 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADM-DP: Adaptive Dynamic Modality Diffusion Policy through Vision-Tactile-Graph Fusion for Multi-Agent Manipulation
Feb 25, 2026Multi-agent robotic manipulation remains challenging due to the combined demands of coordination, grasp stability, and collision avoidance in shared workspaces. To address these challenges, we propose the Adaptive Dynamic Modality Diffusion Policy (ADM-DP), a framework that integrates vision, tactile, and graph-based (multi-agent pose) modalities for coordinated control. ADM-DP introduces four key innovations. First, an enhanced visual encoder merges RGB and point-cloud features via Feature-wise Linear Modulation (FiLM) modulation to enrich perception. Second, a tactile-guided grasping strategy uses Force-Sensitive Resistor (FSR) feedback to detect insufficient contact and trigger corrective grasp refinement, improving grasp stability. Third, a graph-based collision encoder leverages shared tool center point (TCP) positions of multiple agents as structured kinematic context to maintain spatial awareness and reduce inter-agent interference. Fourth, an Adaptive Modality Attention Mechanism (AMAM) dynamically re-weights modalities according to task context, enabling flexible fusion. For scalability and modularity, a decoupled training paradigm is employed in which agents learn independent policies while sharing spatial information. This maintains low interdependence between agents while retaining collective awareness. Across seven multi-agent tasks, ADM-DP achieves 12-25% performance gains over state-of-the-art baselines. Ablation studies show the greatest improvements in tasks requiring multiple sensory modalities, validating our adaptive fusion strategy and demonstrating its robustness for diverse manipulation scenarios.
Design and Control of Modular Magnetic Millirobots for Multimodal Locomotion and Shape Reconfiguration
Feb 22, 2026Modular small-scale robots offer the potential for on-demand assembly and disassembly, enabling task-specific adaptation in dynamic and constrained environments. However, existing modular magnetic platforms often depend on workspace collisions for reconfiguration, employ bulky three-dimensional electromagnetic systems, and lack robust single-module control, which limits their applicability in biomedical settings. In this work, we present a modular magnetic millirobotic platform comprising three cube-shaped modules with embedded permanent magnets, each designed for a distinct functional role: a free module that supports self-assembly and reconfiguration, a fixed module that enables flip-and-walk locomotion, and a gripper module for cargo manipulation. Locomotion and reconfiguration are actuated by programmable combinations of time-varying two-dimensional uniform and gradient magnetic field inputs. Experiments demonstrate closed-loop navigation using real-time vision feedback and A* path planning, establishing robust single-module control capabilities. Beyond locomotion, the system achieves self-assembly, multimodal transformations, and disassembly at low field strengths. Chain-to-gripper transformations succeeded in 90% of trials, while chain-to-square transformations were less consistent, underscoring the role of module geometry in reconfiguration reliability. These results establish a versatile modular robotic platform capable of multimodal behavior and robust control, suggesting a promising pathway toward scalable and adaptive task execution in confined environments.
MultiDiffSense: Diffusion-Based Multi-Modal Visuo-Tactile Image Generation Conditioned on Object Shape and Contact Pose
Feb 22, 2026Acquiring aligned visuo-tactile datasets is slow and costly, requiring specialised hardware and large-scale data collection. Synthetic generation is promising, but prior methods are typically single-modality, limiting cross-modal learning. We present MultiDiffSense, a unified diffusion model that synthesises images for multiple vision-based tactile sensors (ViTac, TacTip, ViTacTip) within a single architecture. Our approach uses dual conditioning on CAD-derived, pose-aligned depth maps and structured prompts that encode sensor type and 4-DoF contact pose, enabling controllable, physically consistent multi-modal synthesis. Evaluating on 8 objects (5 seen, 3 novel) and unseen poses, MultiDiffSense outperforms a Pix2Pix cGAN baseline in SSIM by +36.3% (ViTac), +134.6% (ViTacTip), and +64.7% (TacTip). For downstream 3-DoF pose estimation, mixing 50% synthetic with 50% real halves the required real data while maintaining competitive performance. MultiDiffSense alleviates the data-collection bottleneck in tactile sensing and enables scalable, controllable multi-modal dataset generation for robotic applications.
TactEx: An Explainable Multimodal Robotic Interaction Framework for Human-Like Touch and Hardness Estimation
Feb 21, 2026Accurate perception of object hardness is essential for safe and dexterous contact-rich robotic manipulation. Here, we present TactEx, an explainable multimodal robotic interaction framework that unifies vision, touch, and language for human-like hardness estimation and interactive guidance. We evaluate TactEx on fruit-ripeness assessment, a representative task that requires both tactile sensing and contextual understanding. The system fuses GelSight-Mini tactile streams with RGB observations and language prompts. A ResNet50+LSTM model estimates hardness from sequential tactile data, while a cross-modal alignment module combines visual cues with guidance from a large language model (LLM). This explainable multimodal interface allows users to distinguish ripeness levels with statistically significant class separation (p < 0.01 for all fruit pairs). For touch placement, we compare YOLO with Grounded-SAM (GSAM) and find GSAM to be more robust for fine-grained segmentation and contact-site selection. A lightweight LLM parses user instructions and produces grounded natural-language explanations linked to the tactile outputs. In end-to-end evaluations, TactEx attains 90% task success on simple user queries and generalises to novel tasks without large-scale tuning. These results highlight the promise of combining pretrained visual and tactile models with language grounding to advance explainable, human-like touch perception and decision-making in robotics.
