 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAREAL-DTA: Dynamic Tree Attention for Efficient Reinforcement Learning of Large Language Models
Jan 31, 2026Reinforcement learning (RL) based post-training for large language models (LLMs) is computationally expensive, as it generates many rollout sequences that could frequently share long token prefixes. Existing RL frameworks usually process these sequences independently, repeatedly recomputing identical prefixes during forward and backward passes during policy model training, leading to substantial inefficiencies in computation and memory usage. Although prefix sharing naturally induces a tree structure over rollouts, prior tree-attention-based solutions rely on fully materialized attention masks and scale poorly in RL settings. In this paper, we introduce AREAL-DTA to efficiently exploit prefix sharing in RL training. AREAL-DTA employs a depth-first-search (DFS)-based execution strategy that dynamically traverses the rollout prefix tree during both forward and backward computation, materializing only a single root-to-leaf path at a time. To further improve scalability, AREAL-DTA incorporates a load-balanced distributed batching mechanism that dynamically constructs and processes prefix trees across multiple GPUs. Across the popular RL post-training workload, AREAL-DTA achieves up to $8.31\times$ in $τ^2$-bench higher training throughput.
LitVISTA: A Benchmark for Narrative Orchestration in Literary Text
Jan 10, 2026Computational narrative analysis aims to capture rhythm, tension, and emotional dynamics in literary texts. Existing large language models can generate long stories but overly focus on causal coherence, neglecting the complex story arcs and orchestration inherent in human narratives. This creates a structural misalignment between model- and human-generated narratives. We propose VISTA Space, a high-dimensional representational framework for narrative orchestration that unifies human and model narrative perspectives. We further introduce LitVISTA, a structurally annotated benchmark grounded in literary texts, enabling systematic evaluation of models' narrative orchestration capabilities. We conduct oracle evaluations on a diverse selection of frontier LLMs, including GPT, Claude, Grok, and Gemini. Results reveal systematic deficiencies: existing models fail to construct a unified global narrative view, struggling to jointly capture narrative function and structure. Furthermore, even advanced thinking modes yield only limited gains for such literary narrative understanding.
M4Human: A Large-Scale Multimodal mmWave Radar Benchmark for Human Mesh Reconstruction
Dec 17, 2025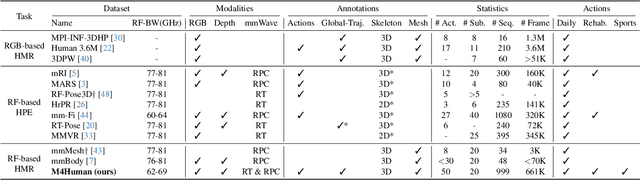
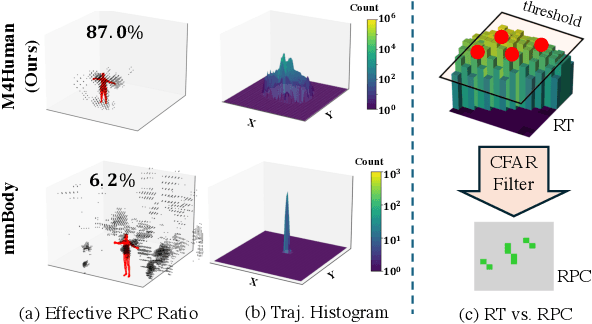

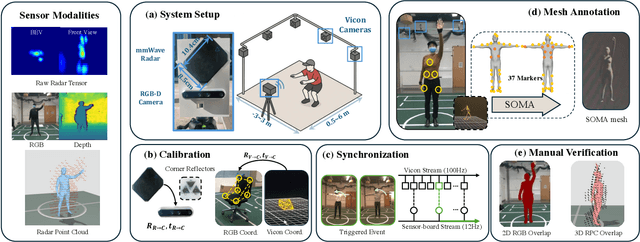
Human mesh reconstruction (HMR) provides direct insights into body-environment interaction, which enables various immersive applications. While existing large-scale HMR datasets rely heavily on line-of-sight RGB input, vision-based sensing is limited by occlusion, lighting variation, and privacy concerns. To overcome these limitations, recent efforts have explored radio-frequency (RF) mmWave radar for privacy-preserving indoor human sensing. However, current radar datasets are constrained by sparse skeleton labels, limited scale, and simple in-place actions. To advance the HMR research community, we introduce M4Human, the current largest-scale (661K-frame) ($9\times$ prior largest) multimodal benchmark, featuring high-resolution mmWave radar, RGB, and depth data. M4Human provides both raw radar tensors (RT) and processed radar point clouds (RPC) to enable research across different levels of RF signal granularity. M4Human includes high-quality motion capture (MoCap) annotations with 3D meshes and global trajectories, and spans 20 subjects and 50 diverse actions, including in-place, sit-in-place, and free-space sports or rehabilitation movements. We establish benchmarks on both RT and RPC modalities, as well as multimodal fusion with RGB-D modalities. Extensive results highlight the significance of M4Human for radar-based human modeling while revealing persistent challenges under fast, unconstrained motion. The dataset and code will be released after the paper publication.
