 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMEmb-R1: Reasoning-Enhanced Multimodal Embedding with Pair-Aware Selection and Adaptive Control
Apr 07, 2026MLLMs have been successfully applied to multimodal embedding tasks, yet their generative reasoning capabilities remain underutilized. Directly incorporating chain-of-thought reasoning into embedding learning introduces two fundamental challenges. First, structural misalignment between instance-level reasoning and pairwise contrastive supervision may lead to shortcut behavior, where the model merely learns the superficial format of reasoning. Second, reasoning is not universally beneficial for embedding tasks. Enforcing reasoning for all inputs may introduce unnecessary computation and latency, and can even obscure salient semantic signals for simple cases. To address these issues, we propose MMEmb-R1, an adaptive reasoning-based multimodal embedding framework. We formulate reasoning as a latent variable and introduce pair-aware reasoning selection that employs counterfactual intervention to identify reasoning paths beneficial for query-target alignment. Furthermore, we adopt reinforcement learning to selectively invoke reasoning only when necessary. Experiments on the MMEB-V2 benchmark demonstrate that our model achieves a score of 71.2 with only 4B parameters, establishing a new state-of-the-art while significantly reducing reasoning overhead and inference latency.
SOLAR: SVD-Optimized Lifelong Attention for Recommendation
Mar 03, 2026Attention mechanism remains the defining operator in Transformers since it provides expressive global credit assignment, yet its $O(N^2 d)$ time and memory cost in sequence length $N$ makes long-context modeling expensive and often forces truncation or other heuristics. Linear attention reduces complexity to $O(N d^2)$ by reordering computation through kernel feature maps, but this reformulation drops the softmax mechanism and shifts the attention score distribution. In recommender systems, low-rank structure in matrices is not a rare case, but rather the default inductive bias in its representation learning, particularly explicit in the user behavior sequence modeling. Leveraging this structure, we introduce SVD-Attention, which is theoretically lossless on low-rank matrices and preserves softmax while reducing attention complexity from $O(N^2 d)$ to $O(Ndr)$. With SVD-Attention, we propose SOLAR, SVD-Optimized Lifelong Attention for Recommendation, a sequence modeling framework that supports behavior sequences of ten-thousand scale and candidate sets of several thousand items in cascading process without any filtering. In Kuaishou's online recommendation scenario, SOLAR delivers a 0.68\% Video Views gain together with additional business metrics improvements.
FlashEvaluator: Expanding Search Space with Parallel Evaluation
Mar 03, 2026The Generator-Evaluator (G-E) framework, i.e., evaluating K sequences from a generator and selecting the top-ranked one according to evaluator scores, is a foundational paradigm in tasks such as Recommender Systems (RecSys) and Natural Language Processing (NLP). Traditional evaluators process sequences independently, suffering from two major limitations: (1) lack of explicit cross-sequence comparison, leading to suboptimal accuracy; (2) poor parallelization with linear complexity of O(K), resulting in inefficient resource utilization and negative impact on both throughput and latency. To address these challenges, we propose FlashEvaluator, which enables cross-sequence token information sharing and processes all sequences in a single forward pass. This yields sublinear computational complexity that improves the system's efficiency and supports direct inter-sequence comparisons that improve selection accuracy. The paper also provides theoretical proofs and extensive experiments on recommendation and NLP tasks, demonstrating clear advantages over conventional methods. Notably, FlashEvaluator has been deployed in online recommender system of Kuaishou, delivering substantial and sustained revenue gains in practice.
TextPecker: Rewarding Structural Anomaly Quantification for Enhancing Visual Text Rendering
Feb 26, 2026Visual Text Rendering (VTR) remains a critical challenge in text-to-image generation, where even advanced models frequently produce text with structural anomalies such as distortion, blurriness, and misalignment. However, we find that leading MLLMs and specialist OCR models largely fail to perceive these structural anomalies, creating a critical bottleneck for both VTR evaluation and RL-based optimization. As a result, even state-of-the-art generators (e.g., Seedream4.0, Qwen-Image) still struggle to render structurally faithful text. To address this, we propose TextPecker, a plug-and-play structural anomaly perceptive RL strategy that mitigates noisy reward signals and works with any textto-image generator. To enable this capability, we construct a recognition dataset with character-level structural-anomaly annotations and develop a stroke-editing synthesis engine to expand structural-error coverage. Experiments show that TextPecker consistently improves diverse text-to-image models; even on the well-optimized Qwen-Image, it significantly yields average gains of 4% in structural fidelity and 8.7% in semantic alignment for Chinese text rendering, establishing a new state-of-the-art in high-fidelity VTR. Our work fills a gap in VTR optimization, providing a foundational step towards reliable and structural faithful visual text generation.
