 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionArt: Advancing Multimodal Large Models for Fine-Grained Human-Centric Video Understanding
Apr 25, 2025
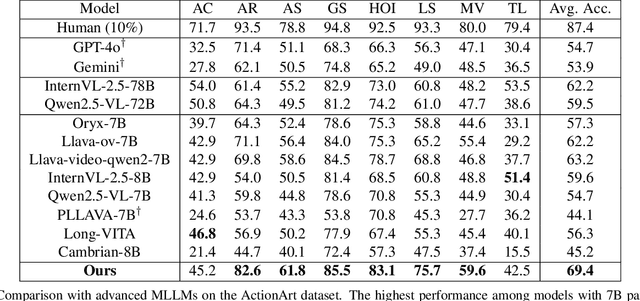
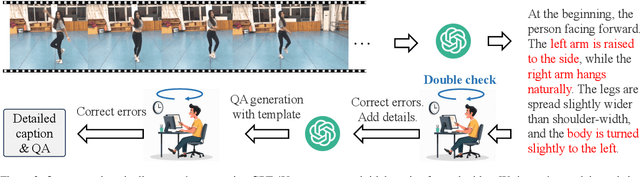
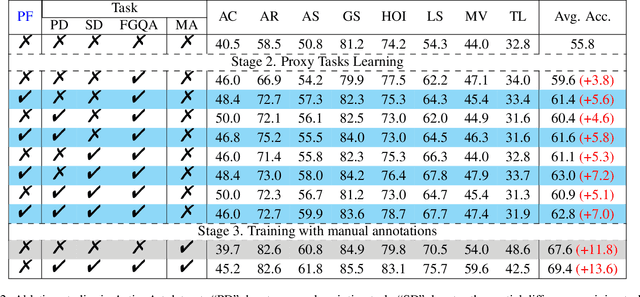
Fine-grained understanding of human actions and poses in videos is essential for human-centric AI applications. In this work, we introduce ActionArt, a fine-grained video-caption dataset designed to advance research in human-centric multimodal understanding. Our dataset comprises thousands of videos capturing a broad spectrum of human actions, human-object interactions, and diverse scenarios, each accompanied by detailed annotations that meticulously label every limb movement. We develop eight sub-tasks to evaluate the fine-grained understanding capabilities of existing large multimodal models across different dimensions. Experimental results indicate that, while current large multimodal models perform commendably on various tasks, they often fall short in achieving fine-grained understanding. We attribute this limitation to the scarcity of meticulously annotated data, which is both costly and difficult to scale manually. Since manual annotations are costly and hard to scale, we propose proxy tasks to enhance the model perception ability in both spatial and temporal dimensions. These proxy tasks are carefully crafted to be driven by data automatically generated from existing MLLMs, thereby reducing the reliance on costly manual labels. Experimental results show that the proposed proxy tasks significantly narrow the gap toward the performance achieved with manually annotated fine-grained data.
Modeling Multiple Normal Action Representations for Error Detection in Procedural Tasks
Apr 02, 2025



Error detection in procedural activities is essential for consistent and correct outcomes in AR-assisted and robotic systems. Existing methods often focus on temporal ordering errors or rely on static prototypes to represent normal actions. However, these approaches typically overlook the common scenario where multiple, distinct actions are valid following a given sequence of executed actions. This leads to two issues: (1) the model cannot effectively detect errors using static prototypes when the inference environment or action execution distribution differs from training; and (2) the model may also use the wrong prototypes to detect errors if the ongoing action label is not the same as the predicted one. To address this problem, we propose an Adaptive Multiple Normal Action Representation (AMNAR) framework. AMNAR predicts all valid next actions and reconstructs their corresponding normal action representations, which are compared against the ongoing action to detect errors. Extensive experiments demonstrate that AMNAR achieves state-of-the-art performance, highlighting the effectiveness of AMNAR and the importance of modeling multiple valid next actions in error detection. The code is available at https://github.com/iSEE-Laboratory/AMNAR.
