 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Time Model Adaptation to Heterogeneous Clients: An Intra-Client and Inter-Image Attention Design
Nov 11, 2022The mainstream workflow of image recognition applications is first training one global model on the cloud for a wide range of classes and then serving numerous clients, each with heterogeneous images from a small subset of classes to be recognized. From the cloud-client discrepancies on the range of image classes, the recognition model is desired to have strong adaptiveness, intuitively by concentrating the focus on each individual client's local dynamic class subset, while incurring negligible overhead. In this work, we propose to plug a new intra-client and inter-image attention (ICIIA) module into existing backbone recognition models, requiring only one-time cloud-based training to be client-adaptive. In particular, given a target image from a certain client, ICIIA introduces multi-head self-attention to retrieve relevant images from the client's historical unlabeled images, thereby calibrating the focus and the recognition result. Further considering that ICIIA's overhead is dominated by linear projection, we propose partitioned linear projection with feature shuffling for replacement and allow increasing the number of partitions to dramatically improve efficiency without scarifying too much accuracy. We finally evaluate ICIIA using 3 different recognition tasks with 9 backbone models over 5 representative datasets. Extensive evaluation results demonstrate the effectiveness and efficiency of ICIIA. Specifically, for ImageNet-1K with the backbone models of MobileNetV3-L and Swin-B, ICIIA can improve the testing accuracy to 83.37% (+8.11%) and 88.86% (+5.28%), while adding only 1.62% and 0.02% of FLOPs, respectively.
On-Device Learning with Cloud-Coordinated Data Augmentation for Extreme Model Personalization in Recommender Systems
Jan 24, 2022
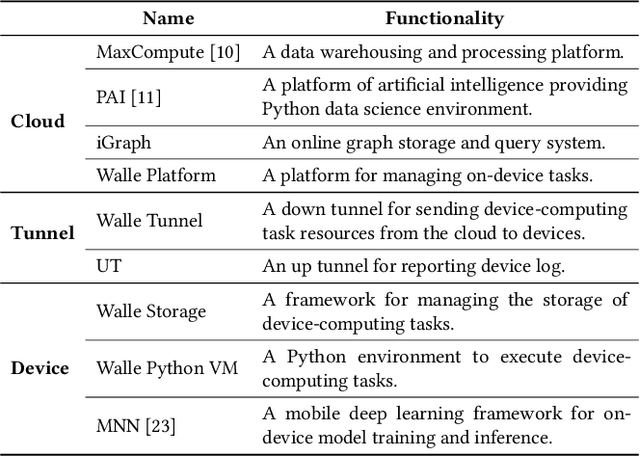

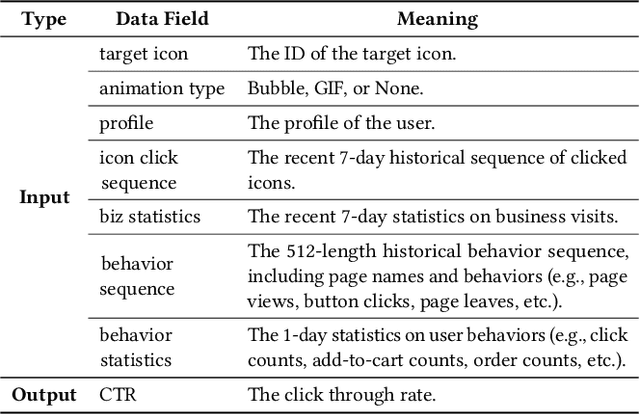
Data heterogeneity is an intrinsic property of recommender systems, making models trained over the global data on the cloud, which is the mainstream in industry, non-optimal to each individual user's local data distribution. To deal with data heterogeneity, model personalization with on-device learning is a potential solution. However, on-device training using a user's small size of local samples will incur severe overfitting and undermine the model's generalization ability. In this work, we propose a new device-cloud collaborative learning framework, called CoDA, to break the dilemmas of purely cloud-based learning and on-device learning. The key principle of CoDA is to retrieve similar samples from the cloud's global pool to augment each user's local dataset to train the recommendation model. Specifically, after a coarse-grained sample matching on the cloud, a personalized sample classifier is further trained on each device for a fine-grained sample filtering, which can learn the boundary between the local data distribution and the outside data distribution. We also build an end-to-end pipeline to support the flows of data, model, computation, and control between the cloud and each device. We have deployed CoDA in a recommendation scenario of Mobile Taobao. Online A/B testing results show the remarkable performance improvement of CoDA over both cloud-based learning without model personalization and on-device training without data augmentation. Overhead testing on a real device demonstrates the computation, storage, and communication efficiency of the on-device tasks in CoDA.
