 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTypeTele: Releasing Dexterity in Teleoperation by Dexterous Manipulation Types
Jul 02, 2025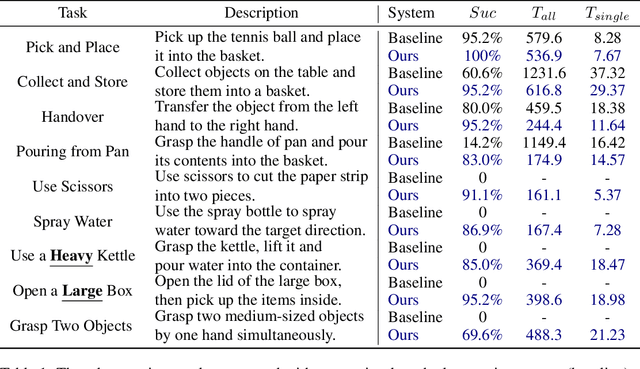


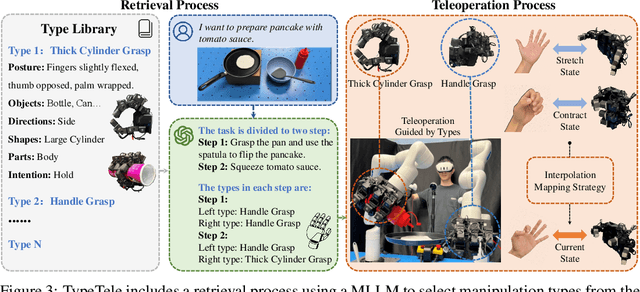
Dexterous teleoperation plays a crucial role in robotic manipulation for real-world data collection and remote robot control. Previous dexterous teleoperation mostly relies on hand retargeting to closely mimic human hand postures. However, these approaches may fail to fully leverage the inherent dexterity of dexterous hands, which can execute unique actions through their structural advantages compared to human hands. To address this limitation, we propose TypeTele, a type-guided dexterous teleoperation system, which enables dexterous hands to perform actions that are not constrained by human motion patterns. This is achieved by introducing dexterous manipulation types into the teleoperation system, allowing operators to employ appropriate types to complete specific tasks. To support this system, we build an extensible dexterous manipulation type library to cover comprehensive dexterous postures used in manipulation tasks. During teleoperation, we employ a MLLM (Multi-modality Large Language Model)-assisted type retrieval module to identify the most suitable manipulation type based on the specific task and operator commands. Extensive experiments of real-world teleoperation and imitation learning demonstrate that the incorporation of manipulation types significantly takes full advantage of the dexterous robot's ability to perform diverse and complex tasks with higher success rates.
TacCap: A Wearable FBG-Based Tactile Sensor for Seamless Human-to-Robot Skill Transfer
Mar 03, 2025Tactile sensing is essential for dexterous manipulation, yet large-scale human demonstration datasets lack tactile feedback, limiting their effectiveness in skill transfer to robots. To address this, we introduce TacCap, a wearable Fiber Bragg Grating (FBG)-based tactile sensor designed for seamless human-to-robot transfer. TacCap is lightweight, durable, and immune to electromagnetic interference, making it ideal for real-world data collection. We detail its design and fabrication, evaluate its sensitivity, repeatability, and cross-sensor consistency, and assess its effectiveness through grasp stability prediction and ablation studies. Our results demonstrate that TacCap enables transferable tactile data collection, bridging the gap between human demonstrations and robotic execution. To support further research and development, we open-source our hardware design and software.
Whisker-Inspired Tactile Sensing: A Sim2Real Approach for Precise Underwater Contact Tracking
Oct 17, 2024



