 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIAFormer: Voxel-Image Alignment Transformer for High-Fidelity Voxel Refinement
Jan 21, 2026We propose VIAFormer, a Voxel-Image Alignment Transformer model designed for Multi-view Conditioned Voxel Refinement--the task of repairing incomplete noisy voxels using calibrated multi-view images as guidance. Its effectiveness stems from a synergistic design: an Image Index that provides explicit 3D spatial grounding for 2D image tokens, a Correctional Flow objective that learns a direct voxel-refinement trajectory, and a Hybrid Stream Transformer that enables robust cross-modal fusion. Experiments show that VIAFormer establishes a new state of the art in correcting both severe synthetic corruptions and realistic artifacts on the voxel shape obtained from powerful Vision Foundation Models. Beyond benchmarking, we demonstrate VIAFormer as a practical and reliable bridge in real-world 3D creation pipelines, paving the way for voxel-based methods to thrive in large-model, big-data wave.
StableIntrinsic: Detail-preserving One-step Diffusion Model for Multi-view Material Estimation
Aug 27, 2025



Recovering material information from images has been extensively studied in computer graphics and vision. Recent works in material estimation leverage diffusion model showing promising results. However, these diffusion-based methods adopt a multi-step denoising strategy, which is time-consuming for each estimation. Such stochastic inference also conflicts with the deterministic material estimation task, leading to a high variance estimated results. In this paper, we introduce StableIntrinsic, a one-step diffusion model for multi-view material estimation that can produce high-quality material parameters with low variance. To address the overly-smoothing problem in one-step diffusion, StableIntrinsic applies losses in pixel space, with each loss designed based on the properties of the material. Additionally, StableIntrinsic introduces a Detail Injection Network (DIN) to eliminate the detail loss caused by VAE encoding, while further enhancing the sharpness of material prediction results. The experimental results indicate that our method surpasses the current state-of-the-art techniques by achieving a $9.9\%$ improvement in the Peak Signal-to-Noise Ratio (PSNR) of albedo, and by reducing the Mean Square Error (MSE) for metallic and roughness by $44.4\%$ and $60.0\%$, respectively.
DC-CCL: Device-Cloud Collaborative Controlled Learning for Large Vision Models
Mar 18, 2023Many large vision models have been deployed on the cloud for real-time services. Meanwhile, fresh samples are continuously generated on the served mobile device. How to leverage the device-side samples to improve the cloud-side large model becomes a practical requirement, but falls into the dilemma of no raw sample up-link and no large model down-link. Specifically, the user may opt out of sharing raw samples with the cloud due to the concern of privacy or communication overhead, while the size of some large vision models far exceeds the mobile device's runtime capacity. In this work, we propose a device-cloud collaborative controlled learning framework, called DC-CCL, enabling a cloud-side large vision model that cannot be directly deployed on the mobile device to still benefit from the device-side local samples. In particular, DC-CCL vertically splits the base model into two submodels, one large submodel for learning from the cloud-side samples and the other small submodel for learning from the device-side samples and performing device-cloud knowledge fusion. Nevertheless, on-device training of the small submodel requires the output of the cloud-side large submodel to compute the desired gradients. DC-CCL thus introduces a light-weight model to mimic the large cloud-side submodel with knowledge distillation, which can be offloaded to the mobile device to control its small submodel's optimization direction. Given the decoupling nature of two submodels in collaborative learning, DC-CCL also allows the cloud to take a pre-trained model and the mobile device to take another model with a different backbone architecture.
