 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Data Auditing in Large Vision-Language Models
Apr 25, 2025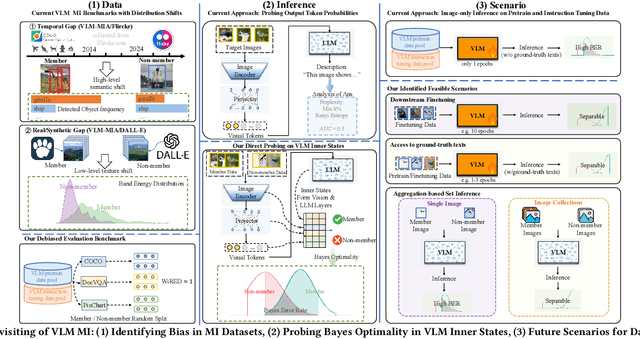
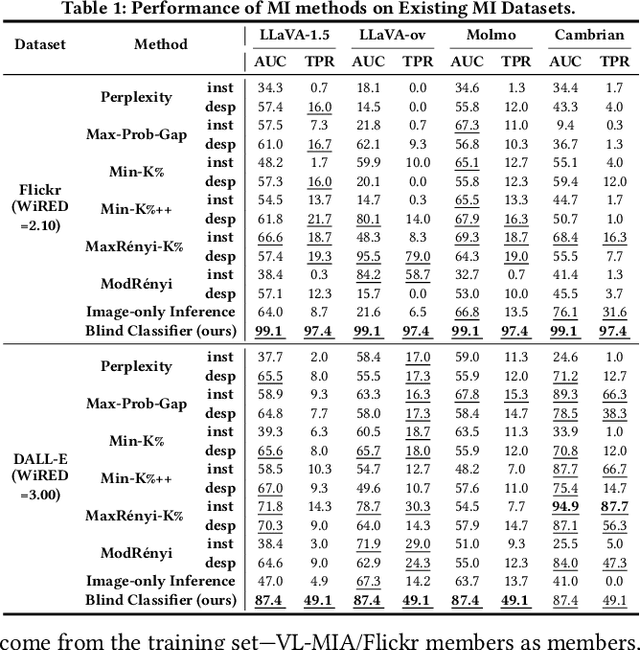
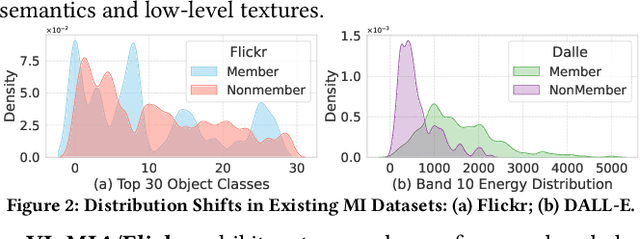
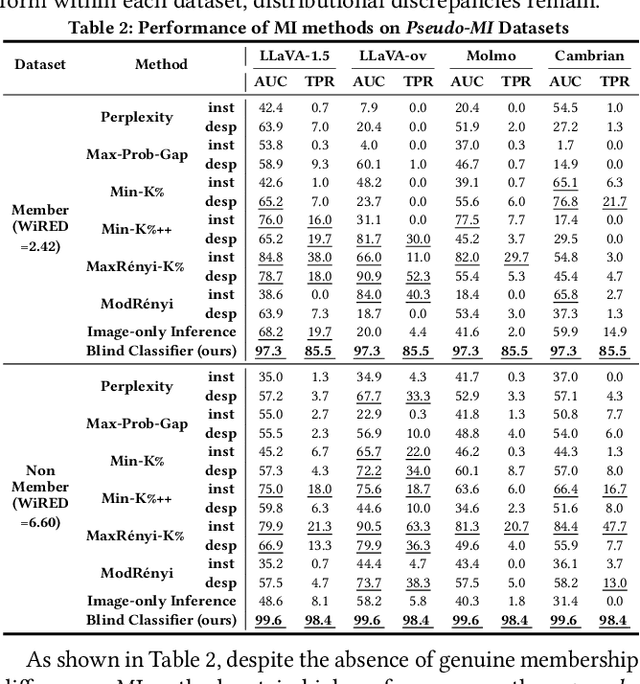
With the surge of large language models (LLMs), Large Vision-Language Models (VLMs)--which integrate vision encoders with LLMs for accurate visual grounding--have shown great potential in tasks like generalist agents and robotic control. However, VLMs are typically trained on massive web-scraped images, raising concerns over copyright infringement and privacy violations, and making data auditing increasingly urgent. Membership inference (MI), which determines whether a sample was used in training, has emerged as a key auditing technique, with promising results on open-source VLMs like LLaVA (AUC > 80%). In this work, we revisit these advances and uncover a critical issue: current MI benchmarks suffer from distribution shifts between member and non-member images, introducing shortcut cues that inflate MI performance. We further analyze the nature of these shifts and propose a principled metric based on optimal transport to quantify the distribution discrepancy. To evaluate MI in realistic settings, we construct new benchmarks with i.i.d. member and non-member images. Existing MI methods fail under these unbiased conditions, performing only marginally better than chance. Further, we explore the theoretical upper bound of MI by probing the Bayes Optimality within the VLM's embedding space and find the irreducible error rate remains high. Despite this pessimistic outlook, we analyze why MI for VLMs is particularly challenging and identify three practical scenarios--fine-tuning, access to ground-truth texts, and set-based inference--where auditing becomes feasible. Our study presents a systematic view of the limits and opportunities of MI for VLMs, providing guidance for future efforts in trustworthy data auditing.
PromptLA: Towards Integrity Verification of Black-box Text-to-Image Diffusion Models
Dec 20, 2024



