 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCourse-Correction: Safety Alignment Using Synthetic Preferences
Jul 23, 2024
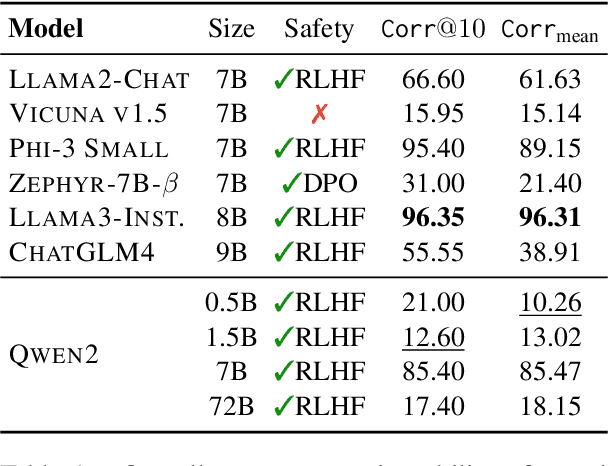

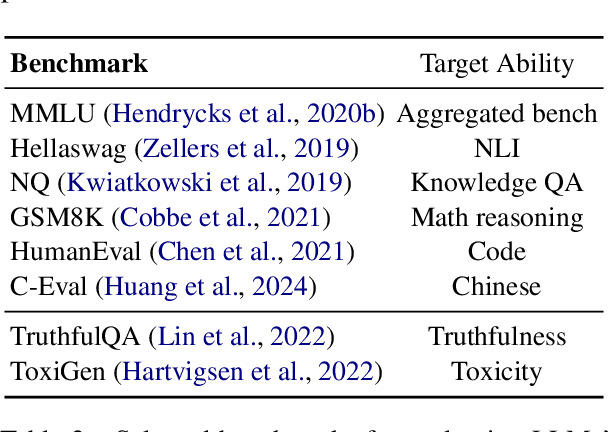
The risk of harmful content generated by large language models (LLMs) becomes a critical concern. This paper presents a systematic study on assessing and improving LLMs' capability to perform the task of \textbf{course-correction}, \ie, the model can steer away from generating harmful content autonomously. To start with, we introduce the \textsc{C$^2$-Eval} benchmark for quantitative assessment and analyze 10 popular LLMs, revealing varying proficiency of current safety-tuned LLMs in course-correction. To improve, we propose fine-tuning LLMs with preference learning, emphasizing the preference for timely course-correction. Using an automated pipeline, we create \textsc{C$^2$-Syn}, a synthetic dataset with 750K pairwise preferences, to teach models the concept of timely course-correction through data-driven preference learning. Experiments on 2 LLMs, \textsc{Llama2-Chat 7B} and \textsc{Qwen2 7B}, show that our method effectively enhances course-correction skills without affecting general performance. Additionally, it effectively improves LLMs' safety, particularly in resisting jailbreak attacks.
Walle: An End-to-End, General-Purpose, and Large-Scale Production System for Device-Cloud Collaborative Machine Learning
May 30, 2022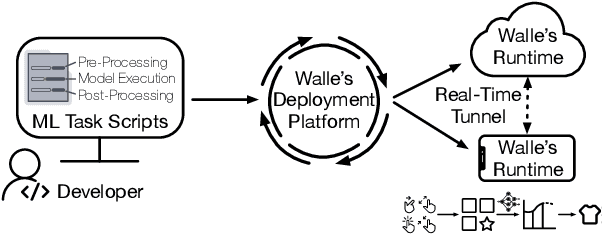
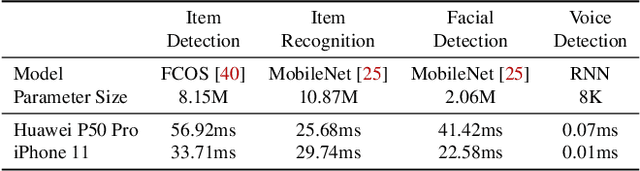
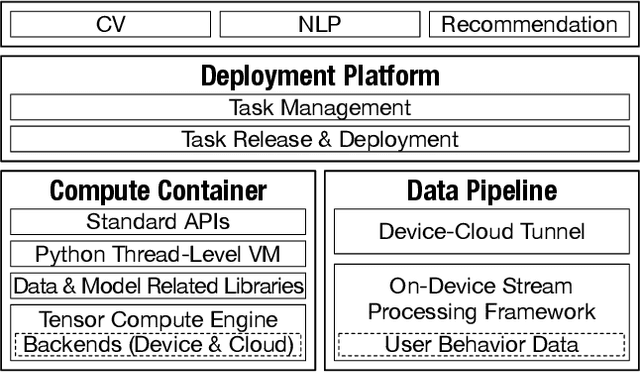

