 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Generative Recommendation via Simple Categorical User Sequence Compression
Jan 27, 2026Although generative recommenders demonstrate improved performance with longer sequences, their real-time deployment is hindered by substantial computational costs. To address this challenge, we propose a simple yet effective method for compressing long-term user histories by leveraging inherent item categorical features, thereby preserving user interests while enhancing efficiency. Experiments on two large-scale datasets demonstrate that, compared to the influential HSTU model, our approach achieves up to a 6x reduction in computational cost and up to 39% higher accuracy at comparable cost (i.e., similar sequence length).
FOREVER: Forgetting Curve-Inspired Memory Replay for Language Model Continual Learning
Jan 07, 2026Continual learning (CL) for large language models (LLMs) aims to enable sequential knowledge acquisition without catastrophic forgetting. Memory replay methods are widely used for their practicality and effectiveness, but most rely on fixed, step-based heuristics that often misalign with the model's actual learning progress, since identical training steps can result in varying degrees of parameter change. Motivated by recent findings that LLM forgetting mirrors the Ebbinghaus human forgetting curve, we propose FOREVER (FORgEtting curVe-inspired mEmory Replay), a novel CL framework that aligns replay schedules with a model-centric notion of time. FOREVER defines model time using the magnitude of optimizer updates, allowing forgetting curve-inspired replay intervals to align with the model's internal evolution rather than raw training steps. Building on this approach, FOREVER incorporates a forgetting curve-based replay scheduler to determine when to replay and an intensity-aware regularization mechanism to adaptively control how to replay. Extensive experiments on three CL benchmarks and models ranging from 0.6B to 13B parameters demonstrate that FOREVER consistently mitigates catastrophic forgetting.
Judging with Personality and Confidence: A Study on Personality-Conditioned LLM Relevance Assessment
Jan 05, 2026Recent studies have shown that prompting can enable large language models (LLMs) to simulate specific personality traits and produce behaviors that align with those traits. However, there is limited understanding of how these simulated personalities influence critical web search decisions, specifically relevance assessment. Moreover, few studies have examined how simulated personalities impact confidence calibration, specifically the tendencies toward overconfidence or underconfidence. This gap exists even though psychological literature suggests these biases are trait-specific, often linking high extraversion to overconfidence and high neuroticism to underconfidence. To address this gap, we conducted a comprehensive study evaluating multiple LLMs, including commercial models and open-source models, prompted to simulate Big Five personality traits. We tested these models across three test collections (TREC DL 2019, TREC DL 2020, and LLMJudge), collecting two key outputs for each query-document pair: a relevance judgment and a self-reported confidence score. The findings show that personalities such as low agreeableness consistently align more closely with human labels than the unprompted condition. Additionally, low conscientiousness performs well in balancing the suppression of both overconfidence and underconfidence. We also observe that relevance scores and confidence distributions vary systematically across different personalities. Based on the above findings, we incorporate personality-conditioned scores and confidence as features in a random forest classifier. This approach achieves performance that surpasses the best single-personality condition on a new dataset (TREC DL 2021), even with limited training data. These findings highlight that personality-derived confidence offers a complementary predictive signal, paving the way for more reliable and human-aligned LLM evaluators.
