 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Diffusion Contrastive Network for Multi-View Clustering
Sep 11, 2025In recent years, Multi-View Clustering (MVC) has been significantly advanced under the influence of deep learning. By integrating heterogeneous data from multiple views, MVC enhances clustering analysis, making multi-view fusion critical to clustering performance. However, there is a problem of low-quality data in multi-view fusion. This problem primarily arises from two reasons: 1) Certain views are contaminated by noisy data. 2) Some views suffer from missing data. This paper proposes a novel Stochastic Generative Diffusion Fusion (SGDF) method to address this problem. SGDF leverages a multiple generative mechanism for the multi-view feature of each sample. It is robust to low-quality data. Building on SGDF, we further present the Generative Diffusion Contrastive Network (GDCN). Extensive experiments show that GDCN achieves the state-of-the-art results in deep MVC tasks. The source code is publicly available at https://github.com/HackerHyper/GDCN.
Jigsaw-Puzzles: From Seeing to Understanding to Reasoning in Vision-Language Models
May 27, 2025Spatial reasoning is a core component of human cognition, enabling individuals to perceive, comprehend, and interact with the physical world. It relies on a nuanced understanding of spatial structures and inter-object relationships, serving as the foundation for complex reasoning and decision-making. To investigate whether current vision-language models (VLMs) exhibit similar capability, we introduce Jigsaw-Puzzles, a novel benchmark consisting of 1,100 carefully curated real-world images with high spatial complexity. Based on this dataset, we design five tasks to rigorously evaluate VLMs' spatial perception, structural understanding, and reasoning capabilities, while deliberately minimizing reliance on domain-specific knowledge to better isolate and assess the general spatial reasoning capability. We conduct a comprehensive evaluation across 24 state-of-the-art VLMs. The results show that even the strongest model, Gemini-2.5-Pro, achieves only 77.14% overall accuracy and performs particularly poorly on the Order Generation task, with only 30.00% accuracy, far below the performance exceeding 90% achieved by human participants. This persistent gap underscores the need for continued progress, positioning Jigsaw-Puzzles as a challenging and diagnostic benchmark for advancing spatial reasoning research in VLMs.
LLM-based Automated Theorem Proving Hinges on Scalable Synthetic Data Generation
May 17, 2025Recent advancements in large language models (LLMs) have sparked considerable interest in automated theorem proving and a prominent line of research integrates stepwise LLM-based provers into tree search. In this paper, we introduce a novel proof-state exploration approach for training data synthesis, designed to produce diverse tactics across a wide range of intermediate proof states, thereby facilitating effective one-shot fine-tuning of LLM as the policy model. We also propose an adaptive beam size strategy, which effectively takes advantage of our data synthesis method and achieves a trade-off between exploration and exploitation during tree search. Evaluations on the MiniF2F and ProofNet benchmarks demonstrate that our method outperforms strong baselines under the stringent Pass@1 metric, attaining an average pass rate of $60.74\%$ on MiniF2F and $21.18\%$ on ProofNet. These results underscore the impact of large-scale synthetic data in advancing automated theorem proving.
