 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Data Auditing in Large Vision-Language Models
Apr 25, 2025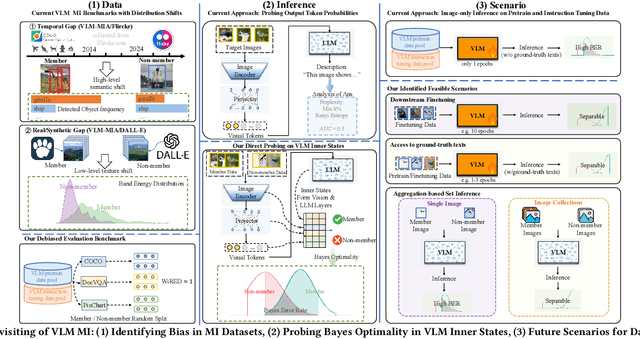
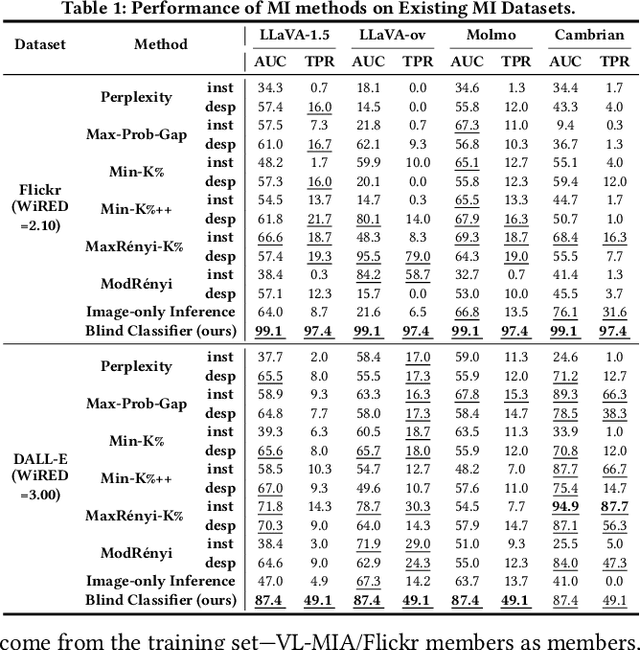
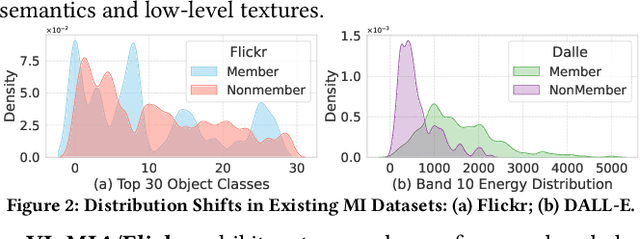
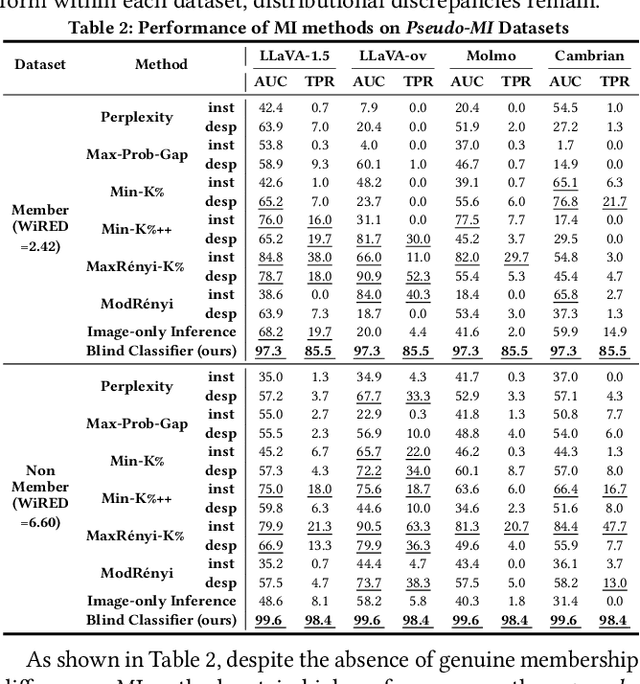
With the surge of large language models (LLMs), Large Vision-Language Models (VLMs)--which integrate vision encoders with LLMs for accurate visual grounding--have shown great potential in tasks like generalist agents and robotic control. However, VLMs are typically trained on massive web-scraped images, raising concerns over copyright infringement and privacy violations, and making data auditing increasingly urgent. Membership inference (MI), which determines whether a sample was used in training, has emerged as a key auditing technique, with promising results on open-source VLMs like LLaVA (AUC > 80%). In this work, we revisit these advances and uncover a critical issue: current MI benchmarks suffer from distribution shifts between member and non-member images, introducing shortcut cues that inflate MI performance. We further analyze the nature of these shifts and propose a principled metric based on optimal transport to quantify the distribution discrepancy. To evaluate MI in realistic settings, we construct new benchmarks with i.i.d. member and non-member images. Existing MI methods fail under these unbiased conditions, performing only marginally better than chance. Further, we explore the theoretical upper bound of MI by probing the Bayes Optimality within the VLM's embedding space and find the irreducible error rate remains high. Despite this pessimistic outlook, we analyze why MI for VLMs is particularly challenging and identify three practical scenarios--fine-tuning, access to ground-truth texts, and set-based inference--where auditing becomes feasible. Our study presents a systematic view of the limits and opportunities of MI for VLMs, providing guidance for future efforts in trustworthy data auditing.
Towards Label-Only Membership Inference Attack against Pre-trained Large Language Models
Feb 26, 2025Membership Inference Attacks (MIAs) aim to predict whether a data sample belongs to the model's training set or not. Although prior research has extensively explored MIAs in Large Language Models (LLMs), they typically require accessing to complete output logits (\ie, \textit{logits-based attacks}), which are usually not available in practice. In this paper, we study the vulnerability of pre-trained LLMs to MIAs in the \textit{label-only setting}, where the adversary