 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIAFormer: Voxel-Image Alignment Transformer for High-Fidelity Voxel Refinement
Jan 21, 2026We propose VIAFormer, a Voxel-Image Alignment Transformer model designed for Multi-view Conditioned Voxel Refinement--the task of repairing incomplete noisy voxels using calibrated multi-view images as guidance. Its effectiveness stems from a synergistic design: an Image Index that provides explicit 3D spatial grounding for 2D image tokens, a Correctional Flow objective that learns a direct voxel-refinement trajectory, and a Hybrid Stream Transformer that enables robust cross-modal fusion. Experiments show that VIAFormer establishes a new state of the art in correcting both severe synthetic corruptions and realistic artifacts on the voxel shape obtained from powerful Vision Foundation Models. Beyond benchmarking, we demonstrate VIAFormer as a practical and reliable bridge in real-world 3D creation pipelines, paving the way for voxel-based methods to thrive in large-model, big-data wave.
Transfer Learning for Paediatric Sleep Apnoea Detection Using Physiology-Guided Acoustic Models
Sep 18, 2025Paediatric obstructive sleep apnoea (OSA) is clinically significant yet difficult to diagnose, as children poorly tolerate sensor-based polysomnography. Acoustic monitoring provides a non-invasive alternative for home-based OSA screening, but limited paediatric data hinders the development of robust deep learning approaches. This paper proposes a transfer learning framework that adapts acoustic models pretrained on adult sleep data to paediatric OSA detection, incorporating SpO2-based desaturation patterns to enhance model training. Using a large adult sleep dataset (157 nights) and a smaller paediatric dataset (15 nights), we systematically evaluate (i) single- versus multi-task learning, (ii) encoder freezing versus full fine-tuning, and (iii) the impact of delaying SpO2 labels to better align them with the acoustics and capture physiologically meaningful features. Results show that fine-tuning with SpO2 integration consistently improves paediatric OSA detection compared with baseline models without adaptation. These findings demonstrate the feasibility of transfer learning for home-based OSA screening in children and offer its potential clinical value for early diagnosis.
Estimating Respiratory Effort from Nocturnal Breathing Sounds for Obstructive Sleep Apnoea Screening
Sep 18, 2025



Obstructive sleep apnoea (OSA) is a prevalent condition with significant health consequences, yet many patients remain undiagnosed due to the complexity and cost of over-night polysomnography. Acoustic-based screening provides a scalable alternative, yet performance is limited by environmental noise and the lack of physiological context. Respiratory effort is a key signal used in clinical scoring of OSA events, but current approaches require additional contact sensors that reduce scalability and patient comfort. This paper presents the first study to estimate respiratory effort directly from nocturnal audio, enabling physiological context to be recovered from sound alone. We propose a latent-space fusion framework that integrates the estimated effort embeddings with acoustic features for OSA detection. Using a dataset of 157 nights from 103 participants recorded in home environments, our respiratory effort estimator achieves a concordance correlation coefficient of 0.48, capturing meaningful respiratory dynamics. Fusing effort and audio improves sensitivity and AUC over audio-only baselines, especially at low apnoea-hypopnoea index thresholds. The proposed approach requires only smartphone audio at test time, which enables sensor-free, scalable, and longitudinal OSA monitoring.
Query Routing for Retrieval-Augmented Language Models
May 29, 2025Retrieval-Augmented Generation (RAG) significantly improves the performance of Large Language Models (LLMs) on knowledge-intensive tasks. However, varying response quality across LLMs under RAG necessitates intelligent routing mechanisms, which select the most suitable model for each query from multiple retrieval-augmented LLMs via a dedicated router model. We observe that external documents dynamically affect LLMs' ability to answer queries, while existing routing methods, which rely on static parametric knowledge representations, exhibit suboptimal performance in RAG scenarios. To address this, we formally define the new retrieval-augmented LLM routing problem, incorporating the influence of retrieved documents into the routing framework. We propose RAGRouter, a RAG-aware routing design, which leverages document embeddings and RAG capability embeddings with contrastive learning to capture knowledge representation shifts and enable informed routing decisions. Extensive experiments on diverse knowledge-intensive tasks and retrieval settings show that RAGRouter outperforms the best individual LLM by 3.61% on average and existing routing methods by 3.29%-9.33%. With an extended score-threshold-based mechanism, it also achieves strong performance-efficiency trade-offs under low-latency constraints.