ProEdit: Inversion-based Editing From Prompts Done Right
Dec 26, 2025


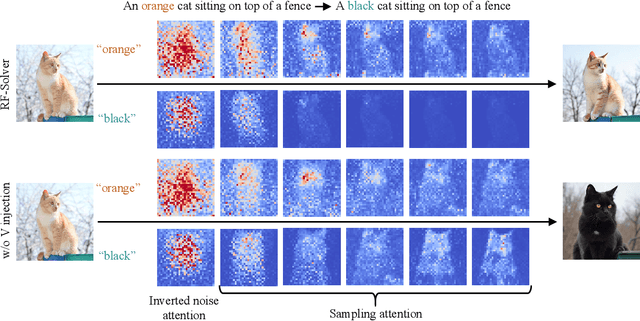
Inversion-based visual editing provides an effective and training-free way to edit an image or a video based on user instructions. Existing methods typically inject source image information during the sampling process to maintain editing consistency. However, this sampling strategy overly relies on source information, which negatively affects the edits in the target image (e.g., failing to change the subject's atributes like pose, number, or color as instructed). In this work, we propose ProEdit to address this issue both in the attention and the latent aspects. In the attention aspect, we introduce KV-mix, which mixes KV features of the source and the target in the edited region, mitigating the influence of the source image on the editing region while maintaining background consistency. In the latent aspect, we propose Latents-Shift, which perturbs the edited region of the source latent, eliminating the influence of the inverted latent on the sampling. Extensive experiments on several image and video editing benchmarks demonstrate that our method achieves SOTA performance. In addition, our design is plug-and-play, which can be seamlessly integrated into existing inversion and editing methods, such as RF-Solver, FireFlow and UniEdit.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
DEAL: Disentangling Transformer Head Activations for LLM Steering
Jun 10, 2025Inference-time steering aims to alter the response characteristics of large language models (LLMs) without modifying their underlying parameters. A critical step in this process is the identification of internal modules within LLMs that are associated with the target behavior. However, current approaches to module selection often depend on superficial cues or ad-hoc heuristics, which can result in suboptimal or unintended outcomes. In this work, we propose a principled causal-attribution framework for identifying behavior-relevant attention heads in transformers. For each head, we train a vector-quantized autoencoder (VQ-AE) on its attention activations, partitioning the latent space into behavior-relevant and behavior-irrelevant subspaces, each quantized with a shared learnable codebook. We assess the behavioral relevance of each head by quantifying the separability of VQ-AE encodings for behavior-aligned versus behavior-violating responses using a binary classification metric. This yields a behavioral relevance score that reflects each head discriminative capacity with respect to the target behavior, guiding both selection and importance weighting. Experiments on seven LLMs from two model families and five behavioral steering datasets demonstrate that our method enables more accurate inference-time interventions, achieving superior performance on the truthfulness-steering task. Furthermore, the heads selected by our approach exhibit strong zero-shot generalization in cross-domain truthfulness-steering scenarios.
MSEarth: A Benchmark for Multimodal Scientific Comprehension of Earth Science
May 27, 2025The rapid advancement of multimodal large language models (MLLMs) has unlocked new opportunities to tackle complex scientific challenges. Despite this progress, their application in addressing earth science problems, especially at the graduate level, remains underexplored. A significant barrier is the absence of benchmarks that capture the depth and contextual complexity of geoscientific reasoning. Current benchmarks often rely on synthetic datasets or simplistic figure-caption pairs, which do not adequately reflect the intricate reasoning and domain-specific insights required for real-world scientific applications. To address these gaps, we introduce MSEarth, a multimodal scientific benchmark curated from high-quality, open-access scientific publications. MSEarth encompasses the five major spheres of Earth science: atmosphere, cryosphere, hydrosphere, lithosphere, and biosphere, featuring over 7K figures with refined captions. These captions are crafted from the original figure captions and enriched with discussions and reasoning from the papers, ensuring the benchmark captures the nuanced reasoning and knowledge-intensive content essential for advanced scientific tasks. MSEarth supports a variety of tasks, including scientific figure captioning, multiple choice questions, and open-ended reasoning challenges. By bridging the gap in graduate-level benchmarks, MSEarth provides a scalable and high-fidelity resource to enhance the development and evaluation of MLLMs in scientific reasoning. The benchmark is publicly available to foster further research and innovation in this field. Resources related to this benchmark can be found at https://huggingface.co/MSEarth and https://github.com/xiangyu-mm/MSEarth.