ChainHOI: Joint-based Kinematic Chain Modeling for Human-Object Interaction Generation
Mar 17, 2025



We propose ChainHOI, a novel approach for text-driven human-object interaction (HOI) generation that explicitly models interactions at both the joint and kinetic chain levels. Unlike existing methods that implicitly model interactions using full-body poses as tokens, we argue that explicitly modeling joint-level interactions is more natural and effective for generating realistic HOIs, as it directly captures the geometric and semantic relationships between joints, rather than modeling interactions in the latent pose space. To this end, ChainHOI introduces a novel joint graph to capture potential interactions with objects, and a Generative Spatiotemporal Graph Convolution Network to explicitly model interactions at the joint level. Furthermore, we propose a Kinematics-based Interaction Module that explicitly models interactions at the kinetic chain level, ensuring more realistic and biomechanically coherent motions. Evaluations on two public datasets demonstrate that ChainHOI significantly outperforms previous methods, generating more realistic, and semantically consistent HOIs. Code is available \href{https://github.com/qinghuannn/ChainHOI}{here}.
iManip: Skill-Incremental Learning for Robotic Manipulation
Mar 10, 2025The development of a generalist agent with adaptive multiple manipulation skills has been a long-standing goal in the robotics community. In this paper, we explore a crucial task, skill-incremental learning, in robotic manipulation, which is to endow the robots with the ability to learn new manipulation skills based on the previous learned knowledge without re-training. First, we build a skill-incremental environment based on the RLBench benchmark, and explore how traditional incremental methods perform in this setting. We find that they suffer from severe catastrophic forgetting due to the previous methods on classification overlooking the characteristics of temporality and action complexity in robotic manipulation tasks. Towards this end, we propose an incremental Manip}ulation framework, termed iManip, to mitigate the above issues. We firstly design a temporal replay strategy to maintain the integrity of old skills when learning new skill. Moreover, we propose the extendable PerceiverIO, consisting of an action prompt with extendable weight to adapt to new action primitives in new skill. Extensive experiments show that our framework performs well in Skill-Incremental Learning. Codes of the skill-incremental environment with our framework will be open-source.
MaintaAvatar: A Maintainable Avatar Based on Neural Radiance Fields by Continual Learning
Feb 04, 2025



The generation of a virtual digital avatar is a crucial research topic in the field of computer vision. Many existing works utilize Neural Radiance Fields (NeRF) to address this issue and have achieved impressive results. However, previous works assume the images of the training person are available and fixed while the appearances and poses of a subject could constantly change and increase in real-world scenarios. How to update the human avatar but also maintain the ability to render the old appearance of the person is a practical challenge. One trivial solution is to combine the existing virtual avatar models based on NeRF with continual learning methods. However, there are some critical issues in this approach: learning new appearances and poses can cause the model to forget past information, which in turn leads to a degradation in the rendering quality of past appearances, especially color bleeding issues, and incorrect human body poses. In this work, we propose a maintainable avatar (MaintaAvatar) based on neural radiance fields by continual learning, which resolves the issues by utilizing a Global-Local Joint Storage Module and a Pose Distillation Module. Overall, our model requires only limited data collection to quickly fine-tune the model while avoiding catastrophic forgetting, thus achieving a maintainable virtual avatar. The experimental results validate the effectiveness of our MaintaAvatar model.
TechCoach: Towards Technical Keypoint-Aware Descriptive Action Coaching
Nov 26, 2024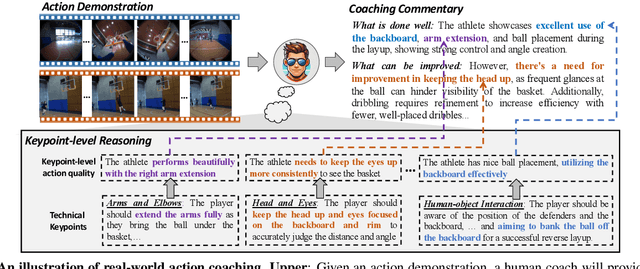
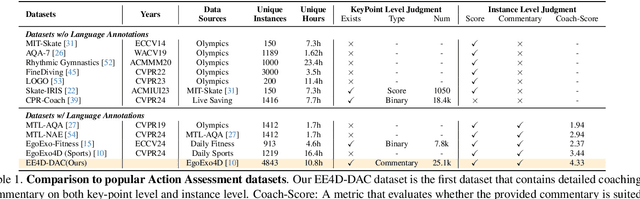
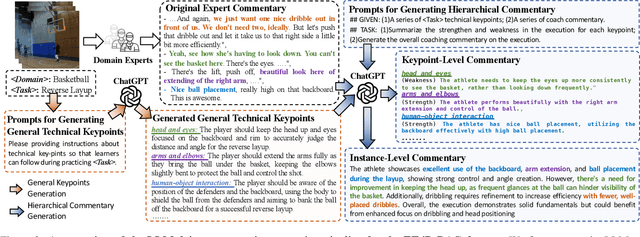

To guide a learner to master the action skills, it is crucial for a coach to 1) reason through the learner's action execution and technical keypoints, and 2) provide detailed, understandable feedback on what is done well and what can be improved. However, existing score-based action assessment methods are still far from this practical scenario. To bridge this gap, we investigate a new task termed Descriptive Action Coaching (DAC) which requires a model to provide detailed commentary on what is done well and what can be improved beyond a quality score from an action execution. To this end, we construct a new dataset named EE4D-DAC. With an LLM-based annotation pipeline, our dataset goes beyond the existing action assessment datasets by providing the hierarchical coaching commentary at both keypoint and instance levels. Furthermore, we propose TechCoach, a new framework that explicitly incorporates keypoint-level reasoning into the DAC process. The central to our method lies in the Context-aware Keypoint Reasoner, which enables TechCoach to learn keypoint-related quality representations by querying visual context under the supervision of keypoint-level coaching commentary. Prompted by the visual context and the keypoint-related quality representations, a unified Keypoint-aware Action Assessor is then employed to provide the overall coaching commentary together with the quality score. Combining all of these, we build a new benchmark for DAC and evaluate the effectiveness of our method through extensive experiments. Data and code will be publicly available.