Automated Privacy Information Annotation in Large Language Model Interactions
May 27, 2025Users interacting with large language models (LLMs) under their real identifiers often unknowingly risk disclosing private information. Automatically notifying users whether their queries leak privacy and which phrases leak what private information has therefore become a practical need. Existing privacy detection methods, however, were designed for different objectives and application scenarios, typically tagging personally identifiable information (PII) in anonymous content. In this work, to support the development and evaluation of privacy detection models for LLM interactions that are deployable on local user devices, we construct a large-scale multilingual dataset with 249K user queries and 154K annotated privacy phrases. In particular, we build an automated privacy annotation pipeline with cloud-based strong LLMs to automatically extract privacy phrases from dialogue datasets and annotate leaked information. We also design evaluation metrics at the levels of privacy leakage, extracted privacy phrase, and privacy information. We further establish baseline methods using light-weight LLMs with both tuning-free and tuning-based methods, and report a comprehensive evaluation of their performance. Evaluation results reveal a gap between current performance and the requirements of real-world LLM applications, motivating future research into more effective local privacy detection methods grounded in our dataset.
Collaborative Learning of On-Device Small Model and Cloud-Based Large Model: Advances and Future Directions
Apr 17, 2025The conventional cloud-based large model learning framework is increasingly constrained by latency, cost, personalization, and privacy concerns. In this survey, we explore an emerging paradigm: collaborative learning between on-device small model and cloud-based large model, which promises low-latency, cost-efficient, and personalized intelligent services while preserving user privacy. We provide a comprehensive review across hardware, system, algorithm, and application layers. At each layer, we summarize key problems and recent advances from both academia and industry. In particular, we categorize collaboration algorithms into data-based, feature-based, and parameter-based frameworks. We also review publicly available datasets and evaluation metrics with user-level or device-level consideration tailored to collaborative learning settings. We further highlight real-world deployments, ranging from recommender systems and mobile livestreaming to personal intelligent assistants. We finally point out open research directions to guide future development in this rapidly evolving field.
Personalized Language Model Learning on Text Data Without User Identifiers
Jan 10, 2025



In many practical natural language applications, user data are highly sensitive, requiring anonymous uploads of text data from mobile devices to the cloud without user identifiers. However, the absence of user identifiers restricts the ability of cloud-based language models to provide personalized services, which are essential for catering to diverse user needs. The trivial method of replacing an explicit user identifier with a static user embedding as model input still compromises data anonymization. In this work, we propose to let each mobile device maintain a user-specific distribution to dynamically generate user embeddings, thereby breaking the one-to-one mapping between an embedding and a specific user. We further theoretically demonstrate that to prevent the cloud from tracking users via uploaded embeddings, the local distributions of different users should either be derived from a linearly dependent space to avoid identifiability or be close to each other to prevent accurate attribution. Evaluation on both public and industrial datasets using different language models reveals a remarkable improvement in accuracy from incorporating anonymous user embeddings, while preserving real-time inference requirement.
Personalized LLM for Generating Customized Responses to the Same Query from Different Users
Dec 16, 2024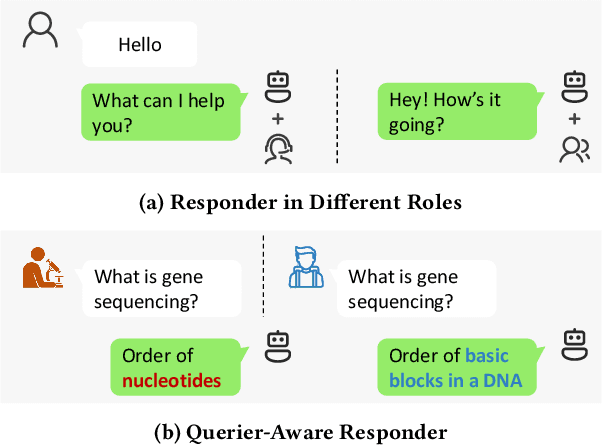
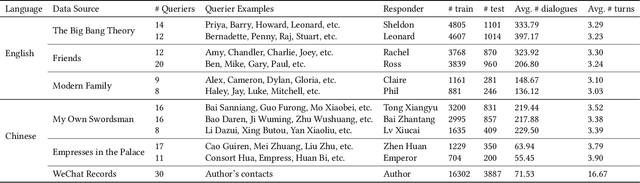
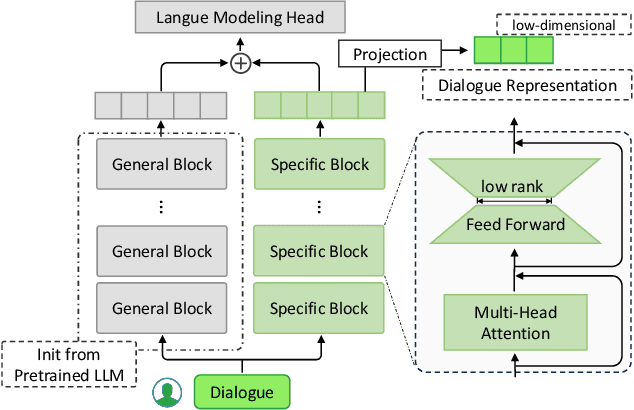
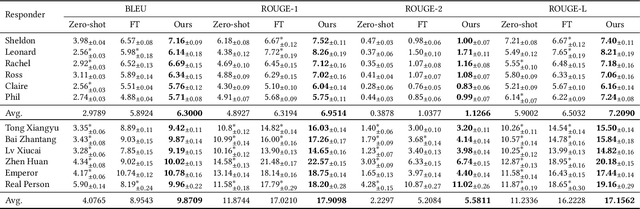
