 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDolphin-v2: Universal Document Parsing via Scalable Anchor Prompting
Feb 05, 2026Document parsing has garnered widespread attention as vision-language models (VLMs) advance OCR capabilities. However, the field remains fragmented across dozens of specialized models with varying strengths, forcing users to navigate complex model selection and limiting system scalability. Moreover, existing two-stage approaches depend on axis-aligned bounding boxes for layout detection, failing to handle distorted or photographed documents effectively. To this end, we present Dolphin-v2, a two-stage document image parsing model that substantially improves upon the original Dolphin. In the first stage, Dolphin-v2 jointly performs document type classification (digital-born versus photographed) alongside layout analysis. For digital-born documents, it conducts finer-grained element detection with reading order prediction. In the second stage, we employ a hybrid parsing strategy: photographed documents are parsed holistically as complete pages to handle geometric distortions, while digital-born documents undergo element-wise parallel parsing guided by the detected layout anchors, enabling efficient content extraction. Compared with the original Dolphin, Dolphin-v2 introduces several crucial enhancements: (1) robust parsing of photographed documents via holistic page-level understanding, (2) finer-grained element detection (21 categories) with semantic attribute extraction such as author information and document metadata, and (3) code block recognition with indentation preservation, which existing systems typically lack. Comprehensive evaluations are conducted on DocPTBench, OmniDocBench, and our self-constructed RealDoc-160 benchmark. The results demonstrate substantial improvements: +14.78 points overall on the challenging OmniDocBench and 91% error reduction on photographed documents, while maintaining efficient inference through parallel processing.
Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting
May 20, 2025Document image parsing is challenging due to its complexly intertwined elements such as text paragraphs, figures, formulas, and tables. Current approaches either assemble specialized expert models or directly generate page-level content autoregressively, facing integration overhead, efficiency bottlenecks, and layout structure degradation despite their decent performance. To address these limitations, we present \textit{Dolphin} (\textit{\textbf{Do}cument Image \textbf{P}arsing via \textbf{H}eterogeneous Anchor Prompt\textbf{in}g}), a novel multimodal document image parsing model following an analyze-then-parse paradigm. In the first stage, Dolphin generates a sequence of layout elements in reading order. These heterogeneous elements, serving as anchors and coupled with task-specific prompts, are fed back to Dolphin for parallel content parsing in the second stage. To train Dolphin, we construct a large-scale dataset of over 30 million samples, covering multi-granularity parsing tasks. Through comprehensive evaluations on both prevalent benchmarks and self-constructed ones, Dolphin achieves state-of-the-art performance across diverse page-level and element-level settings, while ensuring superior efficiency through its lightweight architecture and parallel parsing mechanism. The code and pre-trained models are publicly available at https://github.com/ByteDance/Dolphin
