 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Without Images: Internalizing Visual Manipulation with On-Policy Self-Distillation
Jun 07, 2026''Thinking with Images'' has emerged as an effective paradigm for fine-grained visual reasoning: by explicitly zooming into relevant regions and reasoning over crops, models can access local evidence that is difficult to recover from a single global image. However, this benefit comes with redundant tool invocations and longer inference traces. Moreover, when such behaviors are learned mainly from outcome reward, the resulting intermediate crops or visual cues can be noisy or fail to faithfully capture task-relevant visual evidence. In this work, we ask whether the reasoning benefits of ''Thinking with Images'' can be internalized through Thinking with Imagination: an internal process that decides where to look and imagines what visual cues closer inspection would reveal without actually invoking tools. We propose Imagine-OPD, an on-policy self-distillation framework in which a teacher plays the role of a ''Thinking with Images'' reasoner during training: it receives privileged zoomed evidence views derived from annotated regions, and supervises the model's own imagination reasoning trajectories. Imagine-OPD does not require an external teacher or high-quality imagination demonstrations. Experiments on vision-centric benchmarks show that Imagine-OPD achieves the best average performance among compared models while significantly reducing inference overhead compared with ''Thinking with Images'' methods.
From Player to Master: Enhancing Test-Time Learning of LLM Agents via Reinforcement Learning over Memory
Jun 07, 2026Large language model (LLM) agents are increasingly deployed in long-running settings where improving through experience at test time becomes important. A common approach is to update an explicit memory after each interaction to guide future decisions. However, most existing methods rely on hand-designed prompting rules, making it difficult to align memory updates with downstream objectives over multi-step horizons consistently. We propose MemoPilot, a plug-in memory copilot that explicitly trains the memory update process to improve a frozen LLM's performance across sequential interactions. We formulate memory updating as a multi-turn decision problem and optimize it end-to-end with multi-turn GRPO. Our training recipe introduces (i) a turn-wise reward signal and (ii) a context-independent, turn-level advantage estimation across rollouts, enabling finer-grained credit assignment and more stable training in multi-turn settings. We evaluate MemoPilot on two testbeds: multi-round Rock-Paper-Scissors (RPS) and Limit Texas Hold'em (LHE). Across both environments, MemoPilot substantially improves test-time learning of a frozen player over strong baselines, ranking first in Elo ratings on both games (1762 on LHE and 1590 on RPS) and outperforming all baseline memory methods and proprietary models, including DeepSeek-V3.2.
Vision-DeepResearch Benchmark: Rethinking Visual and Textual Search for Multimodal Large Language Models
Feb 02, 2026Multimodal Large Language Models (MLLMs) have advanced VQA and now support Vision-DeepResearch systems that use search engines for complex visual-textual fact-finding. However, evaluating these visual and textual search abilities is still difficult, and existing benchmarks have two major limitations. First, existing benchmarks are not visual search-centric: answers that should require visual search are often leaked through cross-textual cues in the text questions or can be inferred from the prior world knowledge in current MLLMs. Second, overly idealized evaluation scenario: On the image-search side, the required information can often be obtained via near-exact matching against the full image, while the text-search side is overly direct and insufficiently challenging. To address these issues, we construct the Vision-DeepResearch benchmark (VDR-Bench) comprising 2,000 VQA instances. All questions are created via a careful, multi-stage curation pipeline and rigorous expert review, designed to assess the behavior of Vision-DeepResearch systems under realistic real-world conditions. Moreover, to address the insufficient visual retrieval capabilities of current MLLMs, we propose a simple multi-round cropped-search workflow. This strategy is shown to effectively improve model performance in realistic visual retrieval scenarios. Overall, our results provide practical guidance for the design of future multimodal deep-research systems. The code will be released in https://github.com/Osilly/Vision-DeepResearch.