can only access generated tokens (text). We first reveal that existing label-only MIAs have minor effects in attacking pre-trained LLMs, although they are highly effective in inferring fine-tuning datasets used for personalized LLMs. We find that their failure stems from two main reasons, including better generalization and overly coarse perturbation. Specifically, due to the extensive pre-training corpora and exposing each sample only a few times, LLMs exhibit minimal robustness differences between members and non-members. This makes token-level perturbations too coarse to capture such differences. To alleviate these problems, we propose \textbf{PETAL}: a label-only membership inference attack based on \textbf{PE}r-\textbf{T}oken sem\textbf{A}ntic simi\textbf{L}arity. Specifically, PETAL leverages token-level semantic similarity to approximate output probabilities and subsequently calculate the perplexity. It finally exposes membership based on the common assumption that members are `better' memorized and have smaller perplexity. We conduct extensive experiments on the WikiMIA benchmark and the more challenging MIMIR benchmark. Empirically, our PETAL performs better than the extensions of existing label-only attacks against personalized LLMs and even on par with other advanced logit-based attacks across all metrics on five prevalent open-source LLMs.
Towards Reliable Verification of Unauthorized Data Usage in Personalized Text-to-Image Diffusion Models
Oct 14, 2024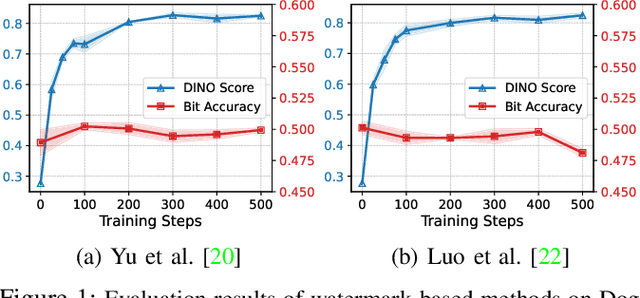


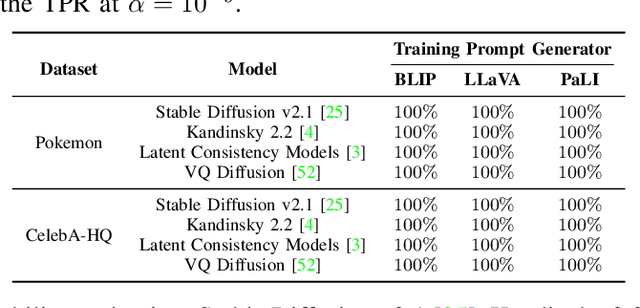
Text-to-image diffusion models are pushing the boundaries of what generative AI can achieve in our lives. Beyond their ability to generate general images, new personalization techniques have been proposed to customize the pre-trained base models for crafting images with specific themes or styles. Such a lightweight solution, enabling AI practitioners and developers to easily build their own personalized models, also poses a new concern regarding whether the personalized models are trained from unauthorized data. A promising solution is to proactively enable data traceability in generative models, where data owners embed external coatings (e.g., image watermarks or backdoor triggers) onto the datasets before releasing. Later the models trained over such datasets will also learn the coatings and unconsciously reproduce them in the generated mimicries, which can be extracted and used as the data usage evidence. However, we identify the existing coatings cannot be effectively learned in personalization