When Prompt-based Incremental Learning Does Not Meet Strong Pretraining
Aug 21, 2023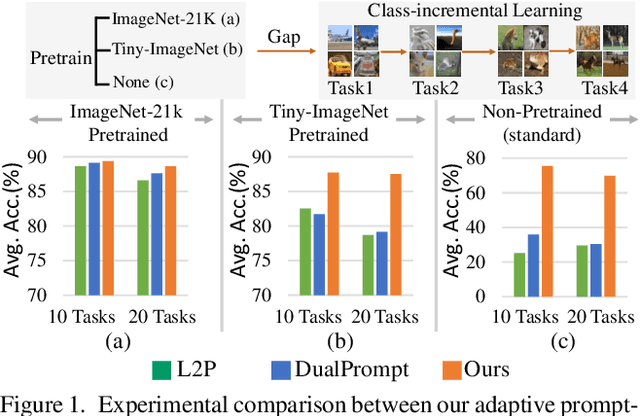

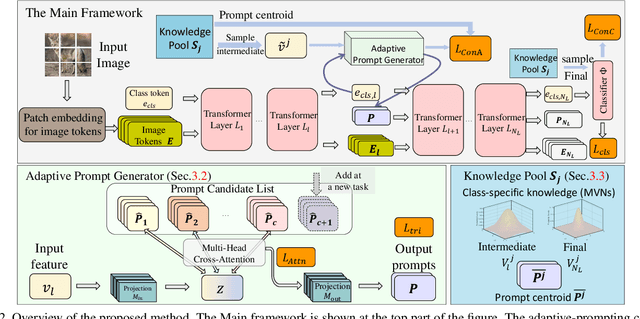
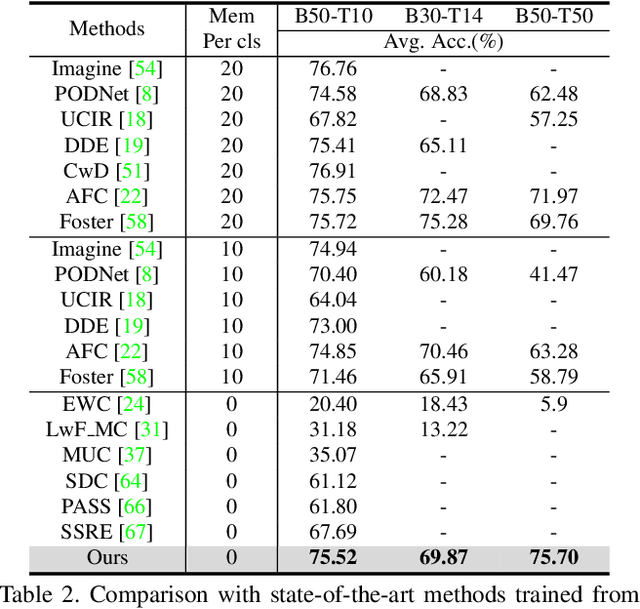
Incremental learning aims to overcome catastrophic forgetting when learning deep networks from sequential tasks. With impressive learning efficiency and performance, prompt-based methods adopt a fixed backbone to sequential tasks by learning task-specific prompts. However, existing prompt-based methods heavily rely on strong pretraining (typically trained on ImageNet-21k), and we find that their models could be trapped if the potential gap between the pretraining task and unknown future tasks is large. In this work, we develop a learnable Adaptive Prompt Generator (APG). The key is to unify the prompt retrieval and prompt learning processes into a learnable prompt generator. Hence, the whole prompting process can be optimized to reduce the negative effects of the gap between tasks effectively. To make our APG avoid learning ineffective knowledge, we maintain a knowledge pool to regularize APG with the feature distribution of each class. Extensive experiments show that our method significantly outperforms advanced methods in exemplar-free incremental learning without (strong) pretraining. Besides, under strong retraining, our method also has comparable performance to existing prompt-based models, showing that our method can still benefit from pretraining. Codes can be found at https://github.com/TOM-tym/APG
DilateFormer: Multi-Scale Dilated Transformer for Visual Recognition
Feb 03, 2023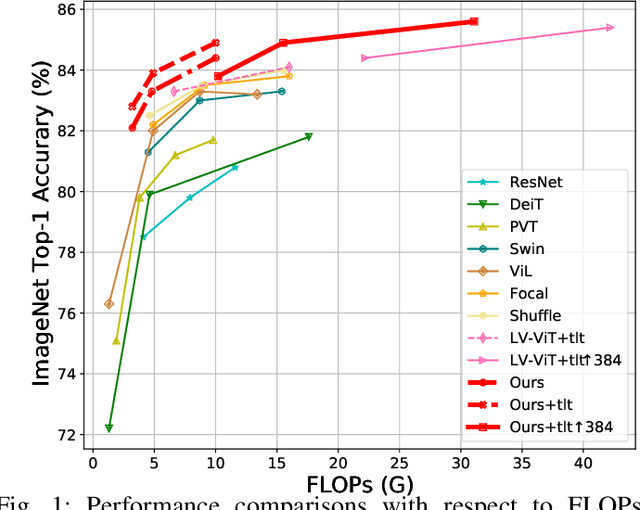

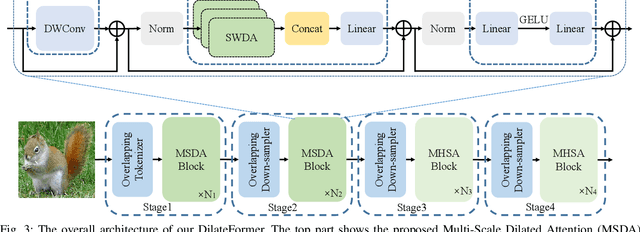
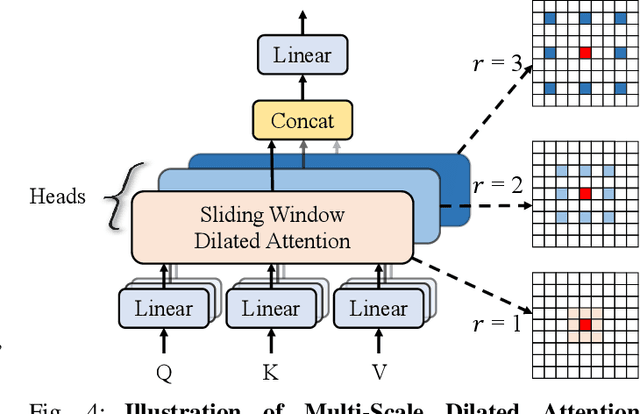