MCTBench: Multimodal Cognition towards Text-Rich Visual Scenes Benchmark
Oct 15, 2024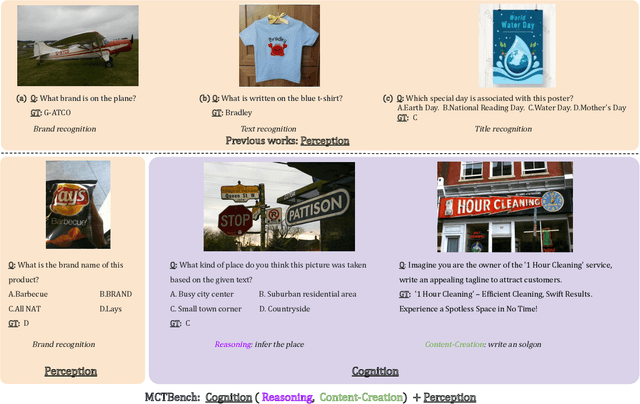
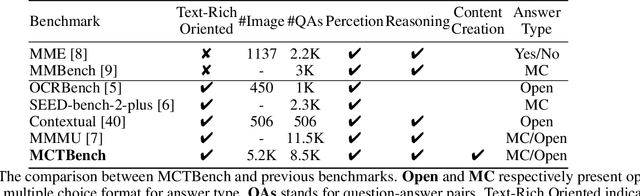
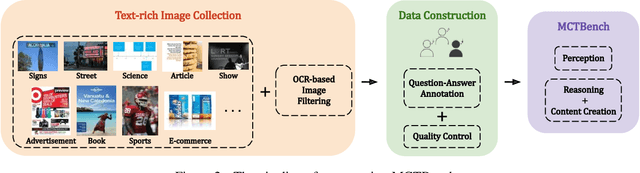
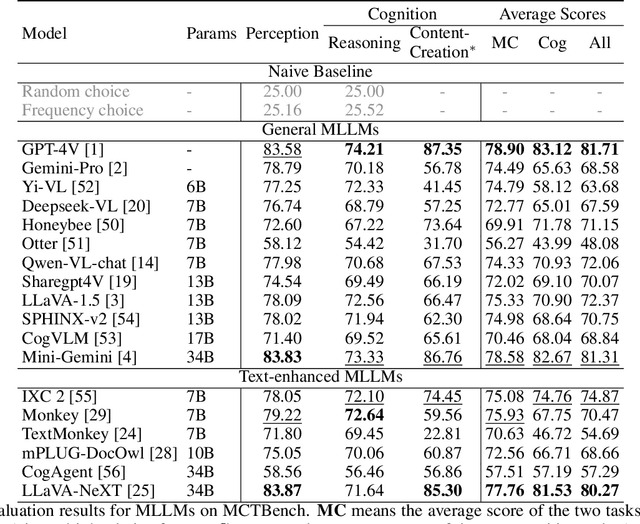
The comprehension of text-rich visual scenes has become a focal point for evaluating Multi-modal Large Language Models (MLLMs) due to their widespread applications. Current benchmarks tailored to the scenario emphasize perceptual capabilities, while overlooking the assessment of cognitive abilities. To address this limitation, we introduce a Multimodal benchmark towards Text-rich visual scenes, to evaluate the Cognitive capabilities of MLLMs through visual reasoning and content-creation tasks (MCTBench). To mitigate potential evaluation bias from the varying distributions of datasets, MCTBench incorporates several perception tasks (e.g., scene text recognition) to ensure a consistent comparison of both the cognitive and perceptual capabilities of MLLMs. To improve the efficiency and fairness of content-creation evaluation, we conduct an automatic evaluation pipeline. Evaluations of various MLLMs on MCTBench reveal that, despite their impressive perceptual capabilities, their cognition abilities require enhancement. We hope MCTBench will offer the community an efficient resource to explore and enhance cognitive capabilities towards text-rich visual scenes.
ParGo: Bridging Vision-Language with Partial and Global Views
Aug 23, 2024
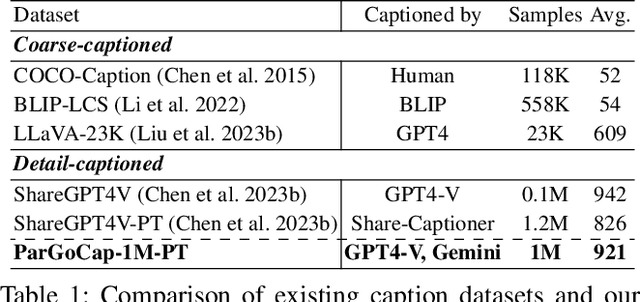
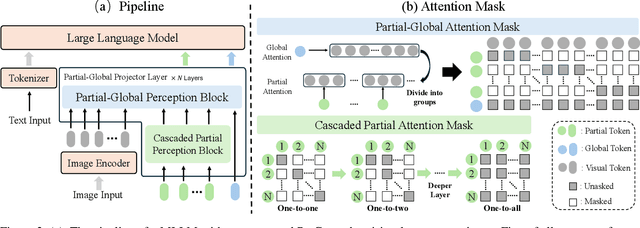
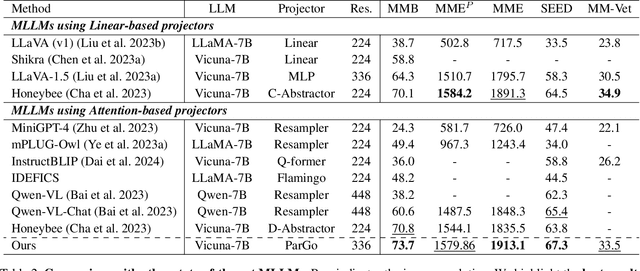
This work presents ParGo, a novel Partial-Global projector designed to connect the vision and language modalities for Multimodal Large Language Models (MLLMs). Unlike previous works that rely on global attention-based projectors, our ParGo bridges the representation gap between the separately pre-trained vision encoders and the LLMs by integrating global and partial views, which alleviates the overemphasis on prominent regions. To facilitate the effective training of ParGo, we collect a large-scale detail-captioned image-text dataset named ParGoCap-1M-PT, consisting of 1 million images paired with high-quality captions. Extensive experiments on several MLLM benchmarks demonstrate the effectiveness of our ParGo, highlighting its superiority in aligning vision and language modalities. Compared to conventional Q-Former projector, our ParGo achieves an improvement of 259.96 in MME benchmark. Furthermore, our experiments reveal that ParGo significantly outperforms other projectors, particularly in tasks that emphasize detail perception ability.
TabPedia: Towards Comprehensive Visual Table Understanding with Concept Synergy
Jun 03, 2024