One-Time Model Adaptation to Heterogeneous Clients: An Intra-Client and Inter-Image Attention Design
Nov 11, 2022The mainstream workflow of image recognition applications is first training one global model on the cloud for a wide range of classes and then serving numerous clients, each with heterogeneous images from a small subset of classes to be recognized. From the cloud-client discrepancies on the range of image classes, the recognition model is desired to have strong adaptiveness, intuitively by concentrating the focus on each individual client's local dynamic class subset, while incurring negligible overhead. In this work, we propose to plug a new intra-client and inter-image attention (ICIIA) module into existing backbone recognition models, requiring only one-time cloud-based training to be client-adaptive. In particular, given a target image from a certain client, ICIIA introduces multi-head self-attention to retrieve relevant images from the client's historical unlabeled images, thereby calibrating the focus and the recognition result. Further considering that ICIIA's overhead is dominated by linear projection, we propose partitioned linear projection with feature shuffling for replacement and allow increasing the number of partitions to dramatically improve efficiency without scarifying too much accuracy. We finally evaluate ICIIA using 3 different recognition tasks with 9 backbone models over 5 representative datasets. Extensive evaluation results demonstrate the effectiveness and efficiency of ICIIA. Specifically, for ImageNet-1K with the backbone models of MobileNetV3-L and Swin-B, ICIIA can improve the testing accuracy to 83.37% (+8.11%) and 88.86% (+5.28%), while adding only 1.62% and 0.02% of FLOPs, respectively.
On-Device Learning with Cloud-Coordinated Data Augmentation for Extreme Model Personalization in Recommender Systems
Jan 24, 2022
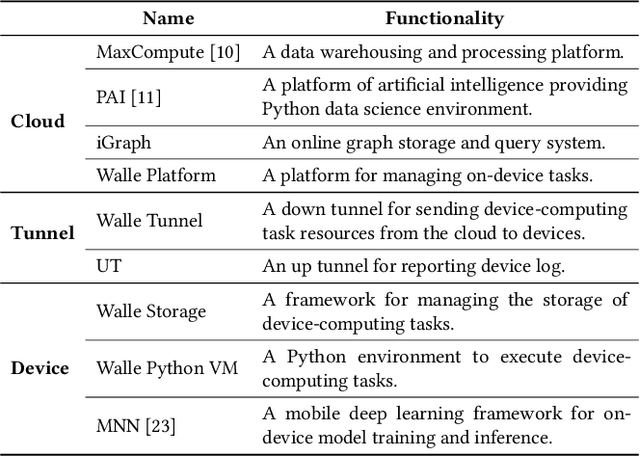

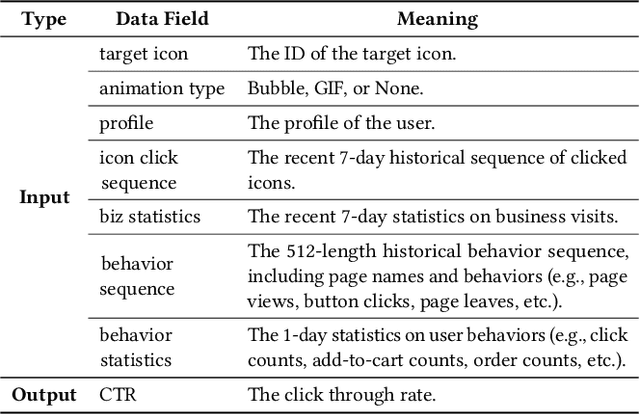
Data heterogeneity is an intrinsic property of recommender systems, making models trained over the global data on the cloud, which is the mainstream in industry, non-optimal to each individual user's local data distribution. To deal with data heterogeneity, model personalization with on-device learning is a potential solution. However, on-device training using a user's small size of local samples will incur severe overfitting and undermine the model's generalization ability. In this work, we propose a new device-cloud collaborative learning framework, called CoDA, to break the dilemmas of purely cloud-based learning and on-device learning. The key principle of CoDA is to retrieve similar samples from the cloud's global pool to augment each user's local dataset to train the recommendation model. Specifically, after a coarse-grained sample matching on the cloud, a personalized sample classifier is further trained on each device for a fine-grained sample filtering, which can learn the boundary between the local data distribution and the outside data distribution. We also build an end-to-end pipeline to support the flows of data, model, computation, and control between the cloud and each device. We have deployed CoDA in a recommendation scenario of Mobile Taobao. Online A/B testing results show the remarkable performance improvement of CoDA over both cloud-based learning without model personalization and on-device training without data augmentation. Overhead testing on a real device demonstrates the computation, storage, and communication efficiency of the on-device tasks in CoDA.