 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextPecker: Rewarding Structural Anomaly Quantification for Enhancing Visual Text Rendering
Feb 26, 2026Visual Text Rendering (VTR) remains a critical challenge in text-to-image generation, where even advanced models frequently produce text with structural anomalies such as distortion, blurriness, and misalignment. However, we find that leading MLLMs and specialist OCR models largely fail to perceive these structural anomalies, creating a critical bottleneck for both VTR evaluation and RL-based optimization. As a result, even state-of-the-art generators (e.g., Seedream4.0, Qwen-Image) still struggle to render structurally faithful text. To address this, we propose TextPecker, a plug-and-play structural anomaly perceptive RL strategy that mitigates noisy reward signals and works with any textto-image generator. To enable this capability, we construct a recognition dataset with character-level structural-anomaly annotations and develop a stroke-editing synthesis engine to expand structural-error coverage. Experiments show that TextPecker consistently improves diverse text-to-image models; even on the well-optimized Qwen-Image, it significantly yields average gains of 4% in structural fidelity and 8.7% in semantic alignment for Chinese text rendering, establishing a new state-of-the-art in high-fidelity VTR. Our work fills a gap in VTR optimization, providing a foundational step towards reliable and structural faithful visual text generation.
Advancing Sequential Numerical Prediction in Autoregressive Models
May 19, 2025Autoregressive models have become the de facto choice for sequence generation tasks, but standard approaches treat digits as independent tokens and apply cross-entropy loss, overlooking the coherent structure of numerical sequences. This paper introduces Numerical Token Integrity Loss (NTIL) to address this gap. NTIL operates at two levels: (1) token-level, where it extends the Earth Mover's Distance (EMD) to preserve ordinal relationships between numerical values, and (2) sequence-level, where it penalizes the overall discrepancy between the predicted and actual sequences. This dual approach improves numerical prediction and integrates effectively with LLMs/MLLMs. Extensive experiments show significant performance improvements with NTIL.
WildDoc: How Far Are We from Achieving Comprehensive and Robust Document Understanding in the Wild?
May 16, 2025The rapid advancements in Multimodal Large Language Models (MLLMs) have significantly enhanced capabilities in Document Understanding. However, prevailing benchmarks like DocVQA and ChartQA predominantly comprise \textit{scanned or digital} documents, inadequately reflecting the intricate challenges posed by diverse real-world scenarios, such as variable illumination and physical distortions. This paper introduces WildDoc, the inaugural benchmark designed specifically for assessing document understanding in natural environments. WildDoc incorporates a diverse set of manually captured document images reflecting real-world conditions and leverages document sources from established benchmarks to facilitate comprehensive comparisons with digital or scanned documents. Further, to rigorously evaluate model robustness, each document is captured four times under different conditions. Evaluations of state-of-the-art MLLMs on WildDoc expose substantial performance declines and underscore the models' inadequate robustness compared to traditional benchmarks, highlighting the unique challenges posed by real-world document understanding. Our project homepage is available at https://bytedance.github.io/WildDoc.
Task-Oriented 6-DoF Grasp Pose Detection in Clutters
Feb 24, 2025

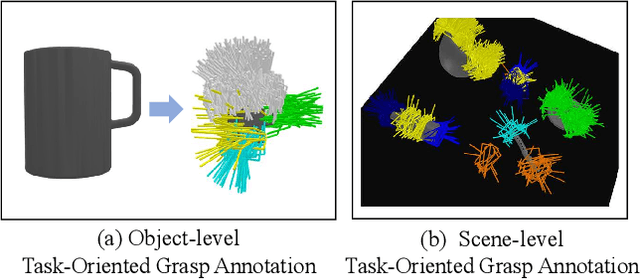

In general, humans would grasp an object differently for different tasks, e.g., "grasping the handle of a knife to cut" vs. "grasping the blade to hand over". In the field of robotic grasp pose detection research, some existing works consider this task-oriented grasping and made some progress, but they are generally constrained by low-DoF gripper type or non-cluttered setting, which is not applicable for human assistance in real life. With an aim to get more general and practical grasp models, in this paper, we investigate the problem named Task-Oriented 6-DoF Grasp Pose Detection in Clutters (TO6DGC), which extends the task-oriented problem to a more general 6-DOF Grasp Pose Detection in Cluttered (multi-object) scenario. To this end, we construct a large-scale 6-DoF task-oriented grasping dataset, 6-DoF Task Grasp (6DTG), which features 4391 cluttered scenes with over 2 million 6-DoF grasp poses. Each grasp is annotated with a specific task, involving 6 tasks and 198 objects in total. Moreover, we propose One-Stage TaskGrasp (OSTG), a strong baseline to address the TO6DGC problem. Our OSTG adopts a task-oriented point selection strategy to detect where to grasp, and a task-oriented grasp generation module to decide how to grasp given a specific task. To evaluate the effectiveness of OSTG, extensive experiments are conducted on 6DTG. The results show that our method outperforms various baselines on multiple metrics. Real robot experiments also verify that our OSTG has a better perception of the task-oriented grasp points and 6-DoF grasp poses.