tasks, making the corresponding verification less reliable. In this paper, we introduce SIREN, a novel methodology to proactively trace unauthorized data usage in black-box personalized text-to-image diffusion models. Our approach optimizes the coating in a delicate way to be recognized by the model as a feature relevant to the personalization task, thus significantly improving its learnability. We also utilize a human perceptual-aware constraint, a hypersphere classification technique, and a hypothesis-testing-guided verification method to enhance the stealthiness and detection accuracy of the coating. The effectiveness of SIREN is verified through extensive experiments on a diverse set of benchmark datasets, models, and learning algorithms. SIREN is also effective in various real-world scenarios and evaluated against potential countermeasures. Our code is publicly available.
Nearest is Not Dearest: Towards Practical Defense against Quantization-conditioned Backdoor Attacks
May 21, 2024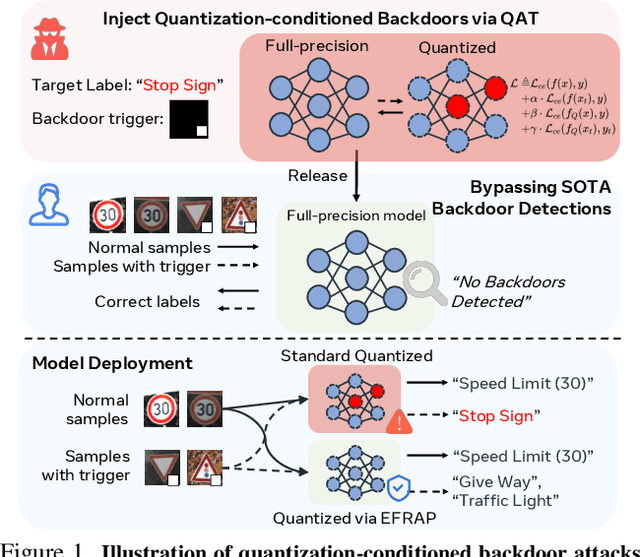
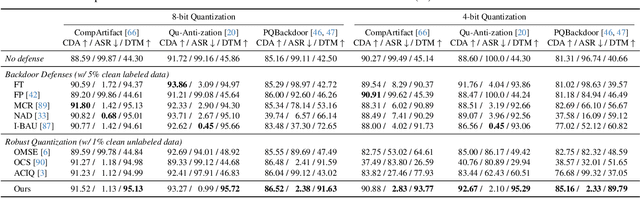
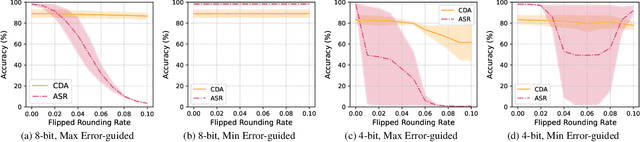
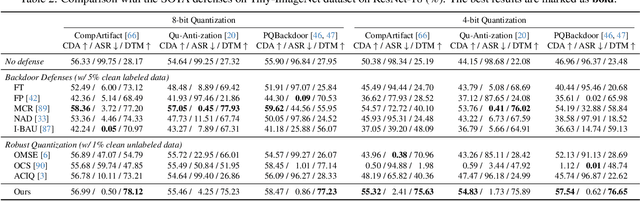
Model quantization is widely used to compress and accelerate deep neural networks. However, recent studies have revealed the feasibility of weaponizing model quantization via implanting quantization-conditioned backdoors (QCBs). These special backdoors stay dormant on released full-precision models but will come into effect after standard quantization. Due to the peculiarity of QCBs, existing defenses have minor effects on reducing their threats or are even infeasible. In this paper, we conduct the first in-depth analysis of QCBs. We reveal that the activation of existing QCBs primarily stems from the nearest rounding operation and is closely related to the norms of neuron-wise truncation errors (i.e., the difference between the continuous full-precision weights and its quantized version). Motivated by these insights, we propose Error-guided Flipped Rounding with Activation Preservation (EFRAP), an effective and practical defense against QCBs. Specifically, EFRAP learns a non-nearest rounding strategy with neuron-wise error norm and layer-wise activation preservation guidance, flipping the rounding strategies of neurons crucial for backdoor effects but with minimal impact on clean accuracy. Extensive evaluations on benchmark datasets demonstrate that our EFRAP can defeat state-of-the-art QCB attacks under various settings. Code is available at https://github.com/AntigoneRandy/QuantBackdoor_EFRAP.
