 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-View Scene Point Cloud Human Grasp Generation
Paper and Code
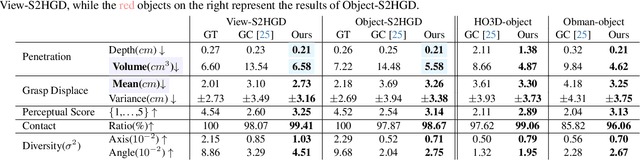
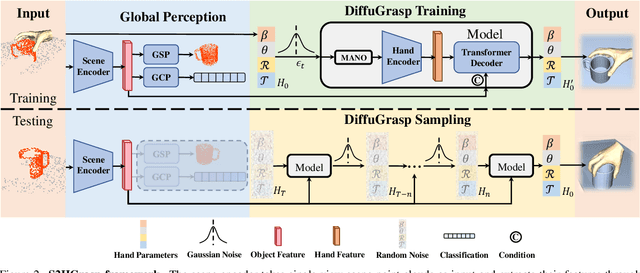

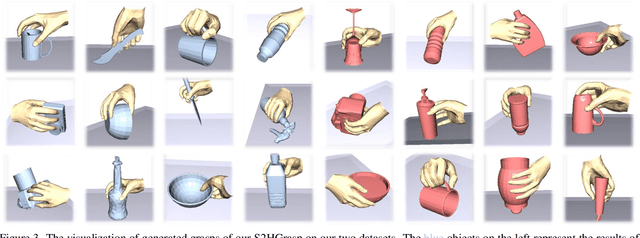
In this work, we explore a novel task of generating human grasps based on single-view scene point clouds, which more accurately mirrors the typical real-world situation of observing objects from a single viewpoint. Due to the incompleteness of object point clouds and the presence of numerous scene points, the generated hand is prone to penetrating into the invisible parts of the object and the model is easily affected by scene points. Thus, we introduce S2HGrasp, a framework composed of two key modules: the Global Perception module that globally perceives partial object point clouds, and the DiffuGrasp module designed to generate high-quality human grasps based on complex inputs that include scene points. Additionally, we introduce S2HGD dataset, which comprises approximately 99,000 single-object single-view scene point clouds of 1,668 unique objects, each annotated with one human grasp. Our extensive experiments demonstrate that S2HGrasp can not only generate natural human grasps regardless of scene points, but also effectively prevent penetration between the hand and invisible parts of the object. Moreover, our model showcases strong generalization capability when applied to unseen objects. Our code and dataset are available at https://github.com/iSEE-Laboratory/S2HGrasp.