Conan: Progressive Learning to Reason Like a Detective over Multi-Scale Visual Evidence
Oct 23, 2025Video reasoning, which requires multi-step deduction across frames, remains a major challenge for multimodal large language models (MLLMs). While reinforcement learning (RL)-based methods enhance reasoning capabilities, they often rely on text-only chains that yield ungrounded or hallucinated conclusions. Conversely, frame-retrieval approaches introduce visual grounding but still struggle with inaccurate evidence localization. To address these challenges, we present Conan, a framework for evidence-grounded multi-step video reasoning. Conan identifies contextual and evidence frames, reasons over cross-frame clues, and adaptively decides when to conclude or explore further. To achieve this, we (1) construct Conan-91K, a large-scale dataset of automatically generated reasoning traces that includes frame identification, evidence reasoning, and action decision, and (2) design a multi-stage progressive cold-start strategy combined with an Identification-Reasoning-Action (AIR) RLVR training framework to jointly enhance multi-step visual reasoning. Extensive experiments on six multi-step reasoning benchmarks demonstrate that Conan surpasses the baseline Qwen2.5-VL-7B-Instruct by an average of over 10% in accuracy, achieving state-of-the-art performance. Furthermore, Conan generalizes effectively to long-video understanding tasks, validating its strong scalability and robustness.
RICO: Improving Accuracy and Completeness in Image Recaptioning via Visual Reconstruction
May 28, 2025Image recaptioning is widely used to generate training datasets with enhanced quality for various multimodal tasks. Existing recaptioning methods typically rely on powerful multimodal large language models (MLLMs) to enhance textual descriptions, but often suffer from inaccuracies due to hallucinations and incompleteness caused by missing fine-grained details. To address these limitations, we propose RICO, a novel framework that refines captions through visual reconstruction. Specifically, we leverage a text-to-image model to reconstruct a caption into a reference image, and prompt an MLLM to identify discrepancies between the original and reconstructed images to refine the caption. This process is performed iteratively, further progressively promoting the generation of more faithful and comprehensive descriptions. To mitigate the additional computational cost induced by the iterative process, we introduce RICO-Flash, which learns to generate captions like RICO using DPO. Extensive experiments demonstrate that our approach significantly improves caption accuracy and completeness, outperforms most baselines by approximately 10% on both CapsBench and CompreCap. Code released at https://github.com/wangyuchi369/RICO.
Course-Correction: Safety Alignment Using Synthetic Preferences
Jul 23, 2024
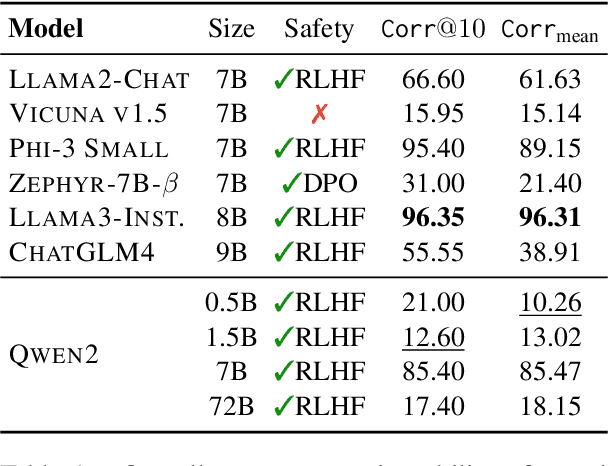

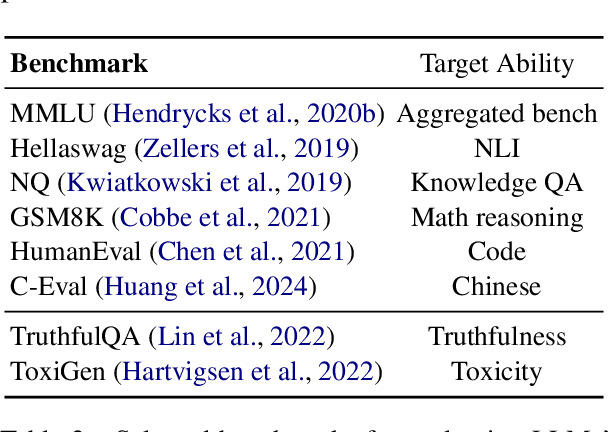
The risk of harmful content generated by large language models (LLMs) becomes a critical concern. This paper presents a systematic study on assessing and improving LLMs' capability to perform the task of \textbf{course-correction}, \ie, the model can steer away from generating harmful content autonomously. To start with, we introduce the \textsc{C$^2$-Eval} benchmark for quantitative assessment and analyze 10 popular LLMs, revealing varying proficiency of current safety-tuned LLMs in course-correction. To improve, we propose fine-tuning LLMs with preference learning, emphasizing the preference for timely course-correction. Using an automated pipeline, we create \textsc{C$^2$-Syn}, a synthetic dataset with 750K pairwise preferences, to teach models the concept of timely course-correction through data-driven preference learning. Experiments on 2 LLMs, \textsc{Llama2-Chat 7B} and \textsc{Qwen2 7B}, show that our method effectively enhances course-correction skills without affecting general performance. Additionally, it effectively improves LLMs' safety, particularly in resisting jailbreak attacks.