Tables contain factual and quantitative data accompanied by various structures and contents that pose challenges for machine comprehension. Previous methods generally design task-specific architectures and objectives for individual tasks, resulting in modal isolation and intricate workflows. In this paper, we present a novel large vision-language model, TabPedia, equipped with a concept synergy mechanism. In this mechanism, all the involved diverse visual table understanding (VTU) tasks and multi-source visual embeddings are abstracted as concepts. This unified framework allows TabPedia to seamlessly integrate VTU tasks, such as table detection, table structure recognition, table querying, and table question answering, by leveraging the capabilities of large language models (LLMs). Moreover, the concept synergy mechanism enables table perception-related and comprehension-related tasks to work in harmony, as they can effectively leverage the needed clues from the corresponding source perception embeddings. Furthermore, to better evaluate the VTU task in real-world scenarios, we establish a new and comprehensive table VQA benchmark, ComTQA, featuring approximately 9,000 QA pairs. Extensive quantitative and qualitative experiments on both table perception and comprehension tasks, conducted across various public benchmarks, validate the effectiveness of our TabPedia. The superior performance further confirms the feasibility of using LLMs for understanding visual tables when all concepts work in synergy. The benchmark ComTQA has been open-sourced at https://huggingface.co/datasets/ByteDance/ComTQA. The source code and model will be released later.
TextSquare: Scaling up Text-Centric Visual Instruction Tuning
Apr 19, 2024



Text-centric visual question answering (VQA) has made great strides with the development of Multimodal Large Language Models (MLLMs), yet open-source models still fall short of leading models like GPT4V and Gemini, partly due to a lack of extensive, high-quality instruction tuning data. To this end, we introduce a new approach for creating a massive, high-quality instruction-tuning dataset, Square-10M, which is generated using closed-source MLLMs. The data construction process, termed Square, consists of four steps: Self-Questioning, Answering, Reasoning, and Evaluation. Our experiments with Square-10M led to three key findings: 1) Our model, TextSquare, considerably surpasses open-source previous state-of-the-art Text-centric MLLMs and sets a new standard on OCRBench(62.2%). It even outperforms top-tier models like GPT4V and Gemini in 6 of 10 text-centric benchmarks. 2) Additionally, we demonstrate the critical role of VQA reasoning data in offering comprehensive contextual insights for specific questions. This not only improves accuracy but also significantly mitigates hallucinations. Specifically, TextSquare scores an average of 75.1% across four general VQA and hallucination evaluation datasets, outperforming previous state-of-the-art models. 3) Notably, the phenomenon observed in scaling text-centric VQA datasets reveals a vivid pattern: the exponential increase of instruction tuning data volume is directly proportional to the improvement in model performance, thereby validating the necessity of the dataset scale and the high quality of Square-10M.
