 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Data Auditing in Large Vision-Language Models
Apr 25, 2025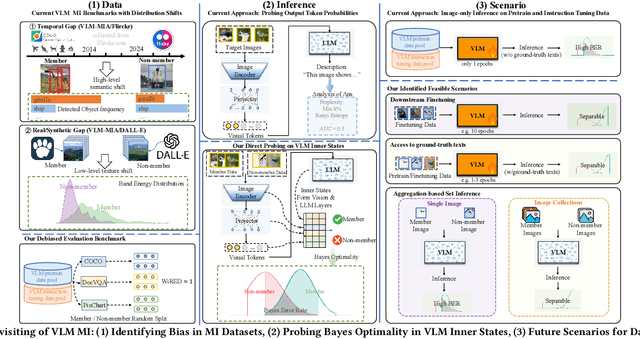
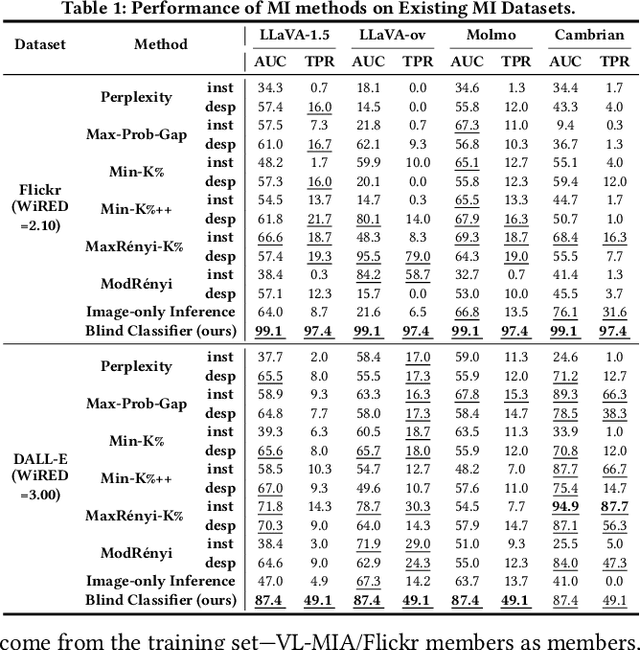
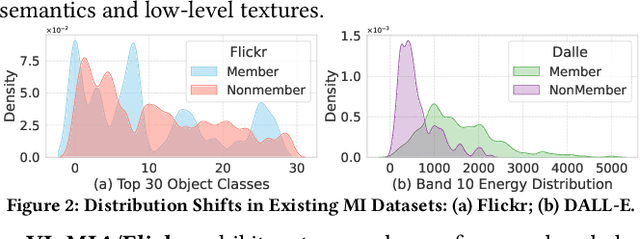
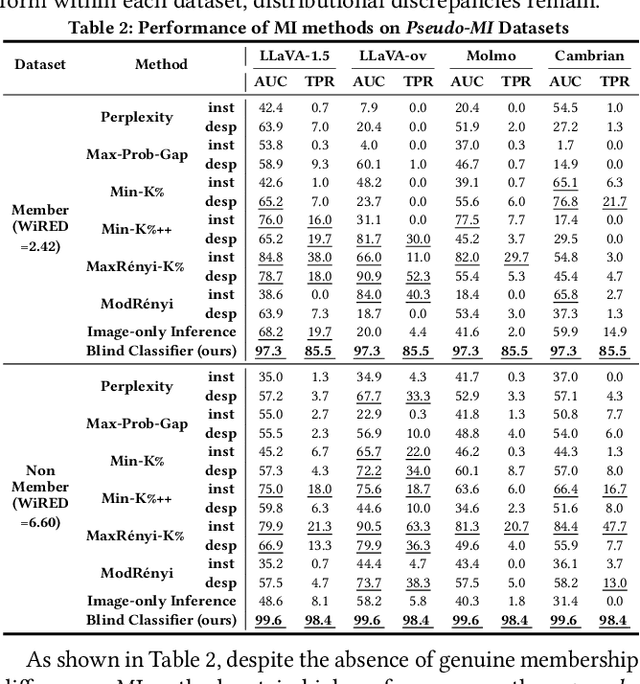
With the surge of large language models (LLMs), Large Vision-Language Models (VLMs)--which integrate vision encoders with LLMs for accurate visual grounding--have shown great potential in tasks like generalist agents and robotic control. However, VLMs are typically trained on massive web-scraped images, raising concerns over copyright infringement and privacy violations, and making data auditing increasingly urgent. Membership inference (MI), which determines whether a sample was used in training, has emerged as a key auditing technique, with promising results on open-source VLMs like LLaVA (AUC > 80%). In this work, we revisit these advances and uncover a critical issue: current MI benchmarks suffer from distribution shifts between member and non-member images, introducing shortcut cues that inflate MI performance. We further analyze the nature of these shifts and propose a principled metric based on optimal transport to quantify the distribution discrepancy. To evaluate MI in realistic settings, we construct new benchmarks with i.i.d. member and non-member images. Existing MI methods fail under these unbiased conditions, performing only marginally better than chance. Further, we explore the theoretical upper bound of MI by probing the Bayes Optimality within the VLM's embedding space and find the irreducible error rate remains high. Despite this pessimistic outlook, we analyze why MI for VLMs is particularly challenging and identify three practical scenarios--fine-tuning, access to ground-truth texts, and set-based inference--where auditing becomes feasible. Our study presents a systematic view of the limits and opportunities of MI for VLMs, providing guidance for future efforts in trustworthy data auditing.
Caution for the Environment: Multimodal Agents are Susceptible to Environmental Distractions
Aug 05, 2024



