 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIL-VL2 Technical Report
Sep 18, 2025We introduce SAIL-VL2, an open-suite vision-language foundation model (LVM) for comprehensive multimodal understanding and reasoning. As the successor to SAIL-VL, SAIL-VL2 achieves state-of-the-art performance at the 2B and 8B parameter scales across diverse image and video benchmarks, demonstrating strong capabilities from fine-grained perception to complex reasoning. Its effectiveness is driven by three core innovations. First, a large-scale data curation pipeline with scoring and filtering strategies enhances both quality and distribution across captioning, OCR, QA, and video data, improving training efficiency. Second, a progressive training framework begins with a powerful pre-trained vision encoder (SAIL-ViT), advances through multimodal pre-training, and culminates in a thinking-fusion SFT-RL hybrid paradigm that systematically strengthens model capabilities. Third, architectural advances extend beyond dense LLMs to efficient sparse Mixture-of-Experts (MoE) designs. With these contributions, SAIL-VL2 demonstrates competitive performance across 106 datasets and achieves state-of-the-art results on challenging reasoning benchmarks such as MMMU and MathVista. Furthermore, on the OpenCompass leaderboard, SAIL-VL2-2B ranks first among officially released open-source models under the 4B parameter scale, while serving as an efficient and extensible foundation for the open-source multimodal community.
Vision as LoRA
Mar 26, 2025We introduce Vision as LoRA (VoRA), a novel paradigm for transforming an LLM into an MLLM. Unlike prevalent MLLM architectures that rely on external vision modules for vision encoding, VoRA internalizes visual capabilities by integrating vision-specific LoRA layers directly into the LLM. This design allows the added parameters to be seamlessly merged into the LLM during inference, eliminating structural complexity and minimizing computational overhead. Moreover, inheriting the LLM's ability of handling flexible context, VoRA can process inputs at arbitrary resolutions. To further strengthen VoRA's visual capabilities, we introduce a block-wise distillation method that transfers visual priors from a pre-trained ViT into the LoRA layers, effectively accelerating training by injecting visual knowledge. Additionally, we apply bi-directional attention masks to better capture the context information of an image. We successfully demonstrate that with additional pre-training data, VoRA can perform comparably with conventional encode-based MLLMs. All training data, codes, and model weights will be released at https://github.com/Hon-Wong/VoRA.
Dynamic-VLM: Simple Dynamic Visual Token Compression for VideoLLM
Dec 12, 2024



The application of Large Vision-Language Models (LVLMs) for analyzing images and videos is an exciting and rapidly evolving field. In recent years, we've seen significant growth in high-quality image-text datasets for fine-tuning image understanding, but there is still a lack of comparable datasets for videos. Additionally, many VideoLLMs are extensions of single-image VLMs, which may not efficiently handle the complexities of longer videos. In this study, we introduce a large-scale synthetic dataset created from proprietary models, using carefully designed prompts to tackle a wide range of questions. We also explore a dynamic visual token compression architecture that strikes a balance between computational efficiency and performance. Our proposed \model{} achieves state-of-the-art results across various video tasks and shows impressive generalization, setting new baselines in multi-image understanding. Notably, \model{} delivers an absolute improvement of 2.7\% over LLaVA-OneVision on VideoMME and 10.7\% on MuirBench. Codes are available at https://github.com/Hon-Wong/ByteVideoLLM
A Bounding Box is Worth One Token: Interleaving Layout and Text in a Large Language Model for Document Understanding
Jul 02, 2024



Recently, many studies have demonstrated that exclusively incorporating OCR-derived text and spatial layouts with large language models (LLMs) can be highly effective for document understanding tasks. However, existing methods that integrate spatial layouts with text have limitations, such as producing overly long text sequences or failing to fully leverage the autoregressive traits of LLMs. In this work, we introduce Interleaving Layout and Text in a Large Language Model (LayTextLLM)} for document understanding. In particular, LayTextLLM projects each bounding box to a single embedding and interleaves it with text, efficiently avoiding long sequence issues while leveraging autoregressive traits of LLMs. LayTextLLM not only streamlines the interaction of layout and textual data but also shows enhanced performance in Key Information Extraction (KIE) and Visual Question Answering (VQA). Comprehensive benchmark evaluations reveal significant improvements, with a 27.0% increase on KIE tasks and 24.1% on VQA tasks compared to previous state-of-the-art document understanding MLLMs, as well as a 15.5% improvement over other SOTA OCR-based LLMs on KIE tasks.
TabPedia: Towards Comprehensive Visual Table Understanding with Concept Synergy
Jun 03, 2024