As a de facto solution, the vanilla Vision Transformers (ViTs) are encouraged to model long-range dependencies between arbitrary image patches while the global attended receptive field leads to quadratic computational cost. Another branch of Vision Transformers exploits local attention inspired by CNNs, which only models the interactions between patches in small neighborhoods. Although such a solution reduces the computational cost, it naturally suffers from small attended receptive fields, which may limit the performance. In this work, we explore effective Vision Transformers to pursue a preferable trade-off between the computational complexity and size of the attended receptive field. By analyzing the patch interaction of global attention in ViTs, we observe two key properties in the shallow layers, namely locality and sparsity, indicating the redundancy of global dependency modeling in shallow layers of ViTs. Accordingly, we propose Multi-Scale Dilated Attention (MSDA) to model local and sparse patch interaction within the sliding window. With a pyramid architecture, we construct a Multi-Scale Dilated Transformer (DilateFormer) by stacking MSDA blocks at low-level stages and global multi-head self-attention blocks at high-level stages. Our experiment results show that our DilateFormer achieves state-of-the-art performance on various vision tasks. On ImageNet-1K classification task, DilateFormer achieves comparable performance with 70% fewer FLOPs compared with existing state-of-the-art models. Our DilateFormer-Base achieves 85.6% top-1 accuracy on ImageNet-1K classification task, 53.5% box mAP/46.1% mask mAP on COCO object detection/instance segmentation task and 51.1% MS mIoU on ADE20K semantic segmentation task.
