 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Whole-Body Human-Humanoid Interaction from Human-Human Demonstrations
Jan 14, 2026Enabling humanoid robots to physically interact with humans is a critical frontier, but progress is hindered by the scarcity of high-quality Human-Humanoid Interaction (HHoI) data. While leveraging abundant Human-Human Interaction (HHI) data presents a scalable alternative, we first demonstrate that standard retargeting fails by breaking the essential contacts. We address this with PAIR (Physics-Aware Interaction Retargeting), a contact-centric, two-stage pipeline that preserves contact semantics across morphology differences to generate physically consistent HHoI data. This high-quality data, however, exposes a second failure: conventional imitation learning policies merely mimic trajectories and lack interactive understanding. We therefore introduce D-STAR (Decoupled Spatio-Temporal Action Reasoner), a hierarchical policy that disentangles when to act from where to act. In D-STAR, Phase Attention (when) and a Multi-Scale Spatial module (where) are fused by the diffusion head to produce synchronized whole-body behaviors beyond mimicry. By decoupling these reasoning streams, our model learns robust temporal phases without being distracted by spatial noise, leading to responsive, synchronized collaboration. We validate our framework through extensive and rigorous simulations, demonstrating significant performance gains over baseline approaches and a complete, effective pipeline for learning complex whole-body interactions from HHI data.
ZeroDexGrasp: Zero-Shot Task-Oriented Dexterous Grasp Synthesis with Prompt-Based Multi-Stage Semantic Reasoning
Nov 17, 2025Task-oriented dexterous grasping holds broad application prospects in robotic manipulation and human-object interaction. However, most existing methods still struggle to generalize across diverse objects and task instructions, as they heavily rely on costly labeled data to ensure task-specific semantic alignment. In this study, we propose \textbf{ZeroDexGrasp}, a zero-shot task-oriented dexterous grasp synthesis framework integrating Multimodal Large Language Models with grasp refinement to generate human-like grasp poses that are well aligned with specific task objectives and object affordances. Specifically, ZeroDexGrasp employs prompt-based multi-stage semantic reasoning to infer initial grasp configurations and object contact information from task and object semantics, then exploits contact-guided grasp optimization to refine these poses for physical feasibility and task alignment. Experimental results demonstrate that ZeroDexGrasp enables high-quality zero-shot dexterous grasping on diverse unseen object categories and complex task requirements, advancing toward more generalizable and intelligent robotic grasping.
OmniDexGrasp: Generalizable Dexterous Grasping via Foundation Model and Force Feedback
Oct 27, 2025



Enabling robots to dexterously grasp and manipulate objects based on human commands is a promising direction in robotics. However, existing approaches are challenging to generalize across diverse objects or tasks due to the limited scale of semantic dexterous grasp datasets. Foundation models offer a new way to enhance generalization, yet directly leveraging them to generate feasible robotic actions remains challenging due to the gap between abstract model knowledge and physical robot execution. To address these challenges, we propose OmniDexGrasp, a generalizable framework that achieves omni-capabilities in user prompting, dexterous embodiment, and grasping tasks by combining foundation models with the transfer and control strategies. OmniDexGrasp integrates three key modules: (i) foundation models are used to enhance generalization by generating human grasp images supporting omni-capability of user prompt and task; (ii) a human-image-to-robot-action transfer strategy converts human demonstrations into executable robot actions, enabling omni dexterous embodiment; (iii) force-aware adaptive grasp strategy ensures robust and stable grasp execution. Experiments in simulation and on real robots validate the effectiveness of OmniDexGrasp on diverse user prompts, grasp task and dexterous hands, and further results show its extensibility to dexterous manipulation tasks.