Existing work on large language model (LLM) personalization assigned different responding roles to LLM, but overlooked the diversity of questioners. In this work, we propose a new form of questioner-aware LLM personalization, generating different responses even for the same query from different questioners. We design a dual-tower model architecture with a cross-questioner general encoder and a questioner-specific encoder. We further apply contrastive learning with multi-view augmentation, pulling close the dialogue representations of the same questioner, while pulling apart those of different questioners. To mitigate the impact of question diversity on questioner-contrastive learning, we cluster the dialogues based on question similarity and restrict the scope of contrastive learning within each cluster. We also build a multi-questioner dataset from English and Chinese scripts and WeChat records, called MQDialog, containing 173 questioners and 12 responders. Extensive evaluation with different metrics shows a significant improvement in the quality of personalized response generation.
Edge-Cloud Routing for Text-to-Image Model with Token-Level Multi-Metric Prediction
Nov 21, 2024



Large text-to-image models demonstrate impressive generation capabilities; however, their substantial size necessitates expensive cloud servers for deployment. Conversely, light-weight models can be deployed on edge devices at lower cost but often with inferior generation quality for complex user prompts. To strike a balance between performance and cost, we propose a routing framework, called \texttt{RouteT2I}, which dynamically selects either the large cloud model or the light-weight edge model for each user prompt. Since generated image quality is challenging to measure directly, \texttt{RouteT2I} establishes multi-dimensional quality metrics, particularly, by evaluating the similarity between the generated images and both positive and negative texts that describe each specific quality metric. \texttt{RouteT2I} then predicts the expected quality of the generated images by identifying key tokens in the prompt and comparing their impact on the quality. \texttt{RouteT2I} further introduces the Pareto relative superiority to compare the multi-metric quality of the generated images. Based on this comparison and predefined cost constraints, \texttt{RouteT2I} allocates prompts to either the edge or the cloud. Evaluation reveals that \texttt{RouteT2I} significantly reduces the number of requesting large cloud model while maintaining high-quality image generation.
DC-CCL: Device-Cloud Collaborative Controlled Learning for Large Vision Models
Mar 18, 2023Many large vision models have been deployed on the cloud for real-time services. Meanwhile, fresh samples are continuously generated on the served mobile device. How to leverage the device-side samples to improve the cloud-side large model becomes a practical requirement, but falls into the dilemma of no raw sample up-link and no large model down-link. Specifically, the user may opt out of sharing raw samples with the cloud due to the concern of privacy or communication overhead, while the size of some large vision models far exceeds the mobile device's runtime capacity. In this work, we propose a device-cloud collaborative controlled learning framework, called DC-CCL, enabling a cloud-side large vision model that cannot be directly deployed on the mobile device to still benefit from the device-side local samples. In particular, DC-CCL vertically splits the base model into two submodels, one large submodel for learning from the cloud-side samples and the other small submodel for learning from the device-side samples and performing device-cloud knowledge fusion. Nevertheless, on-device training of the small submodel requires the output of the cloud-side large submodel to compute the desired gradients. DC-CCL thus introduces a light-weight model to mimic the large cloud-side submodel with knowledge distillation, which can be offloaded to the mobile device to control its small submodel's optimization direction. Given the decoupling nature of two submodels in collaborative learning, DC-CCL also allows the cloud to take a pre-trained model and the mobile device to take another model with a different backbone architecture.