TechCoach: Towards Technical Keypoint-Aware Descriptive Action Coaching
Nov 26, 2024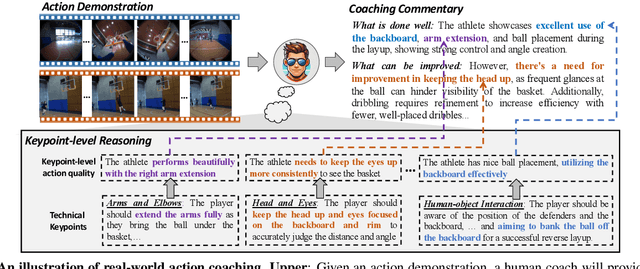
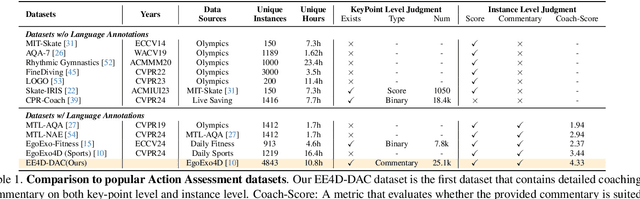
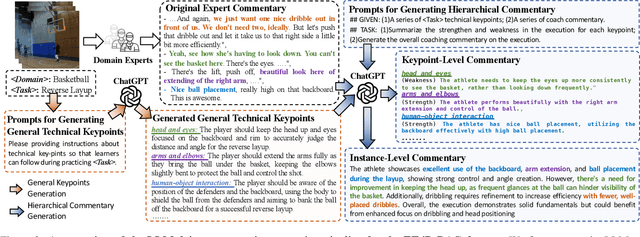

To guide a learner to master the action skills, it is crucial for a coach to 1) reason through the learner's action execution and technical keypoints, and 2) provide detailed, understandable feedback on what is done well and what can be improved. However, existing score-based action assessment methods are still far from this practical scenario. To bridge this gap, we investigate a new task termed Descriptive Action Coaching (DAC) which requires a model to provide detailed commentary on what is done well and what can be improved beyond a quality score from an action execution. To this end, we construct a new dataset named EE4D-DAC. With an LLM-based annotation pipeline, our dataset goes beyond the existing action assessment datasets by providing the hierarchical coaching commentary at both keypoint and instance levels. Furthermore, we propose TechCoach, a new framework that explicitly incorporates keypoint-level reasoning into the DAC process. The central to our method lies in the Context-aware Keypoint Reasoner, which enables TechCoach to learn keypoint-related quality representations by querying visual context under the supervision of keypoint-level coaching commentary. Prompted by the visual context and the keypoint-related quality representations, a unified Keypoint-aware Action Assessor is then employed to provide the overall coaching commentary together with the quality score. Combining all of these, we build a new benchmark for DAC and evaluate the effectiveness of our method through extensive experiments. Data and code will be publicly available.