TypeTele: Releasing Dexterity in Teleoperation by Dexterous Manipulation Types
Jul 02, 2025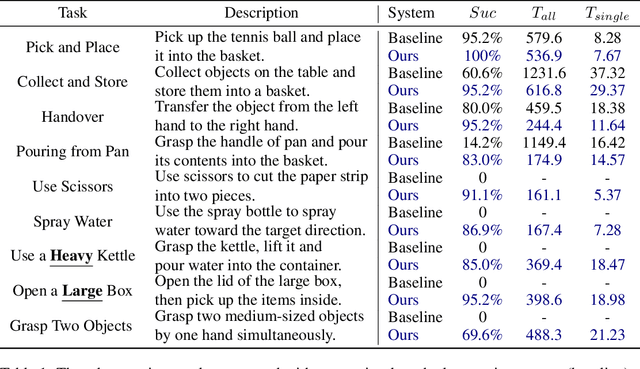


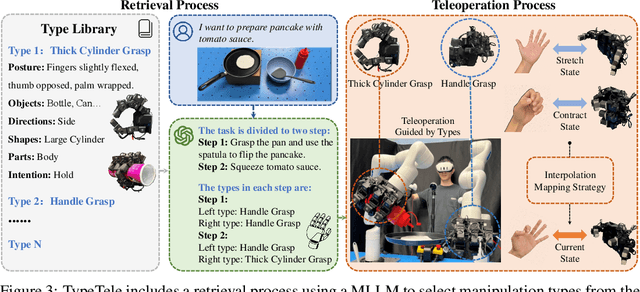
Dexterous teleoperation plays a crucial role in robotic manipulation for real-world data collection and remote robot control. Previous dexterous teleoperation mostly relies on hand retargeting to closely mimic human hand postures. However, these approaches may fail to fully leverage the inherent dexterity of dexterous hands, which can execute unique actions through their structural advantages compared to human hands. To address this limitation, we propose TypeTele, a type-guided dexterous teleoperation system, which enables dexterous hands to perform actions that are not constrained by human motion patterns. This is achieved by introducing dexterous manipulation types into the teleoperation system, allowing operators to employ appropriate types to complete specific tasks. To support this system, we build an extensible dexterous manipulation type library to cover comprehensive dexterous postures used in manipulation tasks. During teleoperation, we employ a MLLM (Multi-modality Large Language Model)-assisted type retrieval module to identify the most suitable manipulation type based on the specific task and operator commands. Extensive experiments of real-world teleoperation and imitation learning demonstrate that the incorporation of manipulation types significantly takes full advantage of the dexterous robot's ability to perform diverse and complex tasks with higher success rates.
ChainHOI: Joint-based Kinematic Chain Modeling for Human-Object Interaction Generation
Mar 17, 2025



We propose ChainHOI, a novel approach for text-driven human-object interaction (HOI) generation that explicitly models interactions at both the joint and kinetic chain levels. Unlike existing methods that implicitly model interactions using full-body poses as tokens, we argue that explicitly modeling joint-level interactions is more natural and effective for generating realistic HOIs, as it directly captures the geometric and semantic relationships between joints, rather than modeling interactions in the latent pose space. To this end, ChainHOI introduces a novel joint graph to capture potential interactions with objects, and a Generative Spatiotemporal Graph Convolution Network to explicitly model interactions at the joint level. Furthermore, we propose a Kinematics-based Interaction Module that explicitly models interactions at the kinetic chain level, ensuring more realistic and biomechanically coherent motions. Evaluations on two public datasets demonstrate that ChainHOI significantly outperforms previous methods, generating more realistic, and semantically consistent HOIs. Code is available \href{https://github.com/qinghuannn/ChainHOI}{here}.
Rethinking Bimanual Robotic Manipulation: Learning with Decoupled Interaction Framework
Mar 12, 2025Bimanual robotic manipulation is an emerging and critical topic in the robotics community. Previous works primarily rely on integrated control models that take the perceptions and states of both arms as inputs to directly predict their actions. However, we think bimanual manipulation involves not only coordinated tasks but also various uncoordinated tasks that do not require explicit cooperation during execution, such as grasping objects with the closest hand, which integrated control frameworks ignore to consider due to their enforced cooperation in the early inputs. In this paper, we propose a novel decoupled interaction framework that considers the characteristics of different tasks in bimanual manipulation. The key insight of our framework is to assign an independent model to each arm to enhance the learning of uncoordinated tasks, while introducing a selective interaction module that adaptively learns weights from its own arm to improve the learning of coordinated tasks. Extensive experiments on seven tasks in the RoboTwin dataset demonstrate that: (1) Our framework achieves outstanding performance, with a 23.5% boost over the SOTA method. (2) Our framework is flexible and can be seamlessly integrated into existing methods. (3) Our framework can be effectively extended to multi-agent manipulation tasks, achieving a 28% boost over the integrated control SOTA. (4) The performance boost stems from the decoupled design itself, surpassing the SOTA by 16.5% in success rate with only 1/6 of the model size.