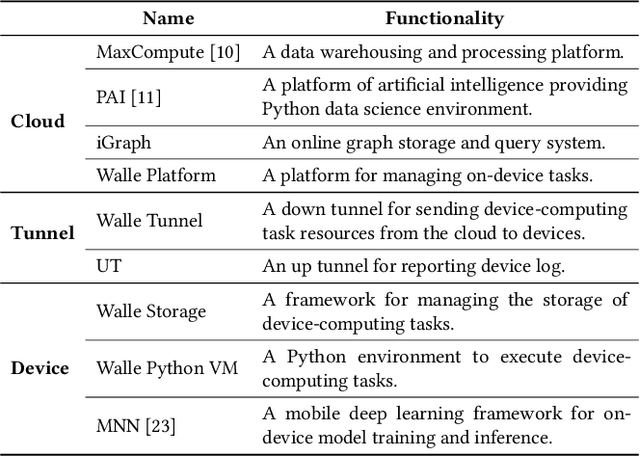
To break the bottlenecks of mainstream cloud-based machine learning (ML) paradigm, we adopt device-cloud collaborative ML and build the first end-to-end and general-purpose system, called Walle, as the foundation. Walle consists of a deployment platform, distributing ML tasks to billion-scale devices in time; a data pipeline, efficiently preparing task input; and a compute container, providing a cross-platform and high-performance execution environment, while facilitating daily task iteration. Specifically, the compute container is based on Mobile Neural Network (MNN), a tensor compute engine along with the data processing and model execution libraries, which are exposed through a refined Python thread-level virtual machine (VM) to support diverse ML tasks and concurrent task execution. The core of MNN is the novel mechanisms of operator decomposition and semi-auto search, sharply reducing the workload in manually optimizing hundreds of operators for tens of hardware backends and further quickly identifying the best backend with runtime optimization for a computation graph. The data pipeline introduces an on-device stream processing framework to enable processing user behavior data at source. The deployment platform releases ML tasks with an efficient push-then-pull method and supports multi-granularity deployment policies. We evaluate Walle in practical e-commerce application scenarios to demonstrate its effectiveness, efficiency, and scalability. Extensive micro-benchmarks also highlight the superior performance of MNN and the Python thread-level VM. Walle has been in large-scale production use in Alibaba, while MNN has been open source with a broad impact in the community.
On-Device Learning with Cloud-Coordinated Data Augmentation for Extreme Model Personalization in Recommender Systems
Jan 24, 2022

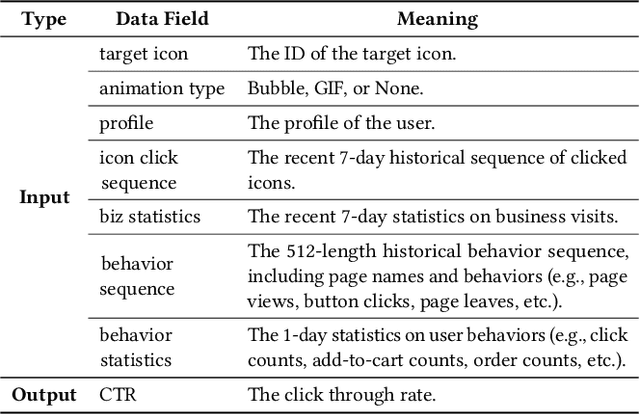
Data heterogeneity is an intrinsic property of recommender systems, making models trained over the global data on the cloud, which is the mainstream in industry, non-optimal to each individual user's local data distribution. To deal with data heterogeneity, model personalization with on-device learning is a potential solution. However, on-device training using a user's small size of local samples will incur severe overfitting and undermine the model's generalization ability. In this work, we propose a new device-cloud collaborative learning framework, called CoDA, to break the dilemmas of purely cloud-based learning and on-device learning. The key principle of CoDA is to retrieve similar samples from the cloud's global pool to augment each user's local dataset to train the recommendation model. Specifically, after a coarse-grained sample matching on the cloud, a personalized sample classifier is further trained on each device for a fine-grained sample filtering, which can learn the boundary between the local data distribution and the outside data distribution. We also build an end-to-end pipeline to support the flows of data, model, computation, and control between the cloud and each device. We have deployed CoDA in a recommendation scenario of Mobile Taobao. Online A/B testing results show the remarkable performance improvement of CoDA over both cloud-based learning without model personalization and on-device training without data augmentation. Overhead testing on a real device demonstrates the computation, storage, and communication efficiency of the on-device tasks in CoDA.
Distributed Machine Learning on Mobile Devices: A Survey
Sep 18, 2019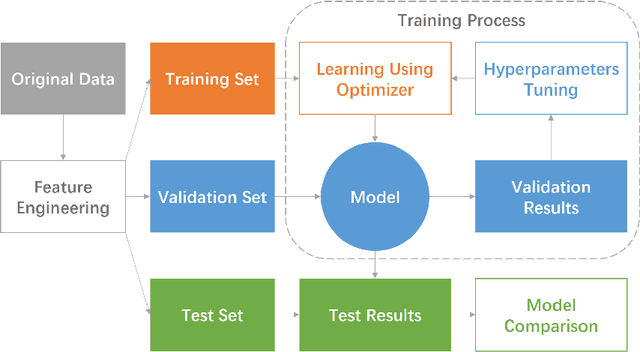
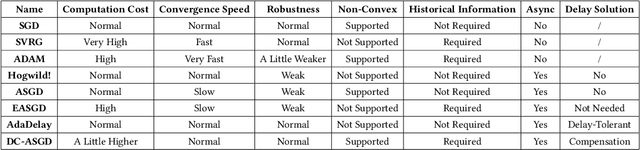

In recent years, mobile devices have gained increasingly development with stronger computation capability and larger storage. Some of the computation-intensive machine learning and deep learning tasks can now be run on mobile devices. To take advantage of the resources available on mobile devices and preserve users' privacy, the idea of mobile distributed machine learning is proposed. It uses local hardware resources and local data to solve machine learning sub-problems on mobile devices, and only uploads computation results instead of original data to contribute to the optimization of the global model. This architecture can not only relieve computation and storage burden on servers, but also protect the users' sensitive information. Another benefit is the bandwidth reduction, as various kinds of local data can now participate in the training process without being uploaded to the server. In this paper, we provide a comprehensive survey on recent studies of mobile distributed machine learning. We survey a number of widely-used mobile distributed machine learning methods. We also present an in-depth discussion on the challenges and future directions in this area. We believe that this survey can demonstrate a clear overview of mobile distributed machine learning and provide guidelines on applying mobile distributed machine learning to real applications.