 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRG-MotionLLM: Interleaving Motion Generation, Assessment and Refinement for Text-to-Motion Generation
Dec 11, 2025Recent advances in motion-aware large language models have shown remarkable promise for unifying motion understanding and generation tasks. However, these models typically treat understanding and generation separately, limiting the mutual benefits that could arise from interactive feedback between tasks. In this work, we reveal that motion assessment and refinement tasks act as crucial bridges to enable bidirectional knowledge flow between understanding and generation. Leveraging this insight, we propose Interleaved Reasoning for Motion Generation (IRMoGen), a novel paradigm that tightly couples motion generation with assessment and refinement through iterative text-motion dialogue. To realize this, we introduce IRG-MotionLLM, the first model that seamlessly interleaves motion generation, assessment, and refinement to improve generation performance. IRG-MotionLLM is developed progressively with a novel three-stage training scheme, initializing and subsequently enhancing native IRMoGen capabilities. To facilitate this development, we construct an automated data engine to synthesize interleaved reasoning annotations from existing text-motion datasets. Extensive experiments demonstrate that: (i) Assessment and refinement tasks significantly improve text-motion alignment; (ii) Interleaving motion generation, assessment, and refinement steps yields consistent performance gains across training stages; and (iii) IRG-MotionLLM clearly outperforms the baseline model and achieves advanced performance on standard text-to-motion generation benchmarks. Cross-evaluator testing further validates its effectiveness. Code & Data: https://github.com/HumanMLLM/IRG-MotionLLM/tree/main.
Efficient Explicit Joint-level Interaction Modeling with Mamba for Text-guided HOI Generation
Mar 29, 2025



We propose a novel approach for generating text-guided human-object interactions (HOIs) that achieves explicit joint-level interaction modeling in a computationally efficient manner. Previous methods represent the entire human body as a single token, making it difficult to capture fine-grained joint-level interactions and resulting in unrealistic HOIs. However, treating each individual joint as a token would yield over twenty times more tokens, increasing computational overhead. To address these challenges, we introduce an Efficient Explicit Joint-level Interaction Model (EJIM). EJIM features a Dual-branch HOI Mamba that separately and efficiently models spatiotemporal HOI information, as well as a Dual-branch Condition Injector for integrating text semantics and object geometry into human and object motions. Furthermore, we design a Dynamic Interaction Block and a progressive masking mechanism to iteratively filter out irrelevant joints, ensuring accurate and nuanced interaction modeling. Extensive quantitative and qualitative evaluations on public datasets demonstrate that EJIM surpasses previous works by a large margin while using only 5\% of the inference time. Code is available \href{https://github.com/Huanggh531/EJIM}{here}.
Progressive Human Motion Generation Based on Text and Few Motion Frames
Mar 17, 2025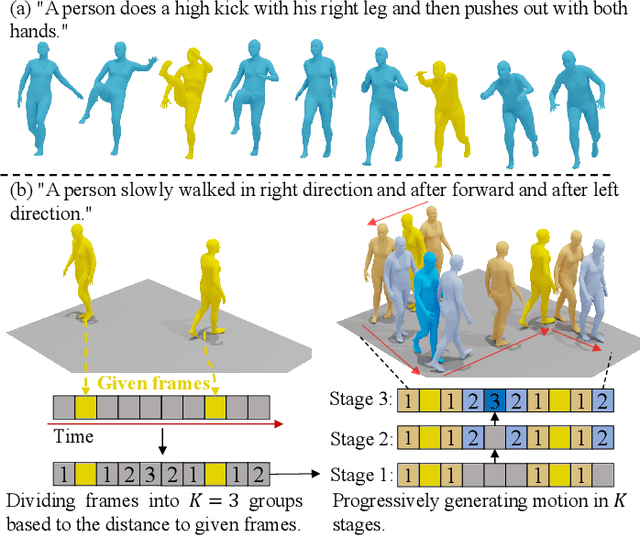



Although existing text-to-motion (T2M) methods can produce realistic human motion from text description, it is still difficult to align the generated motion with the desired postures since using text alone is insufficient for precisely describing diverse postures. To achieve more controllable generation, an intuitive way is to allow the user to input a few motion frames describing precise desired postures. Thus, we explore a new Text-Frame-to-Motion (TF2M) generation task that aims to generate motions from text and very few given frames. Intuitively, the closer a frame is to a given frame, the lower the uncertainty of this frame is when conditioned on this given frame. Hence, we propose a novel Progressive Motion Generation (PMG) method to progressively generate a motion from the frames with low uncertainty to those with high uncertainty in multiple stages. During each stage, new frames are generated by a Text-Frame Guided Generator conditioned on frame-aware semantics of the text, given frames, and frames generated in previous stages. Additionally, to alleviate the train-test gap caused by multi-stage accumulation of incorrectly generated frames during testing, we propose a Pseudo-frame Replacement Strategy for training. Experimental results show that our PMG outperforms existing T2M generation methods by a large margin with even one given frame, validating the effectiveness of our PMG. Code will be released.