AffordDexGrasp: Open-set Language-guided Dexterous Grasp with Generalizable-Instructive Affordance
Mar 10, 2025Language-guided robot dexterous generation enables robots to grasp and manipulate objects based on human commands. However, previous data-driven methods are hard to understand intention and execute grasping with unseen categories in the open set. In this work, we explore a new task, Open-set Language-guided Dexterous Grasp, and find that the main challenge is the huge gap between high-level human language semantics and low-level robot actions. To solve this problem, we propose an Affordance Dexterous Grasp (AffordDexGrasp) framework, with the insight of bridging the gap with a new generalizable-instructive affordance representation. This affordance can generalize to unseen categories by leveraging the object's local structure and category-agnostic semantic attributes, thereby effectively guiding dexterous grasp generation. Built upon the affordance, our framework introduces Affordacne Flow Matching (AFM) for affordance generation with language as input, and Grasp Flow Matching (GFM) for generating dexterous grasp with affordance as input. To evaluate our framework, we build an open-set table-top language-guided dexterous grasp dataset. Extensive experiments in the simulation and real worlds show that our framework surpasses all previous methods in open-set generalization.
iManip: Skill-Incremental Learning for Robotic Manipulation
Mar 10, 2025The development of a generalist agent with adaptive multiple manipulation skills has been a long-standing goal in the robotics community. In this paper, we explore a crucial task, skill-incremental learning, in robotic manipulation, which is to endow the robots with the ability to learn new manipulation skills based on the previous learned knowledge without re-training. First, we build a skill-incremental environment based on the RLBench benchmark, and explore how traditional incremental methods perform in this setting. We find that they suffer from severe catastrophic forgetting due to the previous methods on classification overlooking the characteristics of temporality and action complexity in robotic manipulation tasks. Towards this end, we propose an incremental Manip}ulation framework, termed iManip, to mitigate the above issues. We firstly design a temporal replay strategy to maintain the integrity of old skills when learning new skill. Moreover, we propose the extendable PerceiverIO, consisting of an action prompt with extendable weight to adapt to new action primitives in new skill. Extensive experiments show that our framework performs well in Skill-Incremental Learning. Codes of the skill-incremental environment with our framework will be open-source.
TacCap: A Wearable FBG-Based Tactile Sensor for Seamless Human-to-Robot Skill Transfer
Mar 03, 2025Tactile sensing is essential for dexterous manipulation, yet large-scale human demonstration datasets lack tactile feedback, limiting their effectiveness in skill transfer to robots. To address this, we introduce TacCap, a wearable Fiber Bragg Grating (FBG)-based tactile sensor designed for seamless human-to-robot transfer. TacCap is lightweight, durable, and immune to electromagnetic interference, making it ideal for real-world data collection. We detail its design and fabrication, evaluate its sensitivity, repeatability, and cross-sensor consistency, and assess its effectiveness through grasp stability prediction and ablation studies. Our results demonstrate that TacCap enables transferable tactile data collection, bridging the gap between human demonstrations and robotic execution. To support further research and development, we open-source our hardware design and software.
Real-to-Sim Grasp: Rethinking the Gap between Simulation and Real World in Grasp Detection
Oct 09, 2024



For 6-DoF grasp detection, simulated data is expandable to train more powerful model, but it faces the challenge of the large gap between simulation and real world. Previous works bridge this gap with a sim-to-real way. However, this way explicitly or implicitly forces the simulated data to adapt to the noisy real data when training grasp detectors, where the positional drift and structural distortion within the camera noise will harm the grasp learning. In this work, we propose a Real-to-Sim framework for 6-DoF Grasp detection, named R2SGrasp, with the key insight of bridging this gap in a real-to-sim way, which directly bypasses the camera noise in grasp detector training through an inference-time real-to-sim adaption. To achieve this real-to-sim adaptation, our R2SGrasp designs the Real-to-Sim Data Repairer (R2SRepairer) to mitigate the camera noise of real depth maps in data-level, and the Real-to-Sim Feature Enhancer (R2SEnhancer) to enhance real features with precise simulated geometric primitives in feature-level. To endow our framework with the generalization ability, we construct a large-scale simulated dataset cost-efficiently to train our grasp detector, which includes 64,000 RGB-D images with 14.4 million grasp annotations. Sufficient experiments show that R2SGrasp is powerful and our real-to-sim perspective is effective. The real-world experiments further show great generalization ability of R2SGrasp. Project page is available on https://isee-laboratory.github.io/R2SGrasp.