 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Brain, Omni Modalities: Towards Unified Non-Invasive Brain Decoding with Large Language Models
Feb 25, 2026Deciphering brain function through non-invasive recordings requires synthesizing complementary high-frequency electromagnetic (EEG/MEG) and low-frequency metabolic (fMRI) signals. However, despite their shared neural origins, extreme discrepancies have traditionally confined these modalities to isolated analysis pipelines, hindering a holistic interpretation of brain activity. To bridge this fragmentation, we introduce \textbf{NOBEL}, a \textbf{n}euro-\textbf{o}mni-modal \textbf{b}rain-\textbf{e}ncoding \textbf{l}arge language model (LLM) that unifies these heterogeneous signals within the LLM's semantic embedding space. Our architecture integrates a unified encoder for EEG and MEG with a novel dual-path strategy for fMRI, aligning non-invasive brain signals and external sensory stimuli into a shared token space, then leverages an LLM as a universal backbone. Extensive evaluations demonstrate that NOBEL serves as a robust generalist across standard single-modal tasks. We also show that the synergistic fusion of electromagnetic and metabolic signals yields higher decoding accuracy than unimodal baselines, validating the complementary nature of multiple neural modalities. Furthermore, NOBEL exhibits strong capabilities in stimulus-aware decoding, effectively interpreting visual semantics from multi-subject fMRI data on the NSD and HAD datasets while uniquely leveraging direct stimulus inputs to verify causal links between sensory signals and neural responses. NOBEL thus takes a step towards unifying non-invasive brain decoding, demonstrating the promising potential of omni-modal brain understanding.
NeuroBind: Towards Unified Multimodal Representations for Neural Signals
Jul 19, 2024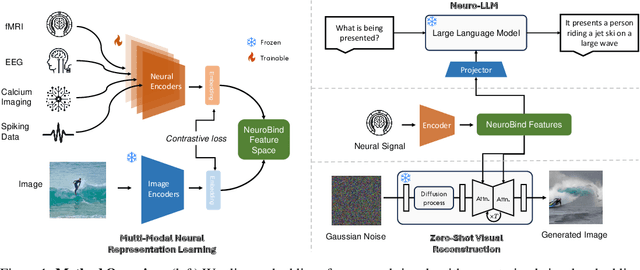
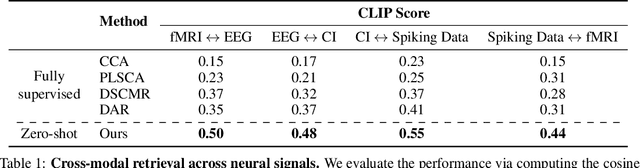

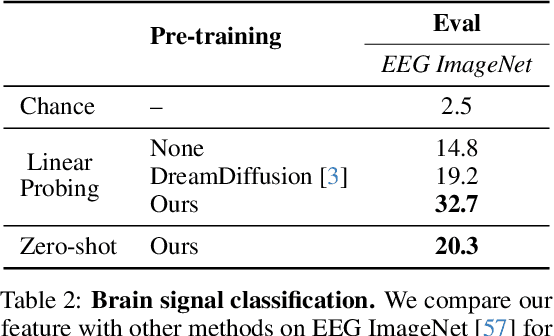
Understanding neural activity and information representation is crucial for advancing knowledge of brain function and cognition. Neural activity, measured through techniques like electrophysiology and neuroimaging, reflects various aspects of information processing. Recent advances in deep neural networks offer new approaches to analyzing these signals using pre-trained models. However, challenges arise due to discrepancies between different neural signal modalities and the limited scale of high-quality neural data. To address these challenges, we present NeuroBind, a general representation that unifies multiple brain signal types, including EEG, fMRI, calcium imaging, and spiking data. To achieve this, we align neural signals in these image-paired neural datasets to pre-trained vision-language embeddings. Neurobind is the first model that studies different neural modalities interconnectedly and is able to leverage high-resource modality models for various neuroscience tasks. We also showed that by combining information from different neural signal modalities, NeuroBind enhances downstream performance, demonstrating the effectiveness of the complementary strengths of different neural modalities. As a result, we can leverage multiple types of neural signals mapped to the same space to improve downstream tasks, and demonstrate the complementary strengths of different neural modalities. This approach holds significant potential for advancing neuroscience research, improving AI systems, and developing neuroprosthetics and brain-computer interfaces.
Decoding Probing: Revealing Internal Linguistic Structures in Neural Language Models using Minimal Pairs
Mar 26, 2024Inspired by cognitive neuroscience studies, we introduce a novel `decoding probing' method that uses minimal pairs benchmark (BLiMP) to probe internal linguistic characteristics in neural language models layer by layer. By treating the language model as the `brain' and its representations as `neural activations', we decode grammaticality labels of minimal pairs from the intermediate layers' representations. This approach reveals: 1) Self-supervised language models capture abstract linguistic structures in intermediate layers that GloVe and RNN language models cannot learn. 2) Information about syntactic grammaticality is robustly captured through the first third layers of GPT-2 and also distributed in later layers. As sentence complexity increases, more layers are required for learning grammatical capabilities. 3) Morphological and semantics/syntax interface-related features are harder to capture than syntax. 4) For Transformer-based models, both embeddings and attentions capture grammatical features but show distinct patterns. Different attention heads exhibit similar tendencies toward various linguistic phenomena, but with varied contributions.
Neural2Speech: A Transfer Learning Framework for Neural-Driven Speech Reconstruction
Oct 07, 2023Reconstructing natural speech from neural activity is vital for enabling direct communication via brain-computer interfaces. Previous efforts have explored the conversion of neural recordings into speech using complex deep neural network (DNN) models trained on extensive neural recording data, which is resource-intensive under regular clinical constraints. However, achieving satisfactory performance in reconstructing speech from limited-scale neural recordings has been challenging, mainly due to the complexity of speech representations and the neural data constraints. To overcome these challenges, we propose a novel transfer learning framework for neural-driven speech reconstruction, called Neural2Speech, which consists of two distinct training phases. First, a speech autoencoder is pre-trained on readily available speech corpora to decode speech waveforms from the encoded speech representations. Second, a lightweight adaptor is trained on the small-scale neural recordings to align the neural activity and the speech representation for decoding. Remarkably, our proposed Neural2Speech demonstrates the feasibility of neural-driven speech reconstruction even with only 20 minutes of intracranial data, which significantly outperforms existing baseline methods in terms of speech fidelity and intelligibility.
Do self-supervised speech and language models extract similar representations as human brain?
Oct 07, 2023



Speech and language models trained through self-supervised learning (SSL) demonstrate strong alignment with brain activity during speech and language perception. However, given their distinct training modalities, it remains unclear whether they correlate with the same neural aspects. We directly address this question by evaluating the brain prediction performance of two representative SSL models, Wav2Vec2.0 and GPT-2, designed for speech and language tasks. Our findings reveal that both models accurately predict speech responses in the auditory cortex, with a significant correlation between their brain predictions. Notably, shared speech contextual information between Wav2Vec2.0 and GPT-2 accounts for the majority of explained variance in brain activity, surpassing static semantic and lower-level acoustic-phonetic information. These results underscore the convergence of speech contextual representations in SSL models and their alignment with the neural network underlying speech perception, offering valuable insights into both SSL models and the neural basis of speech and language processing.