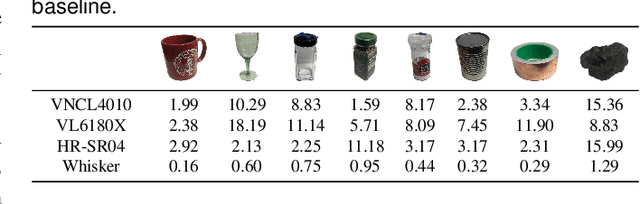
Aquatic mammals, such as pinnipeds, utilize their whiskers to detect and discriminate objects and analyze water movements, inspiring the development of robotic whiskers for sensing contacts, surfaces, and water flows. We present the design and application of underwater whisker sensors based on Fiber Bragg Grating (FBG) technology. These passive whiskers are mounted along the robot$'$s exterior to sense its surroundings through light, non-intrusive contacts. For contact tracking, we employ a sim-to-real learning framework, which involves extensive data collection in simulation followed by a sim-to-real calibration process to transfer the model trained in simulation to the real world. Experiments with whiskers immersed in water indicate that our approach can track contact points with an accuracy of $<2$ mm, without requiring precise robot proprioception. We demonstrate that the approach also generalizes to unseen objects.
Navigation and 3D Surface Reconstruction from Passive Whisker Sensing
Jun 10, 2024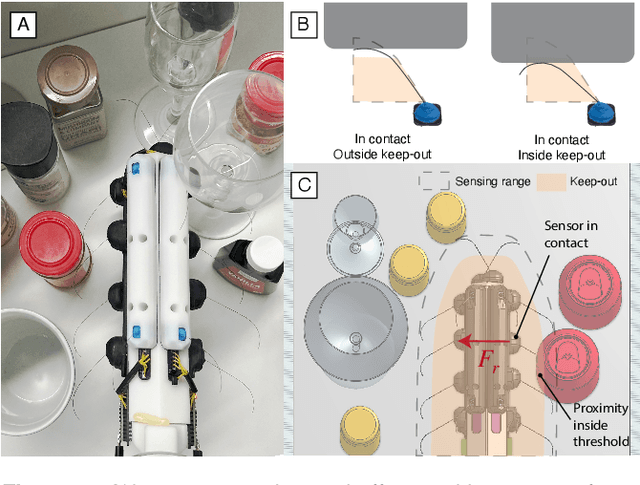
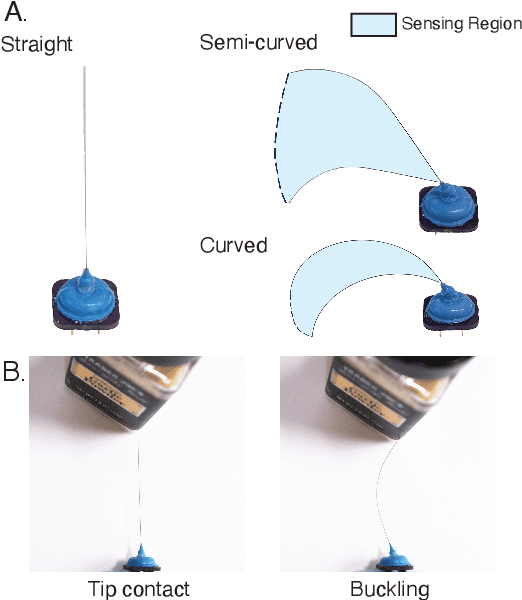
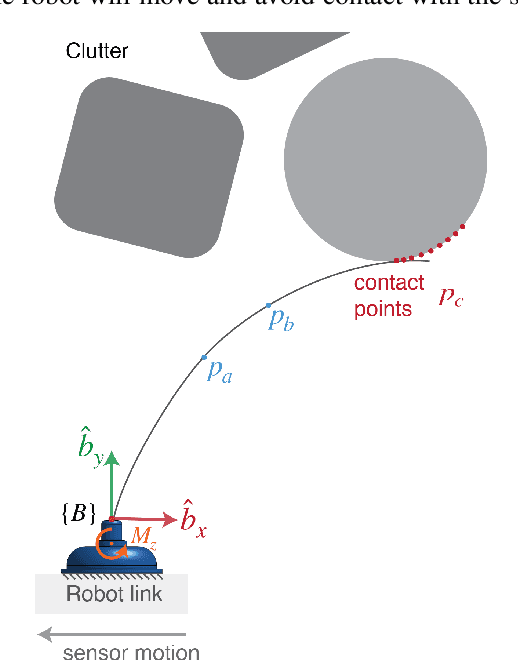
Whiskers provide a way to sense surfaces in the immediate environment without disturbing it. In this paper we present a method for using highly flexible, curved, passive whiskers mounted along a robot arm to gather sensory data as they brush past objects during normal robot motion. The information is useful both for guiding the robot in cluttered spaces and for reconstructing the exposed faces of objects. Surface reconstruction depends on accurate localization of contact points along each whisker. We present an algorithm based on Bayesian filtering that rapidly converges to within 1\,mm of the actual contact locations. The piecewise-continuous history of contact locations from each whisker allows for accurate reconstruction of curves on object surfaces. Employing multiple whiskers and traces, we are able to produce an occupancy map of proximal objects.
Grasp as You Say: Language-guided Dexterous Grasp Generation
May 29, 2024