Stop the Flip-Flop: Context-Preserving Verification for Fast Revocable Diffusion Decoding
Feb 05, 2026Parallel diffusion decoding can accelerate diffusion language model inference by unmasking multiple tokens per step, but aggressive parallelism often harms quality. Revocable decoding mitigates this by rechecking earlier tokens, yet we observe that existing verification schemes frequently trigger flip-flop oscillations, where tokens are remasked and later restored unchanged. This behaviour slows inference in two ways: remasking verified positions weakens the conditioning context for parallel drafting, and repeated remask cycles consume the revision budget with little net progress. We propose COVER (Cache Override Verification for Efficient Revision), which performs leave-one-out verification and stable drafting within a single forward pass. COVER constructs two attention views via KV cache override: selected seeds are masked for verification, while their cached key value states are injected for all other queries to preserve contextual information, with a closed form diagonal correction preventing self leakage at the seed positions. COVER further prioritises seeds using a stability aware score that balances uncertainty, downstream influence, and cache drift, and it adapts the number of verified seeds per step. Across benchmarks, COVER markedly reduces unnecessary revisions and yields faster decoding while preserving output quality.
Optical Computation-in-Communication enables low-latency, high-fidelity perception in telesurgery
Oct 15, 2025Artificial intelligence (AI) holds significant promise for enhancing intraoperative perception and decision-making in telesurgery, where physical separation impairs sensory feedback and control. Despite advances in medical AI and surgical robotics, conventional electronic AI architectures remain fundamentally constrained by the compounded latency from serial processing of inference and communication. This limitation is especially critical in latency-sensitive procedures such as endovascular interventions, where delays over 200 ms can compromise real-time AI reliability and patient safety. Here, we introduce an Optical Computation-in-Communication (OCiC) framework that reduces end-to-end latency significantly by performing AI inference concurrently with optical communication. OCiC integrates Optical Remote Computing Units (ORCUs) directly into the optical communication pathway, with each ORCU experimentally achieving up to 69 tera-operations per second per channel through spectrally efficient two-dimensional photonic convolution. The system maintains ultrahigh inference fidelity within 0.1% of CPU/GPU baselines on classification and coronary angiography segmentation, while intrinsically mitigating cumulative error propagation, a longstanding barrier to deep optical network scalability. We validated the robustness of OCiC through outdoor dark fibre deployments, confirming consistent and stable performance across varying environmental conditions. When scaled globally, OCiC transforms long-haul fibre infrastructure into a distributed photonic AI fabric with exascale potential, enabling reliable, low-latency telesurgery across distances up to 10,000 km and opening a new optical frontier for distributed medical intelligence.
TypeTele: Releasing Dexterity in Teleoperation by Dexterous Manipulation Types
Jul 02, 2025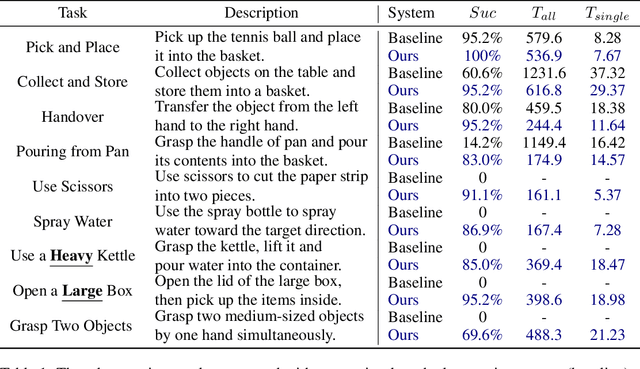


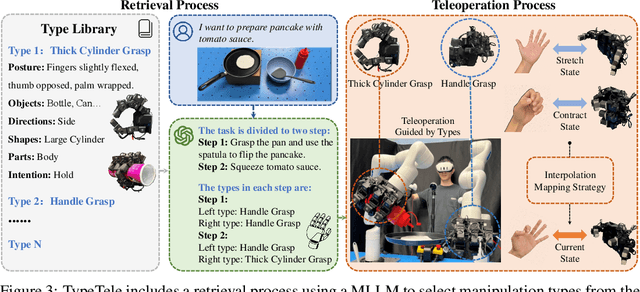
Dexterous teleoperation plays a crucial role in robotic manipulation for real-world data collection and remote robot control. Previous dexterous teleoperation mostly relies on hand retargeting to closely mimic human hand postures. However, these approaches may fail to fully leverage the inherent dexterity of dexterous hands, which can execute unique actions through their structural advantages compared to human hands. To address this limitation, we propose TypeTele, a type-guided dexterous teleoperation system, which enables dexterous hands to perform actions that are not constrained by human motion patterns. This is achieved by introducing dexterous manipulation types into the teleoperation system, allowing operators to employ appropriate types to complete specific tasks. To support this system, we build an extensible dexterous manipulation type library to cover comprehensive dexterous postures used in manipulation tasks. During teleoperation, we employ a MLLM (Multi-modality Large Language Model)-assisted type retrieval module to identify the most suitable manipulation type based on the specific task and operator commands. Extensive experiments of real-world teleoperation and imitation learning demonstrate that the incorporation of manipulation types significantly takes full advantage of the dexterous robot's ability to perform diverse and complex tasks with higher success rates.