Distributed Optimization over Block-Cyclic Data
Feb 18, 2020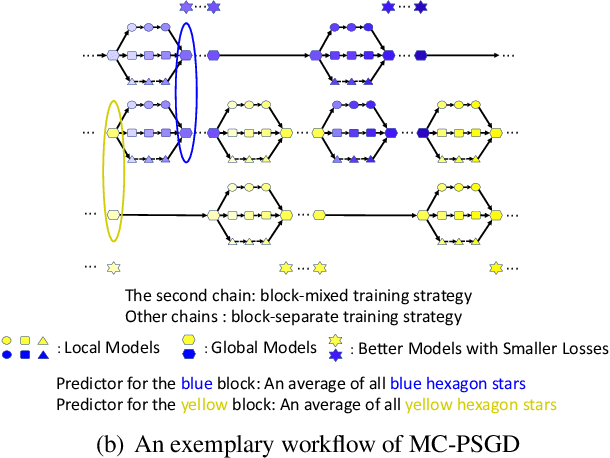
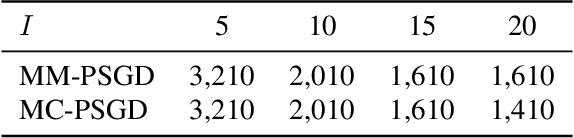
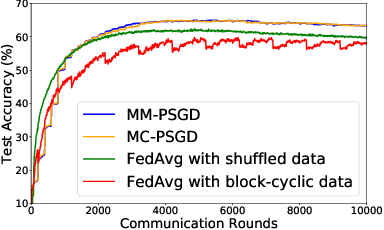
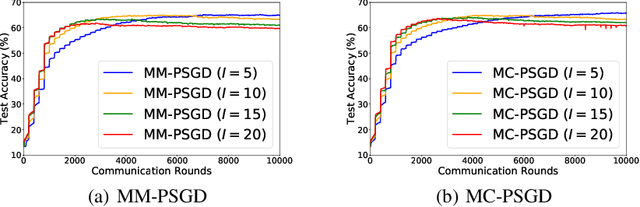
We consider practical data characteristics underlying federated learning, where unbalanced and non-i.i.d. data from clients have a block-cyclic structure: each cycle contains several blocks, and each client's training data follow block-specific and non-i.i.d. distributions. Such a data structure would introduce client and block biases during the collaborative training: the single global model would be biased towards the client or block specific data. To overcome the biases, we propose two new distributed optimization algorithms called multi-model parallel SGD (MM-PSGD) and multi-chain parallel SGD (MC-PSGD) with a convergence rate of $O(1/\sqrt{NT})$, achieving a linear speedup with respect to the total number of clients. In particular, MM-PSGD adopts the block-mixed training strategy, while MC-PSGD further adds the block-separate training strategy. Both algorithms create a specific predictor for each block by averaging and comparing the historical global models generated in this block from different cycles. We extensively evaluate our algorithms over the CIFAR-10 dataset. Evaluation results demonstrate that our algorithms significantly outperform the conventional federated averaging algorithm in terms of test accuracy, and also preserve robustness for the variance of critical parameters.
Distributed Non-Convex Optimization with Sublinear Speedup under Intermittent Client Availability
Feb 18, 2020
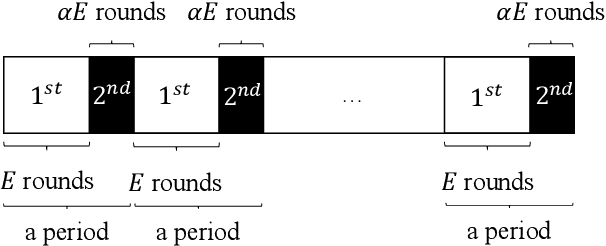
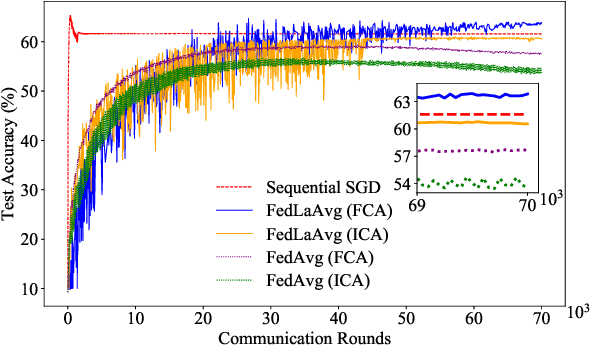

Federated learning is a new distributed machine learning framework, where a bunch of heterogeneous clients collaboratively train a model without sharing training data. In this work, we consider a practical and ubiquitous issue in federated learning: intermittent client availability, where the set of eligible clients may change during the training process. Such an intermittent client availability model would significantly deteriorate the performance of the classical Federated Averaging algorithm (FedAvg for short). We propose a simple distributed non-convex optimization algorithm, called Federated Latest Averaging (FedLaAvg for short), which leverages the latest gradients of all clients, even when the clients are not available, to jointly update the global model in each iteration. Our theoretical analysis shows that FedLaAvg attains the convergence rate of $O(1/(N^{1/4} T^{1/2}))$, achieving a sublinear speedup with respect to the total number of clients. We implement and evaluate FedLaAvg with the CIFAR-10 dataset. The evaluation results demonstrate that FedLaAvg indeed reaches a sublinear speedup and achieves 4.23% higher test accuracy than FedAvg.