Current text-to-image (T2I) diffusion models can produce high-quality images, and malicious users who are authorized to use the model only for benign purposes might modify their models to generate images that result in harmful social impacts. Therefore, it is essential to verify the integrity of T2I diffusion models, especially when they are deployed as black-box services. To this end, considering the randomness within the outputs of generative models and the high costs in interacting with them, we capture modifications to the model through the differences in the distributions of the features of generated images. We propose a novel prompt selection algorithm based on learning automaton for efficient and accurate integrity verification of T2I diffusion models. Extensive experiments demonstrate the effectiveness, stability, accuracy and generalization of our algorithm against existing integrity violations compared with baselines. To the best of our knowledge, this paper is the first work addressing the integrity verification of T2I diffusion models, which paves the way to copyright discussions and protections for artificial intelligence applications in practice.
NSmark: Null Space Based Black-box Watermarking Defense Framework for Pre-trained Language Models
Oct 16, 2024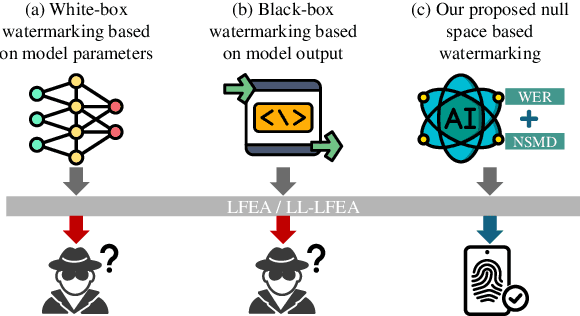



Pre-trained language models (PLMs) have emerged as critical intellectual property (IP) assets that necessitate protection. Although various watermarking strategies have been proposed, they remain vulnerable to Linear Functionality Equivalence Attacks (LFEA), which can invalidate most existing white-box watermarks without prior knowledge of the watermarking scheme or training data. This paper further analyzes and extends the attack scenarios of LFEA to the commonly employed black-box settings for PLMs by considering Last-Layer outputs (dubbed LL-LFEA). We discover that the null space of the output matrix remains invariant against LL-LFEA attacks. Based on this finding, we propose NSmark, a task-agnostic, black-box watermarking scheme capable of resisting LL-LFEA attacks. NSmark consists of three phases: (i) watermark generation using the digital signature of the owner, enhanced by spread spectrum modulation for increased robustness; (ii) watermark embedding through an output mapping extractor that preserves PLM performance while maximizing watermark capacity; (iii) watermark verification, assessed by extraction rate and null space conformity. Extensive experiments on both pre-training and downstream tasks confirm the effectiveness, reliability, fidelity, and robustness of our approach. Code is available at https://github.com/dongdongzhaoUP/NSmark.