VEnvision3D: A Synthetic Perception Dataset for 3D Multi-Task Model Research
Mar 05, 2024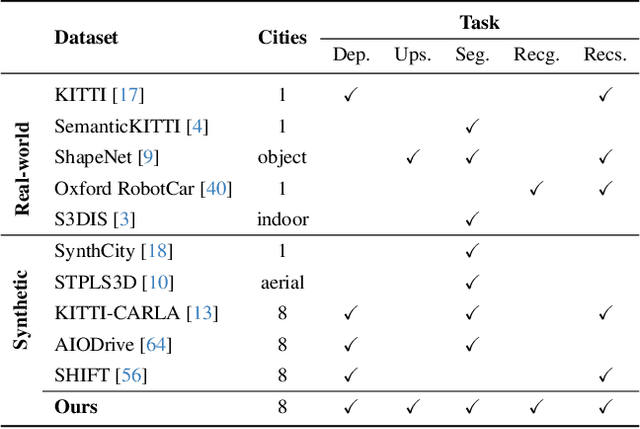
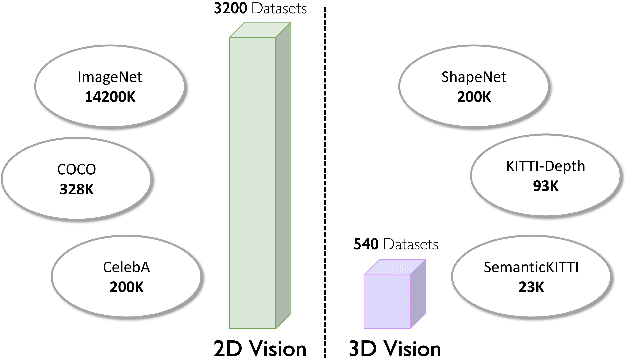


Developing a unified multi-task foundation model has become a critical challenge in computer vision research. In the current field of 3D computer vision, most datasets only focus on single task, which complicates the concurrent training requirements of various downstream tasks. In this paper, we introduce VEnvision3D, a large 3D synthetic perception dataset for multi-task learning, including depth completion, segmentation, upsampling, place recognition, and 3D reconstruction. Since the data for each task is collected in the same environmental domain, sub-tasks are inherently aligned in terms of the utilized data. Therefore, such a unique attribute can assist in exploring the potential for the multi-task model and even the foundation model without separate training methods. Meanwhile, capitalizing on the advantage of virtual environments being freely editable, we implement some novel settings such as simulating temporal changes in the environment and sampling point clouds on model surfaces. These characteristics enable us to present several new benchmarks. We also perform extensive studies on multi-task end-to-end models, revealing new observations, challenges, and opportunities for future research. Our dataset and code will be open-sourced upon acceptance.