M$^3$Searcher: Modular Multimodal Information Seeking Agency with Retrieval-Oriented Reasoning
Jan 14, 2026Recent advances in DeepResearch-style agents have demonstrated strong capabilities in autonomous information acquisition and synthesize from real-world web environments. However, existing approaches remain fundamentally limited to text modality. Extending autonomous information-seeking agents to multimodal settings introduces critical challenges: the specialization-generalization trade-off that emerges when training models for multimodal tool-use at scale, and the severe scarcity of training data capturing complex, multi-step multimodal search trajectories. To address these challenges, we propose M$^3$Searcher, a modular multimodal information-seeking agent that explicitly decouples information acquisition from answer derivation. M$^3$Searcher is optimized with a retrieval-oriented multi-objective reward that jointly encourages factual accuracy, reasoning soundness, and retrieval fidelity. In addition, we develop MMSearchVQA, a multimodal multi-hop dataset to support retrieval centric RL training. Experimental results demonstrate that M$^3$Searcher outperforms existing approaches, exhibits strong transfer adaptability and effective reasoning in complex multimodal tasks.
Masked Diffusion Captioning for Visual Feature Learning
Oct 30, 2025We learn visual features by captioning images with an image-conditioned masked diffusion language model, a formulation we call masked diffusion captioning (MDC). During training, text tokens in each image-caption pair are masked at a randomly chosen ratio, and a decoder conditioned on visual features is trained to reconstruct the original text. After training, the learned visual features can be applied to downstream vision tasks. Unlike autoregressive captioning, the strength of the visual learning signal in MDC does not depend on each token's position in the sequence, reducing the need for auxiliary objectives. Linear probing experiments across a variety of academic-scale models and datasets show that the learned visual features are competitive with those produced by autoregressive and contrastive approaches.
SAIL-Embedding Technical Report: Omni-modal Embedding Foundation Model
Oct 14, 2025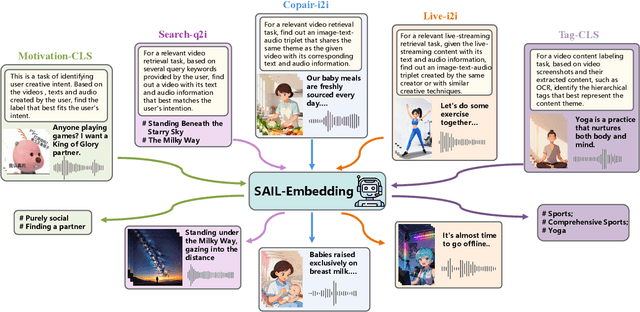

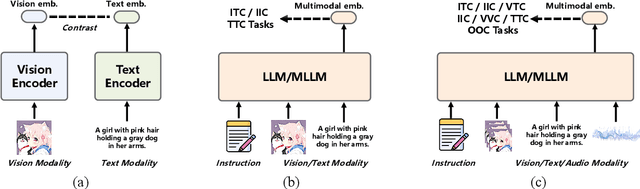
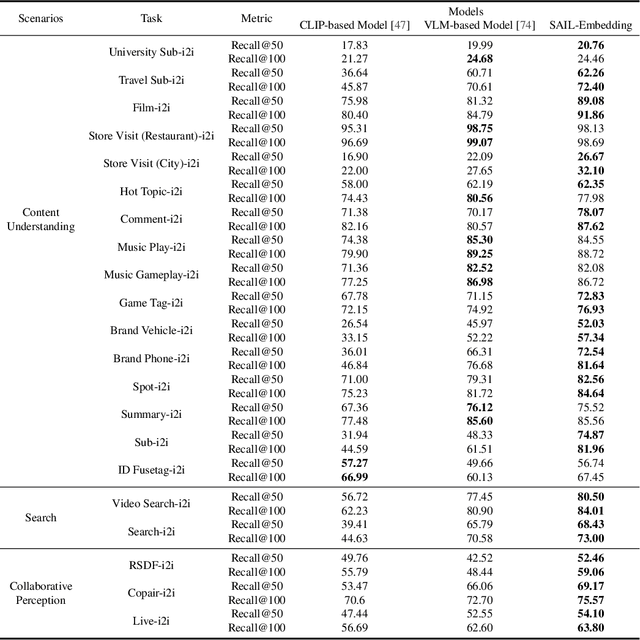
Multimodal embedding models aim to yield informative unified representations that empower diverse cross-modal tasks. Despite promising developments in the evolution from CLIP-based dual-tower architectures to large vision-language models, prior works still face unavoidable challenges in real-world applications and business scenarios, such as the limited modality support, unstable training mechanisms, and industrial domain gaps. In this work, we introduce SAIL-Embedding, an