RViDeformer: Efficient Raw Video Denoising Transformer with a Larger Benchmark Dataset
May 01, 2023



In recent years, raw video denoising has garnered increased attention due to the consistency with the imaging process and well-studied noise modeling in the raw domain. However, two problems still hinder the denoising performance. Firstly, there is no large dataset with realistic motions for supervised raw video denoising, as capturing noisy and clean frames for real dynamic scenes is difficult. To address this, we propose recapturing existing high-resolution videos displayed on a 4K screen with high-low ISO settings to construct noisy-clean paired frames. In this way, we construct a video denoising dataset (named as ReCRVD) with 120 groups of noisy-clean videos, whose ISO values ranging from 1600 to 25600. Secondly, while non-local temporal-spatial attention is beneficial for denoising, it often leads to heavy computation costs. We propose an efficient raw video denoising transformer network (RViDeformer) that explores both short and long-distance correlations. Specifically, we propose multi-branch spatial and temporal attention modules, which explore the patch correlations from local window, local low-resolution window, global downsampled window, and neighbor-involved window, and then they are fused together. We employ reparameterization to reduce computation costs. Our network is trained in both supervised and unsupervised manners, achieving the best performance compared with state-of-the-art methods. Additionally, the model trained with our proposed dataset (ReCRVD) outperforms the model trained with previous benchmark dataset (CRVD) when evaluated on the real-world outdoor noisy videos. Our code and dataset will be released after the acceptance of this work.
DSBERT:Unsupervised Dialogue Structure learning with BERT
Nov 09, 2021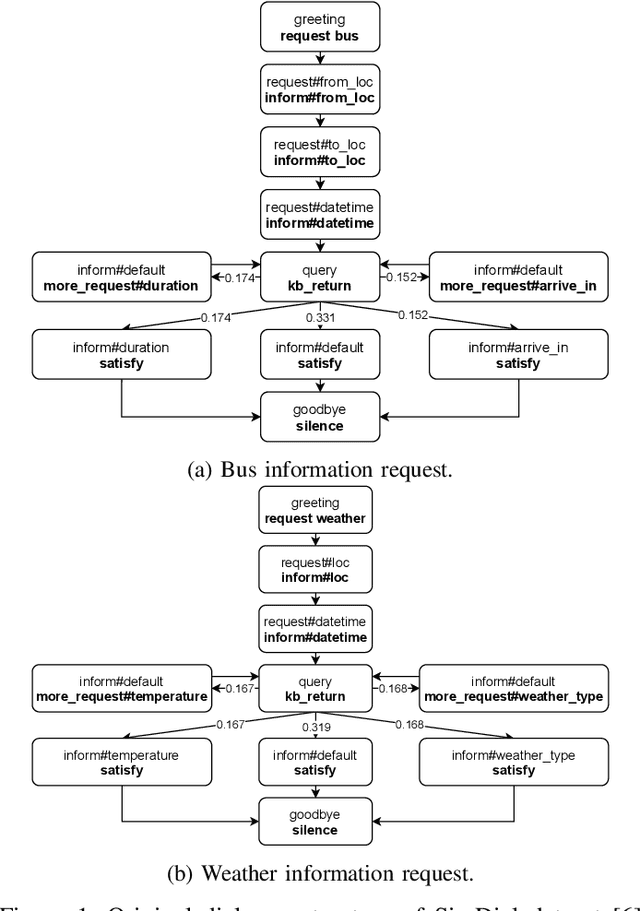

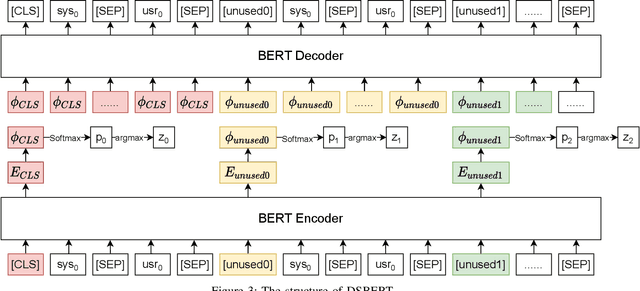

Unsupervised dialogue structure learning is an important and meaningful task in natural language processing. The extracted dialogue structure and process can help analyze human dialogue, and play a vital role in the design and evaluation of dialogue systems. The traditional dialogue system requires experts to manually design the dialogue structure, which is very costly. But through unsupervised dialogue structure learning, dialogue structure can be automatically obtained, reducing the cost of developers constructing dialogue process. The learned dialogue