Learning to Imagine: Diversify Memory for Incremental Learning using Unlabeled Data
Apr 19, 2022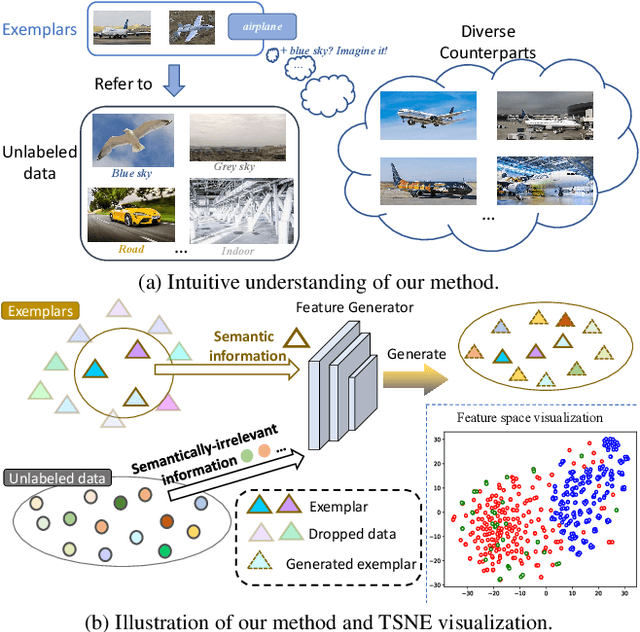
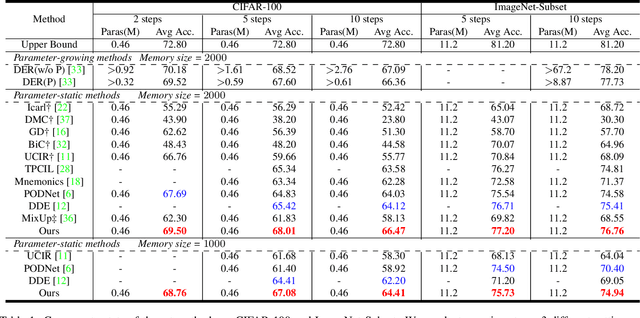
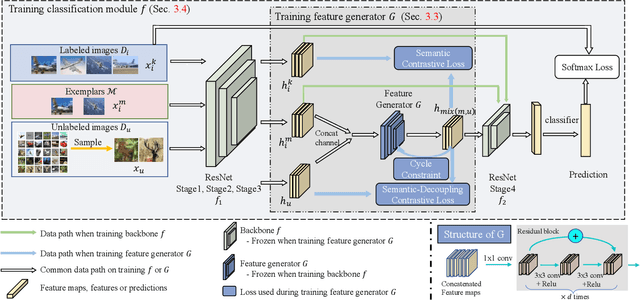
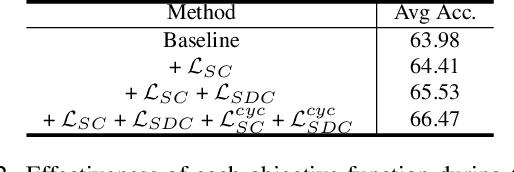
Deep neural network (DNN) suffers from catastrophic forgetting when learning incrementally, which greatly limits its applications. Although maintaining a handful of samples (called `exemplars`) of each task could alleviate forgetting to some extent, existing methods are still limited by the small number of exemplars since these exemplars are too few to carry enough task-specific knowledge, and therefore the forgetting remains. To overcome this problem, we propose to `imagine` diverse counterparts of given exemplars referring to the abundant semantic-irrelevant information from unlabeled data. Specifically, we develop a learnable feature generator to diversify exemplars by adaptively generating diverse counterparts of exemplars based on semantic information from exemplars and semantically-irrelevant information from unlabeled data. We introduce semantic contrastive learning to enforce the generated samples to be semantic consistent with exemplars and perform semanticdecoupling contrastive learning to encourage diversity of generated samples. The diverse generated samples could effectively prevent DNN from forgetting when learning new tasks. Our method does not bring any extra inference cost and outperforms state-of-the-art methods on two benchmarks CIFAR-100 and ImageNet-Subset by a clear margin.