Tables contain factual and quantitative data accompanied by various structures and contents that pose challenges for machine comprehension. Previous methods generally design task-specific architectures and objectives for individual tasks, resulting in modal isolation and intricate workflows. In this paper, we present a novel large vision-language model, TabPedia, equipped with a concept synergy mechanism. In this mechanism, all the involved diverse visual table understanding (VTU) tasks and multi-source visual embeddings are abstracted as concepts. This unified framework allows TabPedia to seamlessly integrate VTU tasks, such as table detection, table structure recognition, table querying, and table question answering, by leveraging the capabilities of large language models (LLMs). Moreover, the concept synergy mechanism enables table perception-related and comprehension-related tasks to work in harmony, as they can effectively leverage the needed clues from the corresponding source perception embeddings. Furthermore, to better evaluate the VTU task in real-world scenarios, we establish a new and comprehensive table VQA benchmark, ComTQA, featuring approximately 9,000 QA pairs. Extensive quantitative and qualitative experiments on both table perception and comprehension tasks, conducted across various public benchmarks, validate the effectiveness of our TabPedia. The superior performance further confirms the feasibility of using LLMs for understanding visual tables when all concepts work in synergy. The benchmark ComTQA has been open-sourced at https://huggingface.co/datasets/ByteDance/ComTQA. The source code and model will be released later.
MTVQA: Benchmarking Multilingual Text-Centric Visual Question Answering
May 20, 2024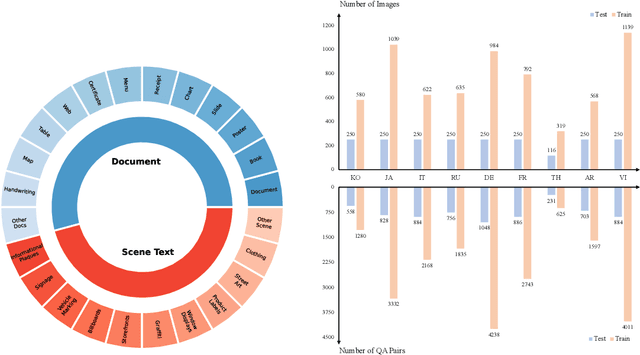
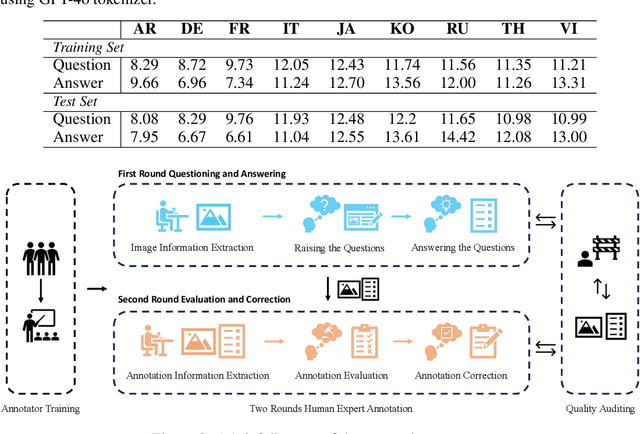

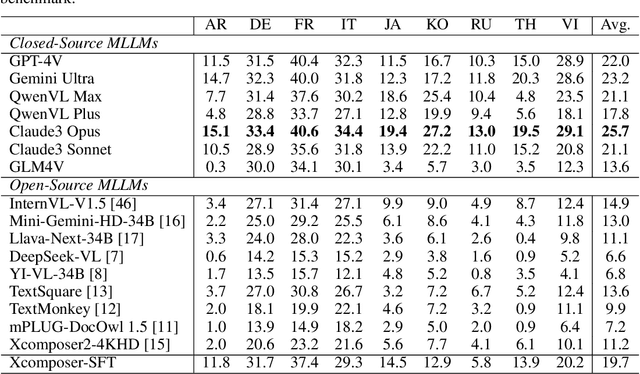
Text-Centric Visual Question Answering (TEC-VQA) in its proper format not only facilitates human-machine interaction in text-centric visual environments but also serves as a de facto gold proxy to evaluate AI models in the domain of text-centric scene understanding. However, most TEC-VQA benchmarks have focused on high-resource languages like English and Chinese. Despite pioneering works to expand multilingual QA pairs in non-text-centric VQA datasets using translation engines, the translation-based protocol encounters a substantial ``Visual-textual misalignment'' problem when applied to TEC-VQA. Specifically, it prioritizes the text in question-answer pairs while disregarding the visual text present in images. Furthermore, it does not adequately tackle challenges related to nuanced meaning, contextual distortion, language bias, and question-type diversity. In this work, we address the task of multilingual TEC-VQA and provide a benchmark with high-quality human expert annotations in 9 diverse languages, called MTVQA. To our knowledge, MTVQA is the first multilingual TEC-VQA benchmark to provide human expert annotations for text-centric scenarios. Further, by evaluating several state-of-the-art Multimodal Large Language Models (MLLMs), including GPT-4V, on our MTVQA dataset, it is evident that there is still room for performance improvement, underscoring the value of our dataset. We hope this dataset will provide researchers with fresh perspectives and inspiration within the community. The MTVQA dataset will be available at https://huggingface.co/datasets/ByteDance/MTVQA.
Elysium: Exploring Object-level Perception in Videos via MLLM
Mar 29, 2024Multi-modal Large Language Models (MLLMs) have demonstrated their ability to perceive objects in still images, but their application in video-related tasks, such as object tracking, remains understudied. This lack of exploration is primarily due to two key challenges. Firstly, extensive pretraining on large-scale video datasets is required to equip MLLMs with the capability to perceive objects across multiple frames and understand inter-frame relationships. Secondly, processing a large number of frames within the context window of Large Language Models (LLMs) can impose a significant computational burden. To address the first challenge, we introduce ElysiumTrack-1M, a large-scale video dataset supported for three tasks: Single Object Tracking (SOT), Referring Single Object Tracking (RSOT), and Video Referring Expression Generation (Video-REG). ElysiumTrack-1M contains 1.27 million annotated video frames with corresponding object boxes and descriptions. Leveraging this dataset, we conduct training of MLLMs and propose a token-compression model T-Selector to tackle the second challenge. Our proposed approach, Elysium: Exploring Object-level Perception in Videos via MLLM, is an end-to-end trainable MLLM that attempts to conduct object-level tasks in videos without requiring any additional plug-in or expert models. All codes and datasets are available at https://github.com/Hon-Wong/Elysium.