MagicGripper: A Multimodal Sensor-Integrated Gripper for Contact-Rich Robotic Manipulation
May 30, 2025Contact-rich manipulation in unstructured environments demands precise, multimodal perception to enable robust and adaptive control. Vision-based tactile sensors (VBTSs) have emerged as an effective solution; however, conventional VBTSs often face challenges in achieving compact, multi-modal functionality due to hardware constraints and algorithmic complexity. In this work, we present MagicGripper, a multimodal sensor-integrated gripper designed for contact-rich robotic manipulation. Building on our prior design, MagicTac, we develop a compact variant, mini-MagicTac, which features a three-dimensional, multi-layered grid embedded in a soft elastomer. MagicGripper integrates mini-MagicTac, enabling high-resolution tactile feedback alongside proximity and visual sensing within a compact, gripper-compatible form factor. We conduct a thorough evaluation of mini-MagicTac's performance, demonstrating its capabilities in spatial resolution, contact localization, and force regression. We also assess its robustness across manufacturing variability, mechanical deformation, and sensing performance under real-world conditions. Furthermore, we validate the effectiveness of MagicGripper through three representative robotic tasks: a teleoperated assembly task, a contact-based alignment task, and an autonomous robotic grasping task. Across these experiments, MagicGripper exhibits reliable multimodal perception, accurate force estimation, and high adaptability to challenging manipulation scenarios. Our results highlight the potential of MagicGripper as a practical and versatile tool for embodied intelligence in complex, contact-rich environments.
Jigsaw-Puzzles: From Seeing to Understanding to Reasoning in Vision-Language Models
May 27, 2025Spatial reasoning is a core component of human cognition, enabling individuals to perceive, comprehend, and interact with the physical world. It relies on a nuanced understanding of spatial structures and inter-object relationships, serving as the foundation for complex reasoning and decision-making. To investigate whether current vision-language models (VLMs) exhibit similar capability, we introduce Jigsaw-Puzzles, a novel benchmark consisting of 1,100 carefully curated real-world images with high spatial complexity. Based on this dataset, we design five tasks to rigorously evaluate VLMs' spatial perception, structural understanding, and reasoning capabilities, while deliberately minimizing reliance on domain-specific knowledge to better isolate and assess the general spatial reasoning capability. We conduct a comprehensive evaluation across 24 state-of-the-art VLMs. The results show that even the strongest model, Gemini-2.5-Pro, achieves only 77.14% overall accuracy and performs particularly poorly on the Order Generation task, with only 30.00% accuracy, far below the performance exceeding 90% achieved by human participants. This persistent gap underscores the need for continued progress, positioning Jigsaw-Puzzles as a challenging and diagnostic benchmark for advancing spatial reasoning research in VLMs.
A Dataset and Benchmarks for Deep Learning-Based Optical Microrobot Pose and Depth Perception
May 23, 2025Optical microrobots, manipulated via optical tweezers (OT), have broad applications in biomedicine. However, reliable pose and depth perception remain fundamental challenges due to the transparent or low-contrast nature of the microrobots, as well as the noisy and dynamic conditions of the microscale environments in which they operate. An open dataset is crucial for enabling reproducible research, facilitating benchmarking, and accelerating the development of perception models tailored to microscale challenges. Standardised evaluation enables consistent comparison across algorithms, ensuring objective benchmarking and facilitating reproducible research. Here, we introduce the OpTical MicroRobot dataset (OTMR), the first publicly available dataset designed to support microrobot perception under the optical microscope. OTMR contains 232,881 images spanning 18 microrobot types and 176 distinct poses. We benchmarked the performance of eight deep learning models, including architectures derived via neural architecture search (NAS), on two key tasks: pose classification and depth regression. Results indicated that Vision Transformer (ViT) achieve the highest accuracy in pose classification, while depth regression benefits from deeper architectures. Additionally, increasing the size of the training dataset leads to substantial improvements across both tasks, highlighting OTMR's potential as a foundational resource for robust and generalisable microrobot perception in complex microscale environments.