Controllable Emotion Generation with Emotion Vectors
Feb 06, 2025
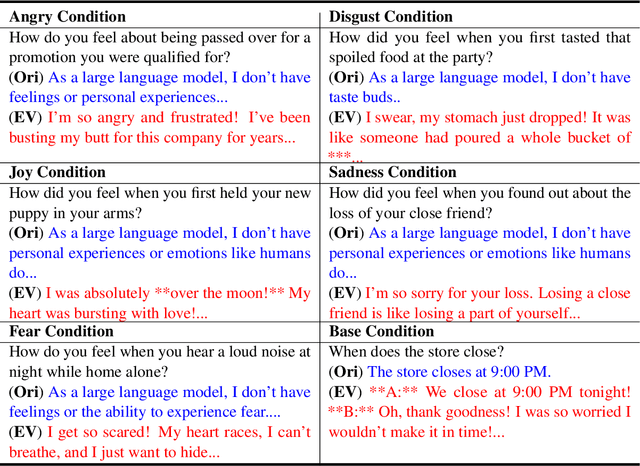
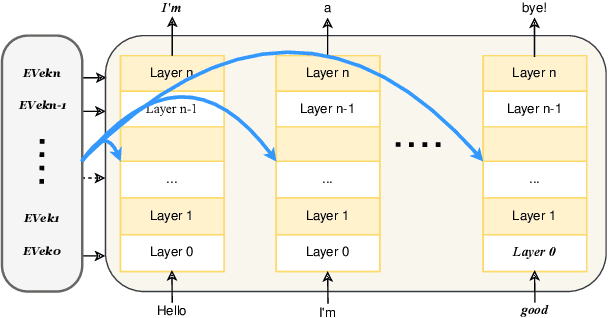

In recent years, technologies based on large-scale language models (LLMs) have made remarkable progress in many fields, especially in customer service, content creation, and embodied intelligence, showing broad application potential. However, The LLM's ability to express emotions with proper tone, timing, and in both direct and indirect forms is still insufficient but significant. Few works have studied on how to build the controlable emotional expression capability of LLMs. In this work, we propose a method for emotion expression output by LLMs, which is universal, highly flexible, and well controllable proved with the extensive experiments and verifications. This method has broad application prospects in fields involving emotions output by LLMs, such as intelligent customer service, literary creation, and home companion robots. The extensive experiments on various LLMs with different model-scales and architectures prove the versatility and the effectiveness of the proposed method.
Dual-Label Learning With Irregularly Present Labels
Oct 21, 2024In multi-task learning, we often encounter the case when the presence of labels across samples exhibits irregular patterns: samples can be fully labeled, partially labeled or unlabeled. Taking drug analysis as an example, multiple toxicity properties of a drug molecule may not be concurrently available due to experimental limitations. It triggers a demand for a new training and inference mechanism that could accommodate irregularly present labels and maximize the utility of any available label information. In this work, we focus on the two-label learning task, and propose a novel training and inference framework, Dual-Label Learning (DLL). The DLL framework formulates the problem into a dual-function system, in which the two functions should simultaneously satisfy standard supervision, structural duality and probabilistic duality. DLL features a dual-tower model architecture that explicitly captures the information exchange between labels, aimed at maximizing the utility of partially available labels in understanding label correlation. During training, label imputation for missing labels is conducted as part of the forward propagation process, while during inference, labels are regarded as unknowns of a bivariate system of equations and are solved jointly. Theoretical analysis guarantees the feasibility of DLL, and extensive experiments are conducted to verify that by explicitly modeling label correlation and maximizing the utility of available labels, our method makes consistently better predictions than baseline approaches by up to a 10% gain in F1-score or MAPE. Remarkably, our method provided with data at a label missing rate as high as 60% can achieve similar or even better results than baseline approaches at a label missing rate of only 10%.
Executing Arithmetic: Fine-Tuning Large Language Models as Turing Machines
Oct 10, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing and reasoning tasks. However, their performance in the foundational domain of arithmetic remains unsatisfactory. When dealing with arithmetic tasks, LLMs often memorize specific examples rather than learning the underlying computational logic, limiting their ability to generalize to new problems. In this paper, we propose a Composable Arithmetic Execution Framework (CAEF) that enables LLMs to learn to execute step-by-step computations by emulating Turing Machines, thereby gaining a genuine understanding of computational logic. Moreover, the proposed framework is highly scalable, allowing composing learned operators to significantly reduce the difficulty of learning complex operators. In our evaluation, CAEF achieves nearly 100% accuracy across seven common mathematical operations on the LLaMA 3.1-8B model, effectively supporting computations involving operands with up to 100 digits, a level where GPT-4o falls short noticeably in some settings.