X2C: A Dataset Featuring Nuanced Facial Expressions for Realistic Humanoid Imitation
May 16, 2025The ability to imitate realistic facial expressions is essential for humanoid robots engaged in affective human-robot communication. However, the lack of datasets containing diverse humanoid facial expressions with proper annotations hinders progress in realistic humanoid facial expression imitation. To address these challenges, we introduce X2C (Anything to Control), a dataset featuring nuanced facial expressions for realistic humanoid imitation. With X2C, we contribute: 1) a high-quality, high-diversity, large-scale dataset comprising 100,000 (image, control value) pairs. Each image depicts a humanoid robot displaying a diverse range of facial expressions, annotated with 30 control values representing the ground-truth expression configuration; 2) X2CNet, a novel human-to-humanoid facial expression imitation framework that learns the correspondence between nuanced humanoid expressions and their underlying control values from X2C. It enables facial expression imitation in the wild for different human performers, providing a baseline for the imitation task, showcasing the potential value of our dataset; 3) real-world demonstrations on a physical humanoid robot, highlighting its capability to advance realistic humanoid facial expression imitation. Code and Data: https://lipzh5.github.io/X2CNet/
LANID: LLM-assisted New Intent Discovery
Mar 31, 2025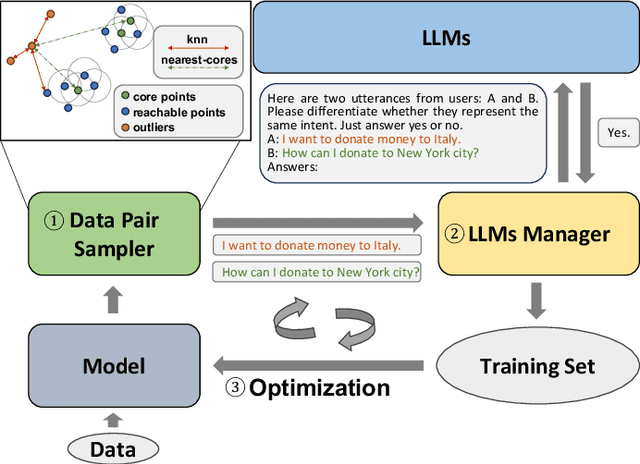

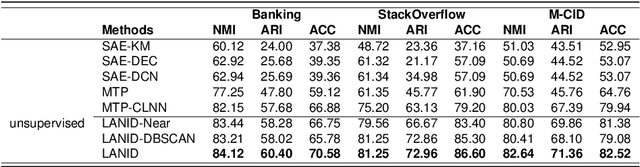
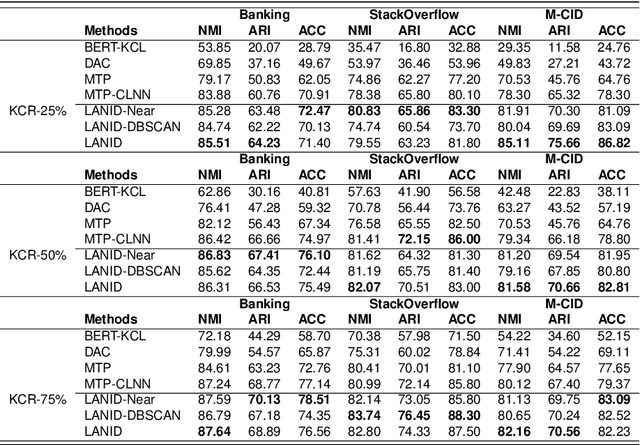
Task-oriented Dialogue Systems (TODS) often face the challenge of encountering new intents. New Intent Discovery (NID) is a crucial task that aims to identify these novel intents while maintaining the capability to recognize existing ones. Previous efforts to adapt TODS to new intents have struggled with inadequate semantic representation or have depended on external knowledge, which is often not scalable or flexible. Recently, Large Language Models (LLMs) have demonstrated strong zero-shot capabilities; however, their scale can be impractical for real-world applications that involve extensive queries. To address the limitations of existing NID methods by leveraging LLMs, we propose LANID, a framework that enhances the semantic representation of lightweight NID encoders with the guidance of LLMs. Specifically, LANID employs the $K$-nearest neighbors and Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithms to sample selective utterance pairs from the training set. It then queries an LLM to ascertain the relationships between these pairs. The data produced from this process is utilized to design a contrastive fine-tuning task, which is then used to train a small encoder with a contrastive triplet loss. Our experimental results demonstrate the efficacy of the proposed method across three distinct NID datasets, surpassing strong baselines in both unsupervised and semi-supervised settings. Our code is available at https://github.com/floatSDSDS/LANID.
Rethinking Bimanual Robotic Manipulation: Learning with Decoupled Interaction Framework
Mar 12, 2025Bimanual robotic manipulation is an emerging and critical topic in the robotics community. Previous works primarily rely on integrated control models that take the perceptions and states of both arms as inputs to directly predict their actions. However, we think bimanual manipulation involves not only coordinated tasks but also various uncoordinated tasks that do not require explicit cooperation during execution, such as grasping objects with the closest hand, which integrated control frameworks ignore to consider due to their enforced cooperation in the early inputs. In this paper, we propose a novel decoupled interaction framework that considers the characteristics of different tasks in bimanual manipulation. The key insight of our framework is to assign an independent model to each arm to enhance the learning of uncoordinated tasks, while introducing a selective interaction module that adaptively learns weights from its own arm to improve the learning of coordinated tasks. Extensive experiments on seven tasks in the RoboTwin dataset demonstrate that: (1) Our framework achieves outstanding performance, with a 23.5% boost over the SOTA method. (2) Our framework is flexible and can be seamlessly integrated into existing methods. (3) Our framework can be effectively extended to multi-agent manipulation tasks, achieving a 28% boost over the integrated control SOTA. (4) The performance boost stems from the decoupled design itself, surpassing the SOTA by 16.5% in success rate with only 1/6 of the model size.