MCTBench: Multimodal Cognition towards Text-Rich Visual Scenes Benchmark
Oct 15, 2024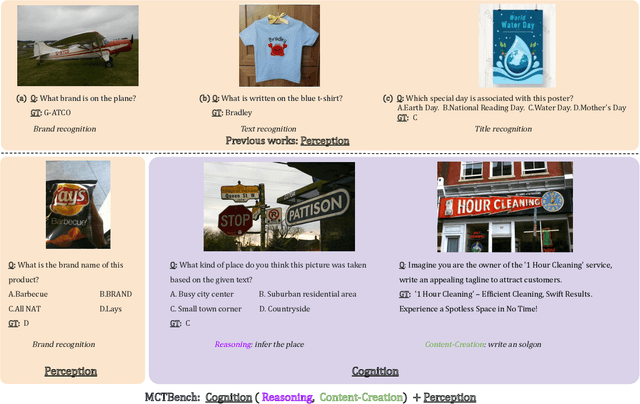
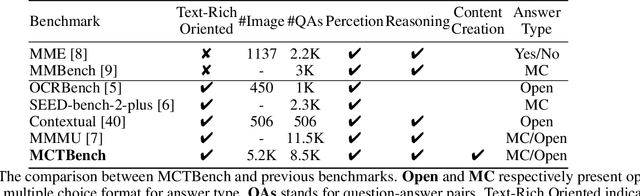
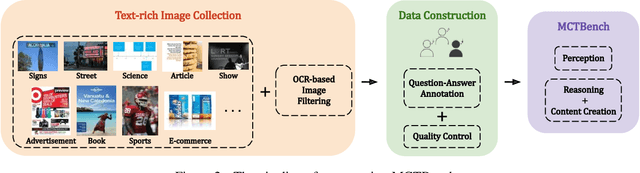
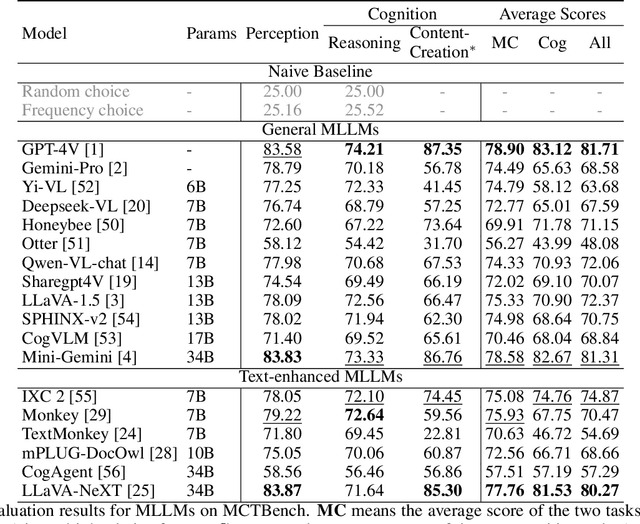
The comprehension of text-rich visual scenes has become a focal point for evaluating Multi-modal Large Language Models (MLLMs) due to their widespread applications. Current benchmarks tailored to the scenario emphasize perceptual capabilities, while overlooking the assessment of cognitive abilities. To address this limitation, we introduce a Multimodal benchmark towards Text-rich visual scenes, to evaluate the Cognitive capabilities of MLLMs through visual reasoning and content-creation tasks (MCTBench). To mitigate potential evaluation bias from the varying distributions of datasets, MCTBench incorporates several perception tasks (e.g., scene text recognition) to ensure a consistent comparison of both the cognitive and perceptual capabilities of MLLMs. To improve the efficiency and fairness of content-creation evaluation, we conduct an automatic evaluation pipeline. Evaluations of various MLLMs on MCTBench reveal that, despite their impressive perceptual capabilities, their cognition abilities require enhancement. We hope MCTBench will offer the community an efficient resource to explore and enhance cognitive capabilities towards text-rich visual scenes.