ChainHOI: Joint-based Kinematic Chain Modeling for Human-Object Interaction Generation
Mar 17, 2025



We propose ChainHOI, a novel approach for text-driven human-object interaction (HOI) generation that explicitly models interactions at both the joint and kinetic chain levels. Unlike existing methods that implicitly model interactions using full-body poses as tokens, we argue that explicitly modeling joint-level interactions is more natural and effective for generating realistic HOIs, as it directly captures the geometric and semantic relationships between joints, rather than modeling interactions in the latent pose space. To this end, ChainHOI introduces a novel joint graph to capture potential interactions with objects, and a Generative Spatiotemporal Graph Convolution Network to explicitly model interactions at the joint level. Furthermore, we propose a Kinematics-based Interaction Module that explicitly models interactions at the kinetic chain level, ensuring more realistic and biomechanically coherent motions. Evaluations on two public datasets demonstrate that ChainHOI significantly outperforms previous methods, generating more realistic, and semantically consistent HOIs. Code is available \href{https://github.com/qinghuannn/ChainHOI}{here}.
Rethinking Bimanual Robotic Manipulation: Learning with Decoupled Interaction Framework
Mar 12, 2025Bimanual robotic manipulation is an emerging and critical topic in the robotics community. Previous works primarily rely on integrated control models that take the perceptions and states of both arms as inputs to directly predict their actions. However, we think bimanual manipulation involves not only coordinated tasks but also various uncoordinated tasks that do not require explicit cooperation during execution, such as grasping objects with the closest hand, which integrated control frameworks ignore to consider due to their enforced cooperation in the early inputs. In this paper, we propose a novel decoupled interaction framework that considers the characteristics of different tasks in bimanual manipulation. The key insight of our framework is to assign an independent model to each arm to enhance the learning of uncoordinated tasks, while introducing a selective interaction module that adaptively learns weights from its own arm to improve the learning of coordinated tasks. Extensive experiments on seven tasks in the RoboTwin dataset demonstrate that: (1) Our framework achieves outstanding performance, with a 23.5% boost over the SOTA method. (2) Our framework is flexible and can be seamlessly integrated into existing methods. (3) Our framework can be effectively extended to multi-agent manipulation tasks, achieving a 28% boost over the integrated control SOTA. (4) The performance boost stems from the decoupled design itself, surpassing the SOTA by 16.5% in success rate with only 1/6 of the model size.
AffordDexGrasp: Open-set Language-guided Dexterous Grasp with Generalizable-Instructive Affordance
Mar 10, 2025Language-guided robot dexterous generation enables robots to grasp and manipulate objects based on human commands. However, previous data-driven methods are hard to understand intention and execute grasping with unseen categories in the open set. In this work, we explore a new task, Open-set Language-guided Dexterous Grasp, and find that the main challenge is the huge gap between high-level human language semantics and low-level robot actions. To solve this problem, we propose an Affordance Dexterous Grasp (AffordDexGrasp) framework, with the insight of bridging the gap with a new generalizable-instructive affordance representation. This affordance can generalize to unseen categories by leveraging the object's local structure and category-agnostic semantic attributes, thereby effectively guiding dexterous grasp generation. Built upon the affordance, our framework introduces Affordacne Flow Matching (AFM) for affordance generation with language as input, and Grasp Flow Matching (GFM) for generating dexterous grasp with affordance as input. To evaluate our framework, we build an open-set table-top language-guided dexterous grasp dataset. Extensive experiments in the simulation and real worlds show that our framework surpasses all previous methods in open-set generalization.