omni-modal embedding foundation model that addresses these issues through tailored training strategies and architectural design. In the optimization procedure, we propose a multi-stage training scheme to boost the multifaceted effectiveness of representation learning. Specifically, the content-aware progressive training aims to enhance the model's adaptability to diverse downstream tasks and master enriched cross-modal proficiency. The collaboration-aware recommendation enhancement training further adapts multimodal representations for recommendation scenarios by distilling knowledge from sequence-to-item and ID-to-item embeddings while mining user historical interests. Concurrently, we develop the stochastic specialization and dataset-driven pattern matching to strengthen model training flexibility and generalizability. Experimental results show that SAIL-Embedding achieves SOTA performance compared to other methods in different retrieval tasks. In online experiments across various real-world scenarios integrated with our model, we observe a significant increase in Lifetime (LT), which is a crucial indicator for the recommendation experience. For instance, the model delivers the 7-day LT gain of +0.158% and the 14-day LT gain of +0.144% in the Douyin-Selected scenario. For the Douyin feed rank model, the match features produced by SAIL-Embedding yield a +0.08% AUC gain.
SAIL-VL2 Technical Report
Sep 18, 2025We introduce SAIL-VL2, an open-suite vision-language foundation model (LVM) for comprehensive multimodal understanding and reasoning. As the successor to SAIL-VL, SAIL-VL2 achieves state-of-the-art performance at the 2B and 8B parameter scales across diverse image and video benchmarks, demonstrating strong capabilities from fine-grained perception to complex reasoning. Its effectiveness is driven by three core innovations. First, a large-scale data curation pipeline with scoring and filtering strategies enhances both quality and distribution across captioning, OCR, QA, and video data, improving training efficiency. Second, a progressive training framework begins with a powerful pre-trained vision encoder (SAIL-ViT), advances through multimodal pre-training, and culminates in a thinking-fusion SFT-RL hybrid paradigm that systematically strengthens model capabilities. Third, architectural advances extend beyond dense LLMs to efficient sparse Mixture-of-Experts (MoE) designs. With these contributions, SAIL-VL2 demonstrates competitive performance across 106 datasets and achieves state-of-the-art results on challenging reasoning benchmarks such as MMMU and MathVista. Furthermore, on the OpenCompass leaderboard, SAIL-VL2-2B ranks first among officially released open-source models under the 4B parameter scale, while serving as an efficient and extensible foundation for the open-source multimodal community.