What can Discriminator do? Towards Box-free Ownership Verification of Generative Adversarial Network
Jul 29, 2023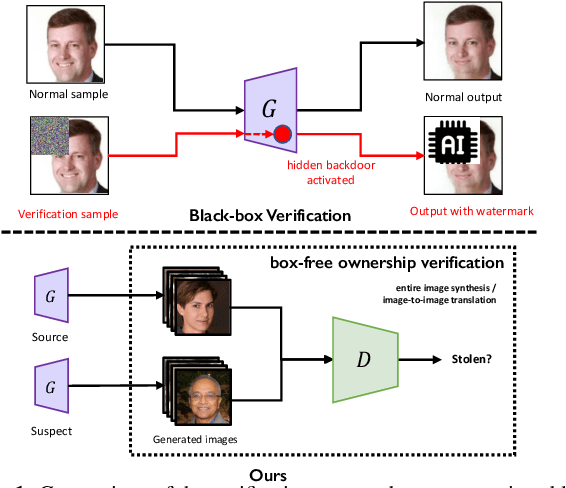
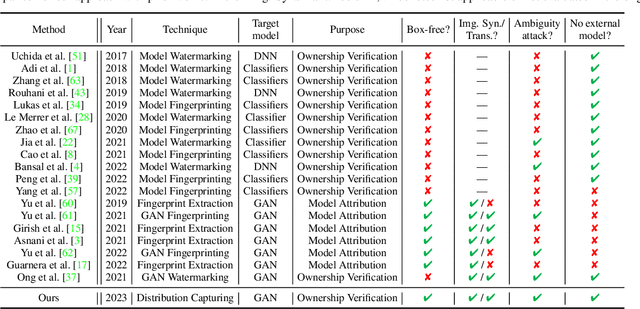
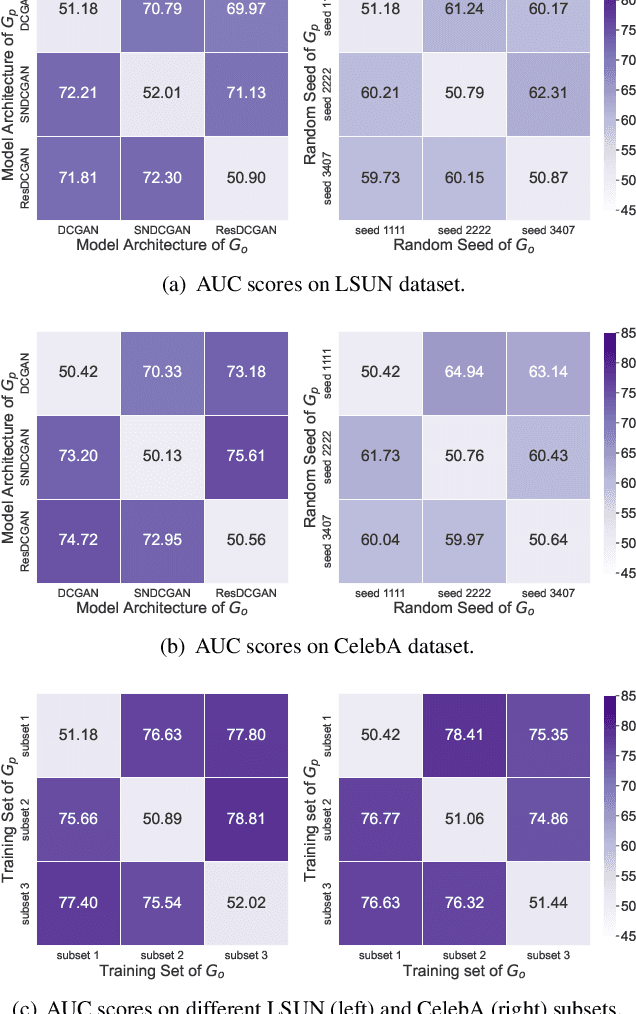

In recent decades, Generative Adversarial Network (GAN) and its variants have achieved unprecedented success in image synthesis. However, well-trained GANs are under the threat of illegal steal or leakage. The prior studies on remote ownership verification assume a black-box setting where the defender can query the suspicious model with specific inputs, which we identify is not enough for generation tasks. To this end, in this paper, we propose a novel IP protection scheme for GANs where ownership verification can be done by checking outputs only, without choosing the inputs (i.e., box-free setting). Specifically, we make use of the unexploited potential of the discriminator to learn a hypersphere that captures the unique distribution learned by the paired generator. Extensive evaluations on two popular GAN tasks and more than 10 GAN architectures demonstrate our proposed scheme to effectively verify the ownership. Our proposed scheme shown to be immune to popular input-based removal attacks and robust against other existing attacks. The source code and models are available at https://github.com/AbstractTeen/gan_ownership_verification
Dual-level Interaction for Domain Adaptive Semantic Segmentation
Jul 16, 2023



To circumvent the costly pixel-wise annotations of real-world images in the semantic segmentation task, the Unsupervised Domain Adaptation (UDA) is explored to firstly train a model with the labeled source data (synthetic images) and then adapt it to the unlabeled target data (real images). Among all the techniques being studied, the self-training approach recently secures its position in domain adaptive semantic segmentation, where a model is trained with target domain pseudo-labels. Current advances have mitigated noisy pseudo-labels resulting from the domain gap. However, they still struggle with