ParGo: Bridging Vision-Language with Partial and Global Views
Aug 23, 2024
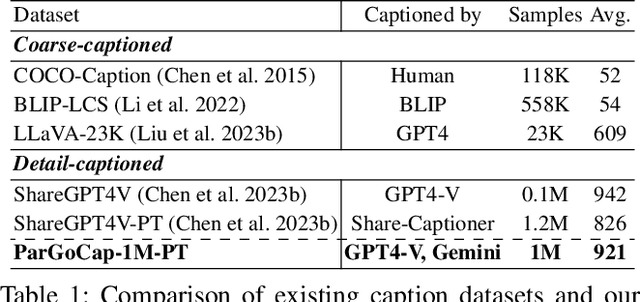
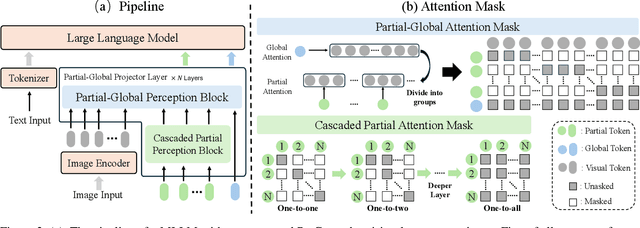
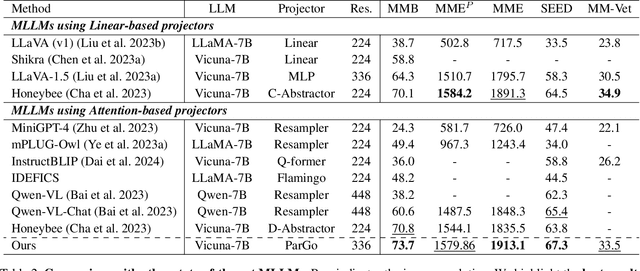
This work presents ParGo, a novel Partial-Global projector designed to connect the vision and language modalities for Multimodal Large Language Models (MLLMs). Unlike previous works that rely on global attention-based projectors, our ParGo bridges the representation gap between the separately pre-trained vision encoders and the LLMs by integrating global and partial views, which alleviates the overemphasis on prominent regions. To facilitate the effective training of ParGo, we collect a large-scale detail-captioned image-text dataset named ParGoCap-1M-PT, consisting of 1 million images paired with high-quality captions. Extensive experiments on several MLLM benchmarks demonstrate the effectiveness of our ParGo, highlighting its superiority in aligning vision and language modalities. Compared to conventional Q-Former projector, our ParGo achieves an improvement of 259.96 in MME benchmark. Furthermore, our experiments reveal that ParGo significantly outperforms other projectors, particularly in tasks that emphasize detail perception ability.
EgoExo-Fitness: Towards Egocentric and Exocentric Full-Body Action Understanding
Jun 13, 2024We present EgoExo-Fitness, a new full-body action understanding dataset, featuring fitness sequence videos recorded from synchronized egocentric and fixed exocentric (third-person) cameras. Compared with existing full-body action understanding datasets, EgoExo-Fitness not only contains videos from first-person perspectives, but also provides rich annotations. Specifically, two-level temporal boundaries are provided to localize single action videos along with sub-steps of each action. More importantly, EgoExo-Fitness introduces innovative annotations for interpretable action judgement--including technical keypoint verification, natural language comments on action execution, and action quality scores. Combining all of these, EgoExo-Fitness provides new resources to study egocentric and exocentric full-body action understanding across dimensions of "what", "when", and "how well". To facilitate research on egocentric and exocentric full-body action understanding, we construct benchmarks on a suite of tasks (i.e., action classification, action localization, cross-view sequence verification, cross-view skill determination, and a newly proposed task of guidance-based execution verification), together with detailed analysis. Code and data will be available at https://github.com/iSEE-Laboratory/EgoExo-Fitness/tree/main.
Event-Guided Procedure Planning from Instructional Videos with Text Supervision
Aug 17, 2023In this work, we focus on the task of procedure planning from instructional videos with text supervision, where a model aims to predict an action sequence to transform the initial visual state into the goal visual state. A critical challenge of this task is the large semantic gap between observed visual states and unobserved intermediate actions, which is ignored by previous works. Specifically, this semantic gap refers to that the contents in the observed visual states are semantically different from the elements of some action text labels in a procedure. To bridge this semantic gap, we propose a novel event-guided paradigm, which first infers events from the observed states and then plans out actions based on both the states and predicted events. Our inspiration comes from that planning a procedure from an instructional video is to complete a specific event and a specific event usually involves specific actions. Based on the proposed paradigm, we contribute an Event-guided Prompting-based Procedure Planning (E3P) model, which encodes event information into the sequential modeling process to support procedure planning. To further consider the strong action associations within each event, our E3P adopts a mask-and-predict approach for relation mining, incorporating a probabilistic masking scheme for regularization. Extensive experiments on three datasets demonstrate the effectiveness of our proposed model.