedical data sets. These results suggest that methods based on the UoI framework could improve interpretation and prediction in data-driven discovery across scientific fields.