VP-AutoTest: A Virtual-Physical Fusion Autonomous Driving Testing Platform
Dec 08, 2025The rapid development of autonomous vehicles has led to a surge in testing demand. Traditional testing methods, such as virtual simulation, closed-course, and public road testing, face several challenges, including unrealistic vehicle states, limited testing capabilities, and high costs. These issues have prompted increasing interest in virtual-physical fusion testing. However, despite its potential, virtual-physical fusion testing still faces challenges, such as limited element types, narrow testing scope, and fixed evaluation metrics. To address these challenges, we propose the Virtual-Physical Testing Platform for Autonomous Vehicles (VP-AutoTest), which integrates over ten types of virtual and physical elements, including vehicles, pedestrians, and roadside infrastructure, to replicate the diversity of real-world traffic participants. The platform also supports both single-vehicle interaction and multi-vehicle cooperation testing, employing adversarial testing and parallel deduction to accelerate fault detection and explore algorithmic limits, while OBU and Redis communication enable seamless vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) cooperation across all levels of cooperative automation. Furthermore, VP-AutoTest incorporates a multidimensional evaluation framework and AI-driven expert systems to conduct comprehensive performance assessment and defect diagnosis. Finally, by comparing virtual-physical fusion test results with real-world experiments, the platform performs credibility self-evaluation to ensure both the fidelity and efficiency of autonomous driving testing. Please refer to the website for the full testing functionalities on the autonomous driving public service platform OnSite:https://www.onsite.com.cn.
MonkeyOCR v1.5 Technical Report: Unlocking Robust Document Parsing for Complex Patterns
Nov 16, 2025Document parsing is a core task in document intelligence, supporting applications such as information extraction, retrieval-augmented generation, and automated document analysis. However, real-world documents often feature complex layouts with multi-level tables, embedded images or formulas, and cross-page structures, which remain challenging for existing OCR systems. We introduce MonkeyOCR v1.5, a unified vision-language framework that enhances both layout understanding and content recognition through a two-stage pipeline. The first stage employs a large multimodal model to jointly predict layout and reading order, leveraging visual information to ensure sequential consistency. The second stage performs localized recognition of text, formulas, and tables within detected regions, maintaining high visual fidelity while reducing error propagation. To address complex table structures, we propose a visual consistency-based reinforcement learning scheme that evaluates recognition quality via render-and-compare alignment, improving structural accuracy without manual annotations. Additionally, two specialized modules, Image-Decoupled Table Parsing and Type-Guided Table Merging, are introduced to enable reliable parsing of tables containing embedded images and reconstruction of tables crossing pages or columns. Comprehensive experiments on OmniDocBench v1.5 demonstrate that MonkeyOCR v1.5 achieves state-of-the-art performance, outperforming PPOCR-VL and MinerU 2.5 while showing exceptional robustness in visually complex document scenarios. A trial link can be found at https://github.com/Yuliang-Liu/MonkeyOCR .
MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm
Jun 05, 2025We introduce MonkeyOCR, a vision-language model for document parsing that advances the state of the art by leveraging a Structure-Recognition-Relation (SRR) triplet paradigm. This design simplifies what would otherwise be a complex multi-tool pipeline (as in MinerU's modular approach) and avoids the inefficiencies of processing full pages with giant end-to-end models (e.g., large multimodal LLMs like Qwen-VL). In SRR, document parsing is abstracted into three fundamental questions - "Where is it?" (structure), "What is it?" (recognition), and "How is it organized?" (relation) - corresponding to layout analysis, content identification, and logical ordering. This focused decomposition balances accuracy and speed: it enables efficient, scalable processing without sacrificing precision. To train and evaluate this approach, we introduce the MonkeyDoc (the most comprehensive document parsing dataset to date), with 3.9 million instances spanning over ten document types in both Chinese and English. Experiments show that MonkeyOCR outperforms MinerU by an average of 5.1%, with particularly notable improvements on challenging content such as formulas (+15.0%) and tables (+8.6%). Remarkably, our 3B-parameter model surpasses much larger and top-performing models, including Qwen2.5-VL (72B) and Gemini 2.5 Pro, achieving state-of-the-art average performance on English document parsing tasks. In addition, MonkeyOCR processes multi-page documents significantly faster (0.84 pages per second compared to 0.65 for MinerU and 0.12 for Qwen2.5-VL-7B). The 3B model can be efficiently deployed for inference on a single NVIDIA 3090 GPU. Code and models will be released at https://github.com/Yuliang-Liu/MonkeyOCR.