structure can be used to promote the dialogue generation of the downstream task system, and improve the logic and consistency of the dialogue robot's reply.In this paper, we propose a Bert-based unsupervised dialogue structure learning algorithm DSBERT (Dialogue Structure BERT). Different from the previous SOTA models VRNN and SVRNN, we combine BERT and AutoEncoder, which can effectively combine context information. In order to better prevent the model from falling into the local optimal solution and make the dialogue state distribution more uniform and reasonable, we also propose three balanced loss functions that can be used for dialogue structure learning. Experimental results show that DSBERT can generate a dialogue structure closer to the real structure, can distinguish sentences with different semantics and map them to different hidden states.
Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes
Mar 31, 2020

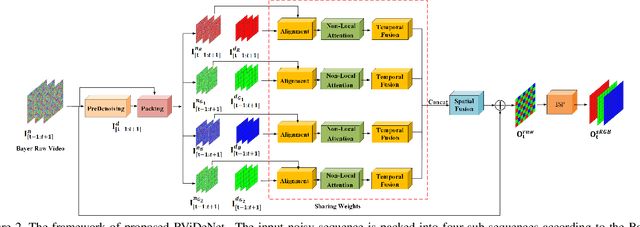
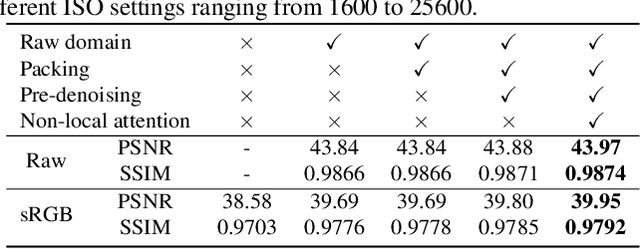
In recent years, the supervised learning strategy for real noisy image denoising has been emerging and has achieved promising results. In contrast, realistic noise removal for raw noisy videos is rarely studied due to the lack of noisy-clean pairs for dynamic scenes. Clean video frames for dynamic scenes cannot be captured with a long-exposure shutter or averaging multi-shots as was done for static images. In this paper, we solve this problem by creating motions for controllable objects, such as toys, and capturing each static moment for multiple times to generate clean video frames. In this way, we construct a dataset with 55 groups of noisy-clean videos with ISO values ranging from 1600 to 25600. To our knowledge, this is the first dynamic video dataset with noisy-clean pairs. Correspondingly, we propose a raw video denoising network (RViDeNet) by exploring the temporal, spatial, and channel correlations of video frames. Since the raw video has Bayer patterns, we pack it into four sub-sequences, i.e RGBG sequences, which are denoised by the proposed RViDeNet separately and finally fused into a clean video. In addition, our network not only outputs a raw denoising result, but also the sRGB result by going through an image signal processing (ISP) module, which enables users to generate the sRGB result with their favourite ISPs. Experimental results demonstrate that our method outperforms state-of-the-art video and raw image denoising algorithms on both indoor and outdoor videos.