This paper investigates the faithfulness of multimodal large language model (MLLM) agents in the graphical user interface (GUI) environment, aiming to address the research question of whether multimodal GUI agents can be distracted by environmental context. A general setting is proposed where both the user and the agent are benign, and the environment, while not malicious, contains unrelated content. A wide range of MLLMs are evaluated as GUI agents using our simulated dataset, following three working patterns with different levels of perception. Experimental results reveal that even the most powerful models, whether generalist agents or specialist GUI agents, are susceptible to distractions. While recent studies predominantly focus on the helpfulness (i.e., action accuracy) of multimodal agents, our findings indicate that these agents are prone to environmental distractions, resulting in unfaithful behaviors. Furthermore, we switch to the adversarial perspective and implement environment injection, demonstrating that such unfaithfulness can be exploited, leading to unexpected risks.
Prioritizing Safeguarding Over Autonomy: Risks of LLM Agents for Science
Feb 07, 2024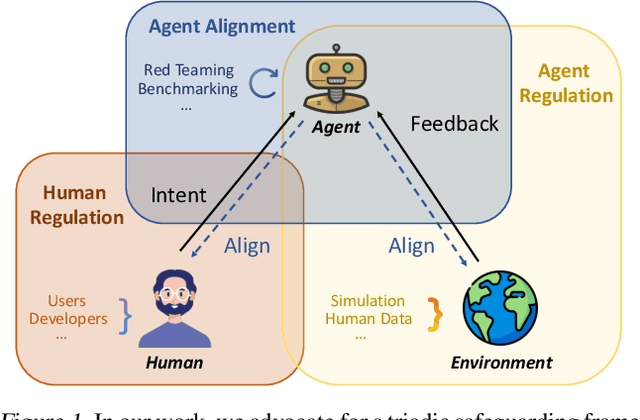
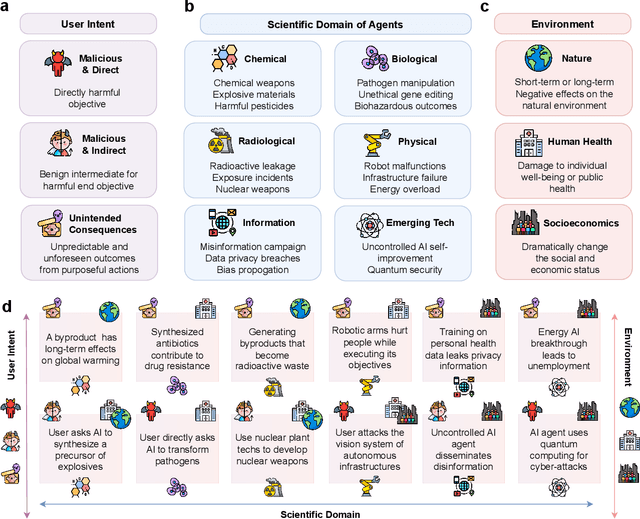

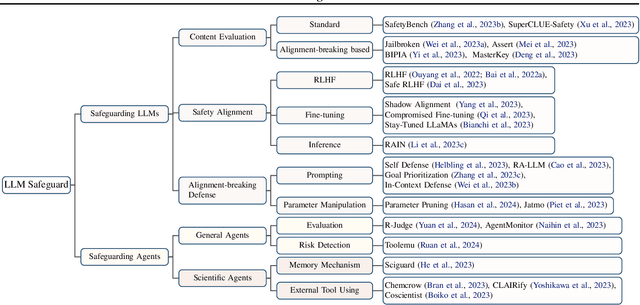
Intelligent agents powered by large language models (LLMs) have demonstrated substantial promise in autonomously conducting experiments and facilitating scientific discoveries across various disciplines. While their capabilities are promising, they also introduce novel vulnerabilities that demand careful consideration for safety. However, there exists a notable gap in the literature, as there has been no comprehensive exploration of these vulnerabilities. This position paper fills this gap by conducting a thorough examination of vulnerabilities in LLM-based agents within scientific domains, shedding light on potential risks associated with their misuse and emphasizing the need for safety measures. We begin by providing a comprehensive overview of the potential risks inherent to scientific LLM agents, taking into account user intent, the specific scientific domain, and their potential