 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Human Motion Generation Based on Text and Few Motion Frames
Mar 17, 2025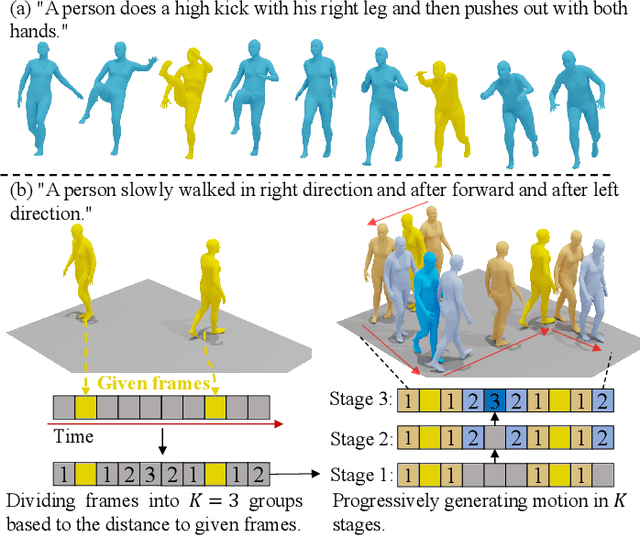



Although existing text-to-motion (T2M) methods can produce realistic human motion from text description, it is still difficult to align the generated motion with the desired postures since using text alone is insufficient for precisely describing diverse postures. To achieve more controllable generation, an intuitive way is to allow the user to input a few motion frames describing precise desired postures. Thus, we explore a new Text-Frame-to-Motion (TF2M) generation task that aims to generate motions from text and very few given frames. Intuitively, the closer a frame is to a given frame, the lower the uncertainty of this frame is when conditioned on this given frame. Hence, we propose a novel Progressive Motion Generation (PMG) method to progressively generate a motion from the frames with low uncertainty to those with high uncertainty in multiple stages. During each stage, new frames are generated by a Text-Frame Guided Generator conditioned on frame-aware semantics of the text, given frames, and frames generated in previous stages. Additionally, to alleviate the train-test gap caused by multi-stage accumulation of incorrectly generated frames during testing, we propose a Pseudo-frame Replacement Strategy for training. Experimental results show that our PMG outperforms existing T2M generation methods by a large margin with even one given frame, validating the effectiveness of our PMG. Code will be released.
Light-T2M: A Lightweight and Fast Model for Text-to-motion Generation
Dec 15, 2024Despite the significant role text-to-motion (T2M) generation plays across various applications, current methods involve a large number of parameters and suffer from slow inference speeds, leading to high usage costs. To address this, we aim to design a lightweight model to reduce usage costs. First, unlike existing works that focus solely on global information modeling, we recognize the importance of local information modeling in the T2M task by reconsidering the intrinsic properties of human motion, leading us to propose a lightweight Local Information Modeling Module. Second, we introduce Mamba to the T2M task, reducing the number of parameters and GPU memory demands, and we have designed a novel Pseudo-bidirectional Scan to replicate the effects of a bidirectional scan without increasing parameter count. Moreover, we propose a novel Adaptive Textual Information Injector that more effectively integrates textual information into the motion during generation. By integrating the aforementioned designs, we propose a lightweight and fast model named Light-T2M. Compared to the state-of-the-art method, MoMask, our Light-T2M model features just 10\% of the parameters (4.48M vs 44.85M) and achieves a 16\% faster inference time (0.152s vs 0.180s), while surpassing MoMask with an FID of \textbf{0.040} (vs. 0.045) on HumanML3D dataset and 0.161 (vs. 0.228) on KIT-ML dataset. The code is available at https://github.com/qinghuannn/light-t2m.
PSLT: A Light-weight Vision Transformer with Ladder Self-Attention and Progressive Shift
Apr 07, 2023Vision Transformer (ViT) has shown great potential for various visual tasks due to its ability to model long-range dependency. However, ViT requires a large amount of computing resource to compute the global self-attention. In this work, we propose a ladder self-attention block with multiple branches and a progressive shift mechanism to develop a light-weight transformer backbone that requires less computing resources (e.g. a relatively small number of parameters and FLOPs), termed Progressive Shift Ladder Transformer (PSLT). First, the ladder self-attention block reduces the computational cost by modelling local self-attention in each branch. In the meanwhile, the progressive shift mechanism is proposed to enlarge the receptive field in the ladder self-attention block by modelling diverse local self-attention for each branch and interacting among these branches. Second, the input feature of the ladder self-attention block is split equally along the channel dimension for each branch, which considerably reduces the computational cost in the ladder self-attention block (with nearly 1/3 the amount of parameters and FLOPs), and the outputs of these branches are then collaborated by a pixel-adaptive fusion. Therefore, the ladder self-attention block with a relatively small number of parameters and FLOPs is capable of modelling long-range interactions. Based on the ladder self-attention block, PSLT performs well on several vision tasks, including image classification, objection detection and person re-identification. On the ImageNet-1k dataset, PSLT achieves a top-1 accuracy of 79.9% with 9.2M parameters and 1.9G FLOPs, which is comparable to several existing models with more than 20M parameters and 4G FLOPs. Code is available at https://isee-ai.cn/wugaojie/PSLT.html.
* Accepted to IEEE Transaction on Pattern Analysis and Machine Intelligence, 2023 (Submission date: 08-Jul-202)
Combined Depth Space based Architecture Search For Person Re-identification
Apr 09, 2021


Most works on person re-identification (ReID) take advantage of large backbone networks such as ResNet, which are designed for image classification instead of ReID, for feature extraction. However, these backbones may not be computationally efficient or the most suitable architectures for ReID. In this work, we aim to design a lightweight and suitable network for ReID. We propose a novel search space called Combined Depth Space (CDS), based on which we search for an efficient network architecture, which we call CDNet, via a differentiable architecture search algorithm. Through the use of the combined basic building blocks in CDS, CDNet tends to focus on combined pattern information that is typically found in images of pedestrians. We then propose a low-cost search strategy named the Top-k Sample Search strategy to make full use of the search space and avoid trapping in local optimal result. Furthermore, an effective Fine-grained Balance Neck (FBLNeck), which is removable at the inference time, is presented to balance the effects of triplet loss and softmax loss during the training process. Extensive experiments show that our CDNet (~1.8M parameters) has comparable performance with state-of-the-art lightweight networks.