This paper explores a novel task ""Dexterous Grasp as You Say"" (DexGYS), enabling robots to perform dexterous grasping based on human commands expressed in natural language. However, the development of this field is hindered by the lack of datasets with natural human guidance; thus, we propose a language-guided dexterous grasp dataset, named DexGYSNet, offering high-quality dexterous grasp annotations along with flexible and fine-grained human language guidance. Our dataset construction is cost-efficient, with the carefully-design hand-object interaction retargeting strategy, and the LLM-assisted language guidance annotation system. Equipped with this dataset, we introduce the DexGYSGrasp framework for generating dexterous grasps based on human language instructions, with the capability of producing grasps that are intent-aligned, high quality and diversity. To achieve this capability, our framework decomposes the complex learning process into two manageable progressive objectives and introduce two components to realize them. The first component learns the grasp distribution focusing on intention alignment and generation diversity. And the second component refines the grasp quality while maintaining intention consistency. Extensive experiments are conducted on DexGYSNet and real world environment for validation.
Single-View Scene Point Cloud Human Grasp Generation
Apr 24, 2024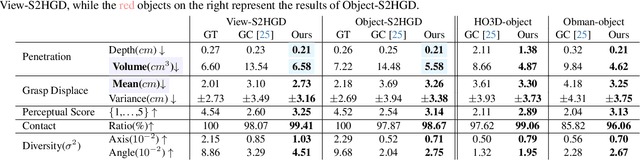
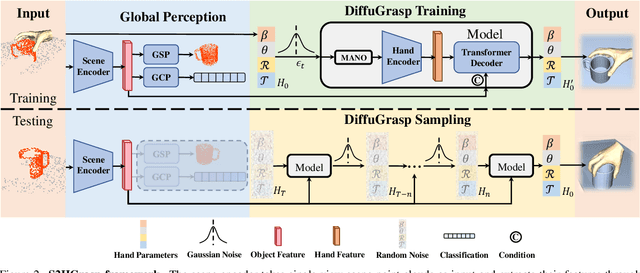

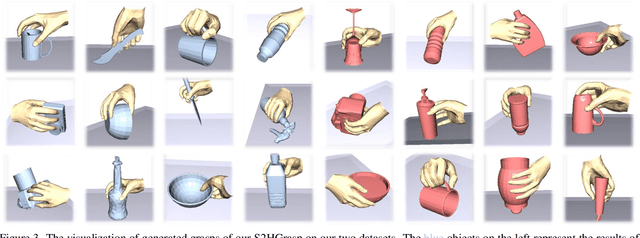
In this work, we explore a novel task of generating human grasps based on single-view scene point clouds, which more accurately mirrors the typical real-world situation of observing objects from a single viewpoint. Due to the incompleteness of object point clouds and the presence of numerous scene points, the generated hand is prone to penetrating into the invisible parts of the object and the model is easily affected by scene points. Thus, we introduce S2HGrasp, a framework composed of two key modules: the Global Perception module that globally perceives partial object point clouds, and the DiffuGrasp module designed to generate high-quality human grasps based on complex inputs that include scene points. Additionally, we introduce S2HGD dataset, which comprises approximately 99,000 single-object single-view scene point clouds of 1,668 unique objects, each annotated with one human grasp. Our extensive experiments demonstrate that S2HGrasp can not only generate natural human grasps regardless of scene points, but also effectively prevent penetration between the hand and invisible parts of the object. Moreover, our model showcases strong generalization capability when applied to unseen objects. Our code and dataset are available at https://github.com/iSEE-Laboratory/S2HGrasp.
MuseCoco: Generating Symbolic Music from Text
May 31, 2023



Generating music from text descriptions is a user-friendly mode since the text is a relatively easy interface for user engagement. While some approaches utilize texts to control music audio generation, editing musical elements in generated audio is challenging for users. In contrast, symbolic music offers ease of editing, making it more accessible for users to manipulate specific musical elements. In this paper, we propose MuseCoco, which generates symbolic music from text descriptions with musical attributes as the bridge to break down the task into text-to-attribute understanding and attribute-to-music generation stages. MuseCoCo stands for Music Composition Copilot that empowers musicians to generate music directly from given text descriptions, offering a significant improvement in efficiency compared to creating music entirely from scratch. The system has two main advantages: Firstly, it is data efficient. In the attribute-to-music generation stage, the attributes can be directly extracted from music sequences, making the model training self-supervised. In the text-to-attribute understanding stage, the text is synthesized and refined by ChatGPT based on the defined attribute templates. Secondly, the system can achieve precise control with specific attributes in text descriptions and offers multiple control options through attribute-conditioned or text-conditioned approaches. MuseCoco outperforms baseline systems in terms of musicality, controllability, and overall score by at least 1.27, 1.08, and 1.32 respectively. Besides, there is a notable enhancement of about 20% in objective control accuracy. In addition, we have developed a robust large-scale model with 1.2 billion parameters, showcasing exceptional controllability and musicality.