 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device Learning with Cloud-Coordinated Data Augmentation for Extreme Model Personalization in Recommender Systems
Jan 24, 2022
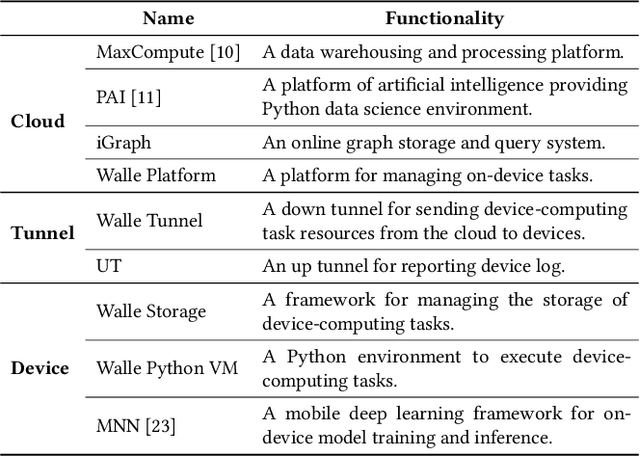

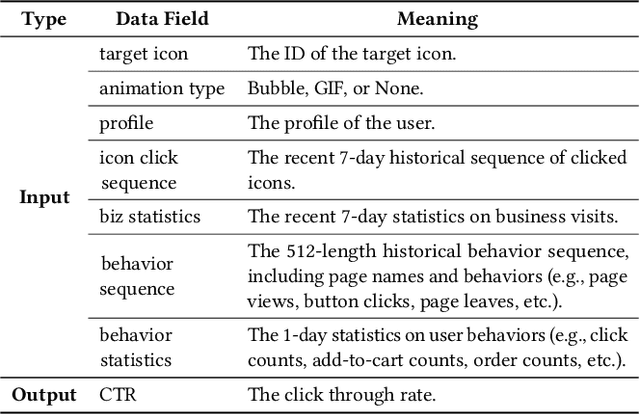
Data heterogeneity is an intrinsic property of recommender systems, making models trained over the global data on the cloud, which is the mainstream in industry, non-optimal to each individual user's local data distribution. To deal with data heterogeneity, model personalization with on-device learning is a potential solution. However, on-device training using a user's small size of local samples will incur severe overfitting and undermine the model's generalization ability. In this work, we propose a new device-cloud collaborative learning framework, called CoDA, to break the dilemmas of purely cloud-based learning and on-device learning. The key principle of CoDA is to retrieve similar samples from the cloud's global pool to augment each user's local dataset to train the recommendation model. Specifically, after a coarse-grained sample matching on the cloud, a personalized sample classifier is further trained on each device for a fine-grained sample filtering, which can learn the boundary between the local data distribution and the outside data distribution. We also build an end-to-end pipeline to support the flows of data, model, computation, and control between the cloud and each device. We have deployed CoDA in a recommendation scenario of Mobile Taobao. Online A/B testing results show the remarkable performance improvement of CoDA over both cloud-based learning without model personalization and on-device training without data augmentation. Overhead testing on a real device demonstrates the computation, storage, and communication efficiency of the on-device tasks in CoDA.