Light-T2M: A Lightweight and Fast Model for Text-to-motion Generation
Dec 15, 2024Despite the significant role text-to-motion (T2M) generation plays across various applications, current methods involve a large number of parameters and suffer from slow inference speeds, leading to high usage costs. To address this, we aim to design a lightweight model to reduce usage costs. First, unlike existing works that focus solely on global information modeling, we recognize the importance of local information modeling in the T2M task by reconsidering the intrinsic properties of human motion, leading us to propose a lightweight Local Information Modeling Module. Second, we introduce Mamba to the T2M task, reducing the number of parameters and GPU memory demands, and we have designed a novel Pseudo-bidirectional Scan to replicate the effects of a bidirectional scan without increasing parameter count. Moreover, we propose a novel Adaptive Textual Information Injector that more effectively integrates textual information into the motion during generation. By integrating the aforementioned designs, we propose a lightweight and fast model named Light-T2M. Compared to the state-of-the-art method, MoMask, our Light-T2M model features just 10\% of the parameters (4.48M vs 44.85M) and achieves a 16\% faster inference time (0.152s vs 0.180s), while surpassing MoMask with an FID of \textbf{0.040} (vs. 0.045) on HumanML3D dataset and 0.161 (vs. 0.228) on KIT-ML dataset. The code is available at https://github.com/qinghuannn/light-t2m.
TechCoach: Towards Technical Keypoint-Aware Descriptive Action Coaching
Nov 26, 2024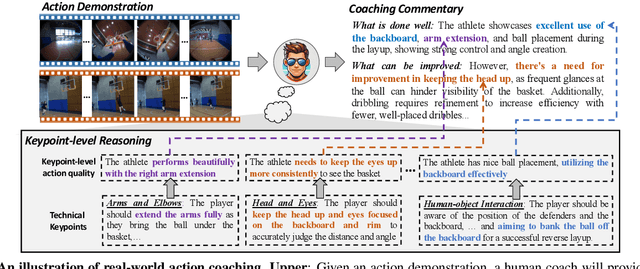
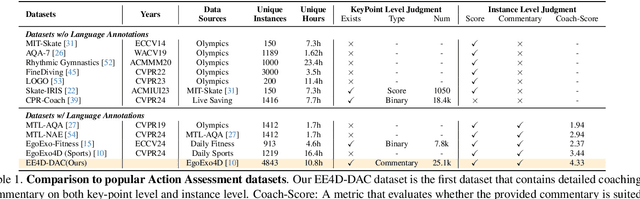
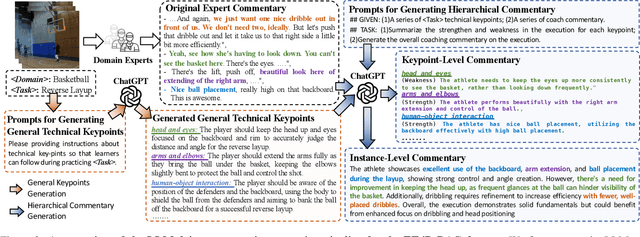

To guide a learner to master the action skills, it is crucial for a coach to 1) reason through the learner's action execution and technical keypoints, and 2) provide detailed, understandable feedback on what is done well and what can be improved. However, existing score-based action assessment methods are still far from this practical scenario. To bridge this gap, we investigate a new task termed Descriptive Action Coaching (DAC) which requires a model to provide detailed commentary on what is done well and what can be improved beyond a quality score from an action execution. To this end, we construct a new dataset named EE4D-DAC. With an LLM-based annotation pipeline, our dataset goes beyond the existing action assessment datasets by providing the hierarchical coaching commentary at both keypoint and instance levels. Furthermore, we propose TechCoach, a new framework that explicitly incorporates keypoint-level reasoning into the DAC process. The central to our method lies in the Context-aware Keypoint Reasoner, which enables TechCoach to learn keypoint-related quality representations by querying visual context under the supervision of keypoint-level coaching commentary. Prompted by the visual context and the keypoint-related quality representations, a unified Keypoint-aware Action Assessor is then employed to provide the overall coaching commentary together with the quality score. Combining all of these, we build a new benchmark for DAC and evaluate the effectiveness of our method through extensive experiments. Data and code will be publicly available.
EgoExo-Fitness: Towards Egocentric and Exocentric Full-Body Action Understanding
Jun 13, 2024We present EgoExo-Fitness, a new full-body action understanding dataset, featuring fitness sequence videos recorded from synchronized egocentric and fixed exocentric (third-person) cameras. Compared with existing full-body action understanding datasets, EgoExo-Fitness not only contains videos from first-person perspectives, but also provides rich annotations. Specifically, two-level temporal boundaries are provided to localize single action videos along with sub-steps of each action. More importantly, EgoExo-Fitness introduces innovative annotations for interpretable action judgement--including technical keypoint verification, natural language comments on action execution, and action quality scores. Combining all of these, EgoExo-Fitness provides new resources to study egocentric and exocentric full-body action understanding across dimensions of "what", "when", and "how well". To facilitate research on egocentric and exocentric full-body action understanding, we construct benchmarks on a suite of tasks (i.e., action classification, action localization, cross-view sequence verification, cross-view skill determination, and a newly proposed task of guidance-based execution verification), together with detailed analysis. Code and data will be available at https://github.com/iSEE-Laboratory/EgoExo-Fitness/tree/main.