Nearest is Not Dearest: Towards Practical Defense against Quantization-conditioned Backdoor Attacks
May 21, 2024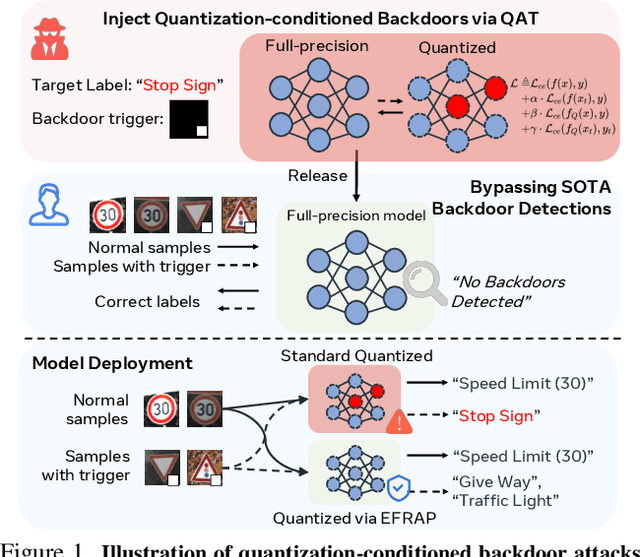
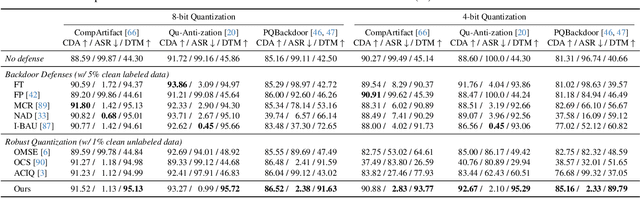
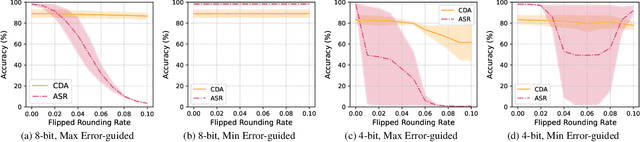
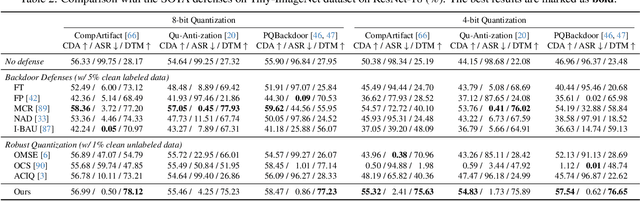
Model quantization is widely used to compress and accelerate deep neural networks. However, recent studies have revealed the feasibility of weaponizing model quantization via implanting quantization-conditioned backdoors (QCBs). These special backdoors stay dormant on released full-precision models but will come into effect after standard quantization. Due to the peculiarity of QCBs, existing defenses have minor effects on reducing their threats or are even infeasible. In this paper, we conduct the first in-depth analysis of QCBs. We reveal that the activation of existing QCBs primarily stems from the nearest rounding operation and is closely related to the norms of neuron-wise truncation errors (i.e., the difference between the continuous full-precision weights and its quantized version). Motivated by these insights, we propose Error-guided Flipped Rounding with Activation Preservation (EFRAP), an effective and practical defense against QCBs. Specifically, EFRAP learns a non-nearest rounding strategy with neuron-wise error norm and layer-wise activation preservation guidance, flipping the rounding strategies of neurons crucial for backdoor effects but with minimal impact on clean accuracy. Extensive evaluations on benchmark datasets demonstrate that our EFRAP can defeat state-of-the-art QCB attacks under various settings. Code is available at https://github.com/AntigoneRandy/QuantBackdoor_EFRAP.