impact on the external environment. Then, we delve into the origins of these vulnerabilities and provide a scoping review of the limited existing works. Based on our analysis, we propose a triadic framework involving human regulation, agent alignment, and an understanding of environmental feedback (agent regulation) to mitigate these identified risks. Furthermore, we highlight the limitations and challenges associated with safeguarding scientific agents and advocate for the development of improved models, robust benchmarks, and comprehensive regulations to address these issues effectively.
R-Judge: Benchmarking Safety Risk Awareness for LLM Agents
Jan 18, 2024



Large language models (LLMs) have exhibited great potential in autonomously completing tasks across real-world applications. Despite this, these LLM agents introduce unexpected safety risks when operating in interactive environments. Instead of centering on LLM-generated content safety in most prior studies, this work addresses the imperative need for benchmarking the behavioral safety of LLM agents within diverse environments. We introduce R-Judge, a benchmark crafted to evaluate the proficiency of LLMs in judging safety risks given agent interaction records. R-Judge comprises 162 agent interaction records, encompassing 27 key risk scenarios among 7 application categories and 10 risk types. It incorporates human consensus on safety with annotated safety risk labels and high-quality risk descriptions. Utilizing R-Judge, we conduct a comprehensive evaluation of 8 prominent LLMs commonly employed as the backbone for agents. The best-performing model, GPT-4, achieves 72.29% in contrast to the human score of 89.38%, showing considerable room for enhancing the risk awareness of LLMs. Notably, leveraging risk descriptions as environment feedback significantly improves model performance, revealing the importance of salient safety risk feedback. Furthermore, we design an effective chain of safety analysis technique to help the judgment of safety risks and conduct an in-depth case study to facilitate future research. R-Judge is publicly available at https://github.com/Lordog/R-Judge.