erroneous pseudo-labels near the decision boundaries of the semantic classifier. In this paper, we tackle this issue by proposing a dual-level interaction for domain adaptation (DIDA) in semantic segmentation. Explicitly, we encourage the different augmented views of the same pixel to have not only similar class prediction (semantic-level) but also akin similarity relationship respected to other pixels (instance-level). As it is impossible to keep features of all pixel instances for a dataset, we novelly design and maintain a labeled instance bank with dynamic updating strategies to selectively store the informative features of instances. Further, DIDA performs cross-level interaction with scattering and gathering techniques to regenerate more reliable pseudolabels. Our method outperforms the state-of-the-art by a notable margin, especially on confusing and long-tailed classes. Code is available at https://github.com/RainJamesY/DIDA.
Optimized Design Method for Satellite Constellation Configuration Based on Real-time Coverage Area Evaluation
Sep 16, 2022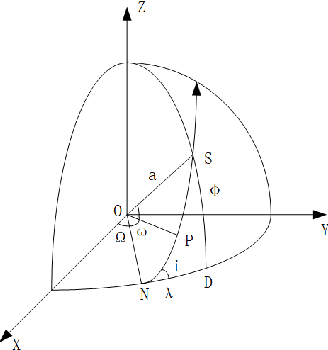
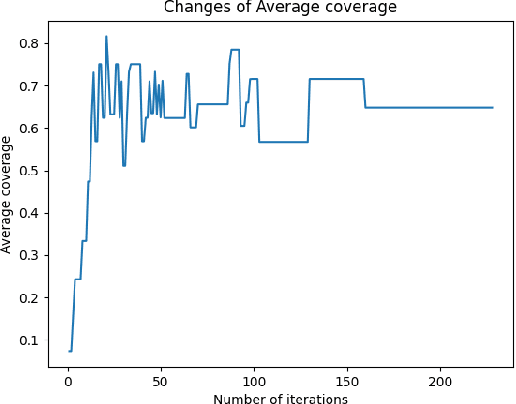
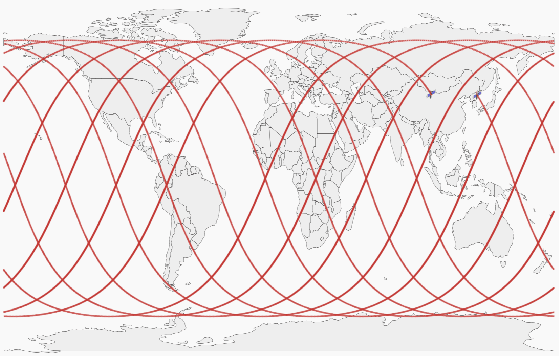
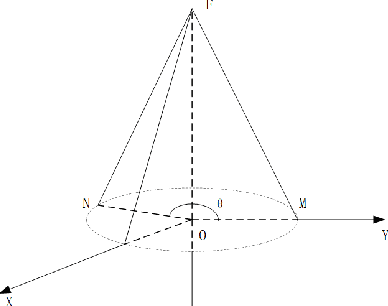
When using constellation synergy to image large areas for reconnaissance, it is required to achieve the coverage capability requirements with minimal consumption of observation resources to obtain the most optimal constellation observation scheme. With the minimum number of satellites and meeting the real-time ground coverage requirements as the optimization objectives, this paper proposes an optimized design of satellite constellation configuration for full coverage of large-scale regional imaging by using an improved simulated annealing algorithm combined with the real-time coverage evaluation method of hexagonal discretization. The algorithm can adapt to experimental conditions, has good efficiency, and can meet industrial accuracy requirements. The effectiveness and adaptability of the algorithm are tested in simulation applications.