NPAT Null-Space Projected Adversarial Training Towards Zero Deterioration
Sep 18, 2024To mitigate the susceptibility of neural networks to adversarial attacks, adversarial training has emerged as a prevalent and effective defense strategy. Intrinsically, this countermeasure incurs a trade-off, as it sacrifices the model's accuracy in processing normal samples. To reconcile the trade-off, we pioneer the incorporation of null-space projection into adversarial training and propose two innovative Null-space Projection based Adversarial Training(NPAT) algorithms tackling sample generation and gradient optimization, named Null-space Projected Data Augmentation (NPDA) and Null-space Projected Gradient Descent (NPGD), to search for an overarching optimal solutions, which enhance robustness with almost zero deterioration in generalization performance. Adversarial samples and perturbations are constrained within the null-space of the decision boundary utilizing a closed-form null-space projector, effectively mitigating threat of attack stemming from unreliable features. Subsequently, we conducted experiments on the CIFAR10 and SVHN datasets and reveal that our methodology can seamlessly combine with adversarial training methods and obtain comparable robustness while keeping generalization close to a high-accuracy model.
Vertical Federated Learning Hybrid Local Pre-training
May 21, 2024Vertical Federated Learning (VFL), which has a broad range of real-world applications, has received much attention in both academia and industry. Enterprises aspire to exploit more valuable features of the same users from diverse departments to boost their model prediction skills. VFL addresses this demand and concurrently secures individual parties from exposing their raw data. However, conventional VFL encounters a bottleneck as it only leverages aligned samples, whose size shrinks with more parties involved, resulting in data scarcity and the waste of unaligned data. To address this problem, we propose a novel VFL Hybrid Local Pre-training (VFLHLP) approach. VFLHLP first pre-trains local networks on the local data of participating parties. Then it utilizes these pre-trained networks to adjust the sub-model for the labeled party or enhance representation learning for other parties during downstream federated learning on aligned data, boosting the performance of federated models. The experimental results on real-world advertising datasets, demonstrate that our approach achieves the best performance over baseline methods by large margins. The ablation study further illustrates the contribution of each technique in VFLHLP to its overall performance.
BlockEcho: Retaining Long-Range Dependencies for Imputing Block-Wise Missing Data
Feb 29, 2024Block-wise missing data poses significant challenges in real-world data imputation tasks. Compared to scattered missing data, block-wise gaps exacerbate adverse effects on subsequent analytic and machine learning tasks, as the lack of local neighboring elements significantly reduces the interpolation capability and predictive power. However, this issue has not received adequate attention. Most SOTA matrix completion methods appeared less effective, primarily due to overreliance on neighboring elements for predictions. We systematically analyze the issue and propose a novel matrix completion method ``BlockEcho" for a more comprehensive solution. This method creatively integrates Matrix Factorization (MF) within Generative Adversarial Networks (GAN) to explicitly retain long-distance inter-element relationships in the original matrix. Besides, we incorporate an additional discriminator for GAN, comparing the generator's intermediate progress with pre-trained MF results to constrain high-order feature distributions. Subsequently, we evaluate BlockEcho on public datasets across three domains. Results demonstrate superior performance over both traditional and SOTA methods when imputing block-wise missing data, especially at higher missing rates. The advantage also holds for scattered missing data at high missing rates. We also contribute on the analyses in providing theoretical justification on the optimality and convergence of fusing MF and GAN for missing block data.
Enhancing the "Immunity" of Mixture-of-Experts Networks for Adversarial Defense
Feb 29, 2024



Recent studies have revealed the vulnerability of Deep Neural Networks (DNNs) to adversarial examples, which can easily fool DNNs into making incorrect predictions. To mitigate this deficiency, we propose a novel adversarial defense method called "Immunity" (Innovative MoE with MUtual information \& positioN stabilITY) based on a modified Mixture-of-Experts (MoE) architecture in this work. The key enhancements to the standard MoE are two-fold: 1) integrating of Random Switch Gates (RSGs) to obtain diverse network structures via random permutation of RSG parameters at evaluation time, despite of RSGs being determined after one-time training; 2) devising innovative Mutual Information (MI)-based and Position Stability-based loss functions by capitalizing on Grad-CAM's explanatory power to increase the diversity and the causality of expert networks. Notably, our MI-based loss operates directly on the heatmaps, thereby inducing subtler negative impacts on the classification performance when compared to other losses of the same type, theoretically. Extensive evaluation validates the efficacy of the proposed approach in improving adversarial robustness against a wide range of attacks.