Reactive Aerobatic Flight via Reinforcement Learning
May 30, 2025Quadrotors have demonstrated remarkable versatility, yet their full aerobatic potential remains largely untapped due to inherent underactuation and the complexity of aggressive maneuvers. Traditional approaches, separating trajectory optimization and tracking control, suffer from tracking inaccuracies, computational latency, and sensitivity to initial conditions, limiting their effectiveness in dynamic, high-agility scenarios. Inspired by recent breakthroughs in data-driven methods, we propose a reinforcement learning-based framework that directly maps drone states and aerobatic intentions to control commands, eliminating modular separation to enable quadrotors to perform end-to-end policy optimization for extreme aerobatic maneuvers. To ensure efficient and stable training, we introduce an automated curriculum learning strategy that dynamically adjusts aerobatic task difficulty. Enabled by domain randomization for robust zero-shot sim-to-real transfer, our approach is validated in demanding real-world experiments, including the first demonstration of a drone autonomously performing continuous inverted flight while reactively navigating a moving gate, showcasing unprecedented agility.
Query Routing for Retrieval-Augmented Language Models
May 29, 2025Retrieval-Augmented Generation (RAG) significantly improves the performance of Large Language Models (LLMs) on knowledge-intensive tasks. However, varying response quality across LLMs under RAG necessitates intelligent routing mechanisms, which select the most suitable model for each query from multiple retrieval-augmented LLMs via a dedicated router model. We observe that external documents dynamically affect LLMs' ability to answer queries, while existing routing methods, which rely on static parametric knowledge representations, exhibit suboptimal performance in RAG scenarios. To address this, we formally define the new retrieval-augmented LLM routing problem, incorporating the influence of retrieved documents into the routing framework. We propose RAGRouter, a RAG-aware routing design, which leverages document embeddings and RAG capability embeddings with contrastive learning to capture knowledge representation shifts and enable informed routing decisions. Extensive experiments on diverse knowledge-intensive tasks and retrieval settings show that RAGRouter outperforms the best individual LLM by 3.61% on average and existing routing methods by 3.29%-9.33%. With an extended score-threshold-based mechanism, it also achieves strong performance-efficiency trade-offs under low-latency constraints.
RF4D:Neural Radar Fields for Novel View Synthesis in Outdoor Dynamic Scenes
May 27, 2025Neural fields (NFs) have demonstrated remarkable performance in scene reconstruction, powering various tasks such as novel view synthesis. However, existing NF methods relying on RGB or LiDAR inputs often exhibit severe fragility to adverse weather, particularly when applied in outdoor scenarios like autonomous driving. In contrast, millimeter-wave radar is inherently robust to environmental changes, while unfortunately, its integration with NFs remains largely underexplored. Besides, as outdoor driving scenarios frequently involve moving objects, making spatiotemporal modeling essential for temporally consistent novel view synthesis. To this end, we introduce RF4D, a radar-based neural field framework specifically designed for novel view synthesis in outdoor dynamic scenes. RF4D explicitly incorporates temporal information into its representation, significantly enhancing its capability to model moving objects. We further introduce a feature-level flow module that predicts latent temporal offsets between adjacent frames, enforcing temporal coherence in dynamic scene modeling. Moreover, we propose a radar-specific power rendering formulation closely aligned with radar sensing physics, improving synthesis accuracy and interoperability. Extensive experiments on public radar datasets demonstrate the superior performance of RF4D in terms of radar measurement synthesis quality and occupancy estimation accuracy, achieving especially pronounced improvements in dynamic outdoor scenarios.
Can Large Multimodal Models Understand Agricultural Scenes? Benchmarking with AgroMind
May 18, 2025Large Multimodal Models (LMMs) has demonstrated capabilities across various domains, but comprehensive benchmarks for agricultural remote sensing (RS) remain scarce. Existing benchmarks designed for agricultural RS scenarios exhibit notable limitations, primarily in terms of insufficient scene diversity in the dataset and oversimplified task design. To bridge this gap, we introduce AgroMind, a comprehensive agricultural remote sensing benchmark covering four task dimensions: spatial perception, object understanding, scene understanding, and scene reasoning, with a total of 13 task types, ranging from crop identification and health monitoring to environmental analysis. We curate a high-quality evaluation set by integrating eight public datasets and one private farmland plot dataset, containing 25,026 QA pairs and 15,556 images. The pipeline begins with multi-source data preprocessing, including collection, format standardization, and annotation refinement. We then generate a diverse set of agriculturally relevant questions through the systematic definition of tasks. Finally, we employ LMMs for inference, generating responses, and performing detailed examinations. We evaluated 18 open-source LMMs and 3 closed-source models on AgroMind. Experiments reveal significant performance gaps, particularly in spatial reasoning and fine-grained recognition, it is notable that human performance lags behind several leading LMMs. By establishing a standardized evaluation framework for agricultural RS, AgroMind reveals the limitations of LMMs in domain knowledge and highlights critical challenges for future work. Data and code can be accessed at https://rssysu.github.io/AgroMind/.