Continual Action Assessment via Task-Consistent Score-Discriminative Feature Distribution Modeling
Sep 29, 2023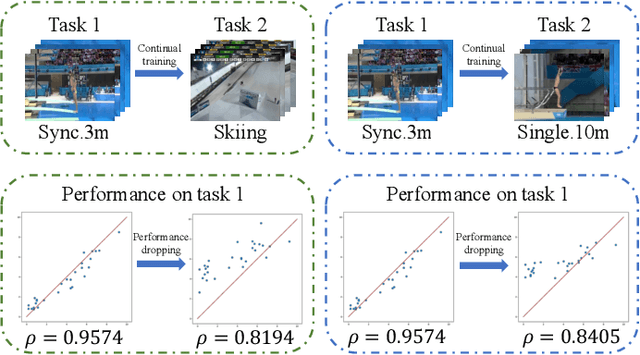
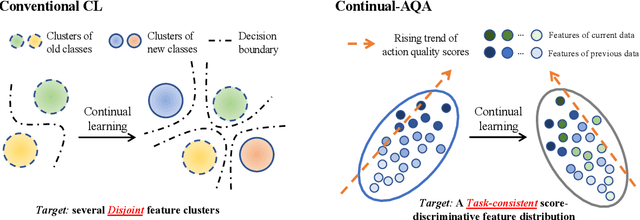
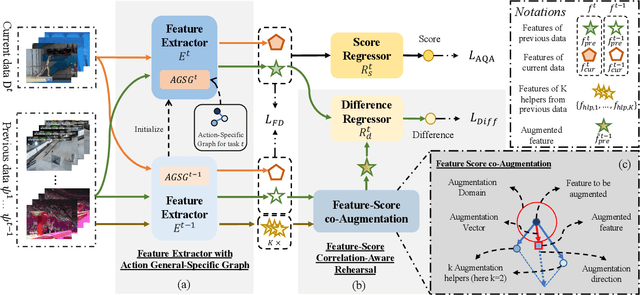
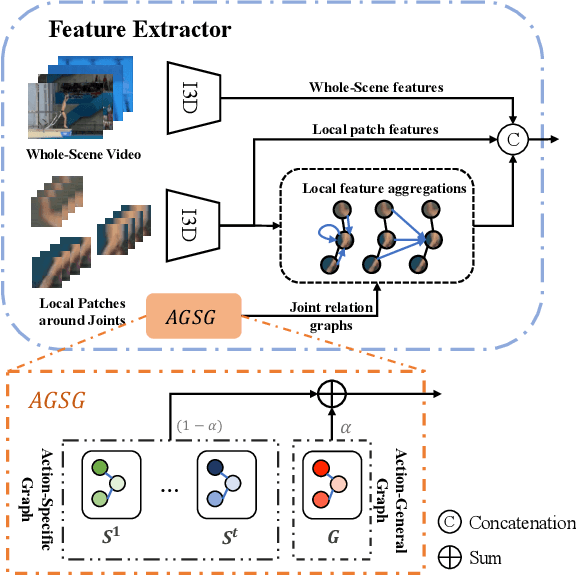
Action Quality Assessment (AQA) is a task that tries to answer how well an action is carried out. While remarkable progress has been achieved, existing works on AQA assume that all the training data are visible for training in one time, but do not enable continual learning on assessing new technical actions. In this work, we address such a Continual Learning problem in AQA (Continual-AQA), which urges a unified model to learn AQA tasks sequentially without forgetting. Our idea for modeling Continual-AQA is to sequentially learn a task-consistent score-discriminative feature distribution, in which the latent features express a strong correlation with the score labels regardless of the task or action types. From this perspective, we aim to mitigate the forgetting in Continual-AQA from two aspects. Firstly, to fuse the features of new and previous data into a score-discriminative distribution, a novel Feature-Score Correlation-Aware Rehearsal is proposed to store and reuse data from previous tasks with limited memory size. Secondly, an Action General-Specific Graph is developed to learn and decouple the action-general and action-specific knowledge so that the task-consistent score-discriminative features can be better extracted across various tasks. Extensive experiments are conducted to evaluate the contributions of proposed components. The comparisons with the existing continual learning methods additionally verify the effectiveness and versatility of our approach.