SAILViT: Towards Robust and Generalizable Visual Backbones for MLLMs via Gradual Feature Refinement
Jul 02, 2025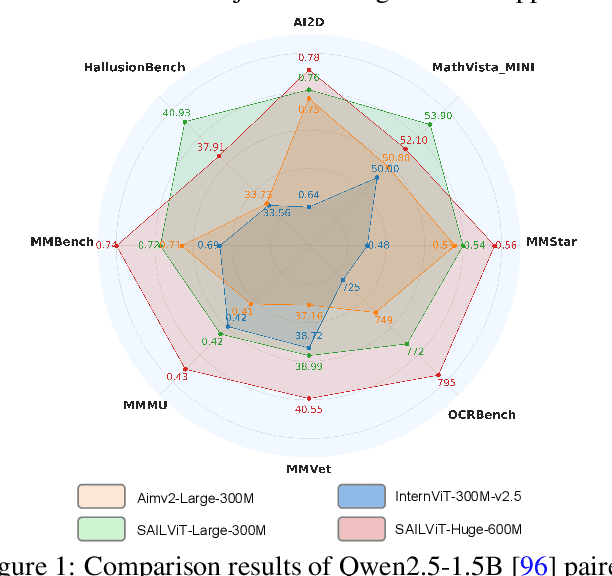
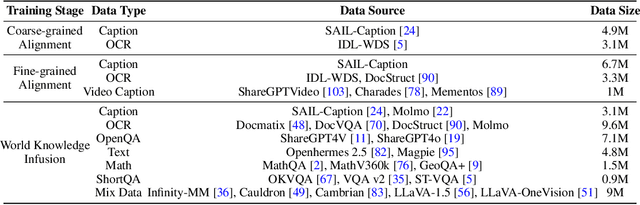
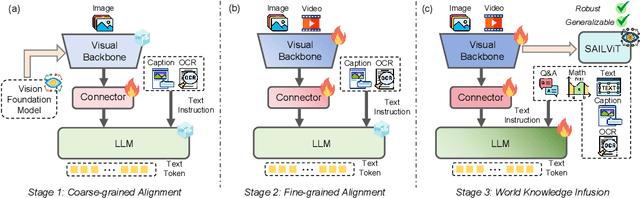
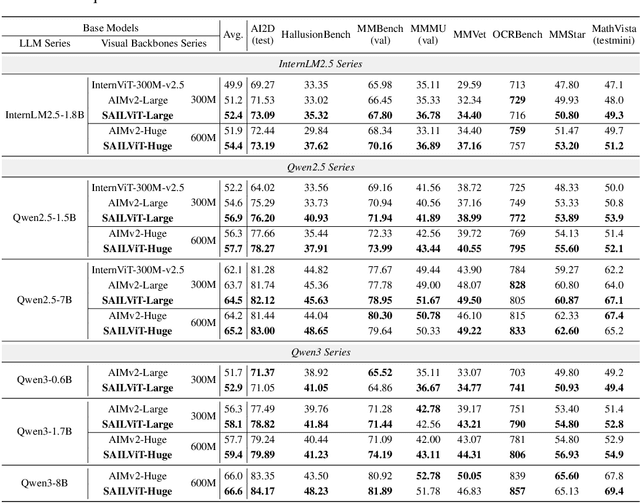
Vision Transformers (ViTs) are essential as foundation backbones in establishing the visual comprehension capabilities of Multimodal Large Language Models (MLLMs). Although most ViTs achieve impressive performance through image-text pair-based contrastive learning or self-supervised mechanisms, they struggle to engage in connector-based co-training directly with LLMs due to potential parameter initialization conflicts and modality semantic gaps. To address the above challenges, this paper proposes SAILViT, a gradual feature learning-enhanced ViT for facilitating MLLMs to break through performance bottlenecks in complex multimodal interactions. SAILViT achieves coarse-to-fine-grained feature alignment and world knowledge infusion with gradual feature refinement, which better serves target training demands. We perform thorough empirical analyses to confirm the powerful robustness and generalizability of SAILViT across different dimensions, including parameter sizes, model architectures, training strategies, and data scales. Equipped with SAILViT, existing MLLMs show significant and consistent performance improvements on the OpenCompass benchmark across extensive downstream tasks. SAILViT series models are released at https://huggingface.co/BytedanceDouyinContent.
VGR: Visual Grounded Reasoning
Jun 16, 2025In the field of multimodal chain-of-thought (CoT) reasoning, existing approaches predominantly rely on reasoning on pure language space, which inherently suffers from language bias and is largely confined to math or science domains. This narrow focus limits their ability to handle complex visual reasoning tasks that demand comprehensive understanding of image details. To address these limitations, this paper introduces VGR, a novel reasoning multimodal large language model (MLLM) with enhanced fine-grained visual perception capabilities. Unlike traditional MLLMs that answer the question or reasoning solely on the language space, our VGR first detects relevant regions that may help to solve problems, and then provides precise answers based on replayed image regions. To achieve this, we conduct a large-scale SFT dataset called VGR -SFT that contains reasoning data with mixed vision grounding and language deduction. The inference pipeline of VGR allows the model to choose bounding boxes for visual reference and a replay stage is introduced to integrates the corresponding regions into the reasoning process, enhancing multimodel comprehension. Experiments on the LLaVA-NeXT-7B baseline show that VGR achieves superior performance on multi-modal benchmarks requiring comprehensive image detail understanding. Compared to the baseline, VGR uses only 30\% of the image token count while delivering scores of +4.1 on MMStar, +7.1 on AI2D, and a +12.9 improvement on ChartQA.