Efficient and Effective Model Extraction
Sep 24, 2024



Model extraction aims to create a functionally similar copy from a machine learning as a service (MLaaS) API with minimal overhead, typically for illicit profit or as a precursor to further attacks, posing a significant threat to the MLaaS ecosystem. However, recent studies have shown that model extraction is highly inefficient, particularly when the target task distribution is unavailable. In such cases, even substantially increasing the attack budget fails to produce a sufficiently similar replica, reducing the adversary's motivation to pursue extraction attacks. In this paper, we revisit the elementary design choices throughout the extraction lifecycle. We propose an embarrassingly simple yet dramatically effective algorithm, Efficient and Effective Model Extraction (E3), focusing on both query preparation and training routine. E3 achieves superior generalization compared to state-of-the-art methods while minimizing computational costs. For instance, with only 0.005 times the query budget and less than 0.2 times the runtime, E3 outperforms classical generative model based data-free model extraction by an absolute accuracy improvement of over 50% on CIFAR-10. Our findings underscore the persistent threat posed by model extraction and suggest that it could serve as a valuable benchmarking algorithm for future security evaluations.
Reliable Model Watermarking: Defending Against Theft without Compromising on Evasion
Apr 21, 2024
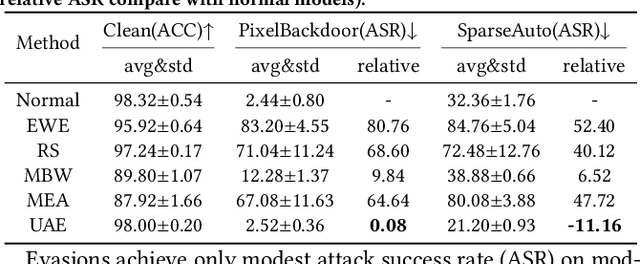
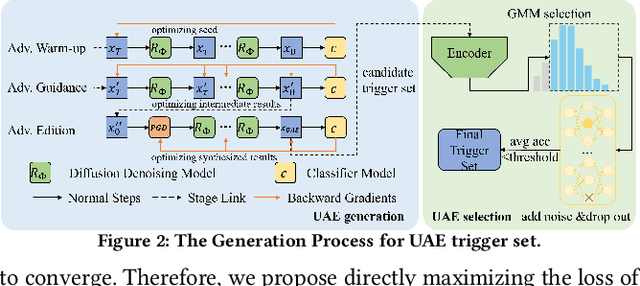

With the rise of Machine Learning as a Service (MLaaS) platforms,safeguarding the intellectual property of deep learning models is becoming paramount. Among various protective measures, trigger set watermarking has emerged as a flexible and effective strategy for preventing unauthorized model distribution. However, this paper identifies an inherent flaw in the current paradigm of trigger set watermarking: evasion adversaries can readily exploit the shortcuts created by models memorizing watermark samples that deviate from the main task distribution, significantly impairing their generalization in adversarial settings. To counteract this, we leverage diffusion models to synthesize unrestricted adversarial examples as trigger sets. By learning the model to accurately recognize them, unique watermark behaviors are promoted through knowledge injection rather than error memorization, thus avoiding exploitable shortcuts. Furthermore, we uncover that the resistance of current trigger set watermarking against removal attacks primarily relies on significantly damaging the decision boundaries during embedding, intertwining unremovability with adverse impacts. By optimizing the knowledge transfer properties of protected models, our approach conveys watermark behaviors to extraction surrogates without aggressively decision boundary perturbation. Experimental results on CIFAR-10/100 and Imagenette datasets demonstrate the effectiveness of our method, showing not only improved robustness against evasion adversaries but also superior resistance to watermark removal attacks compared to state-of-the-art solutions.
Revisiting the Information Capacity of Neural Network Watermarks: Upper Bound Estimation and Beyond
Feb 20, 2024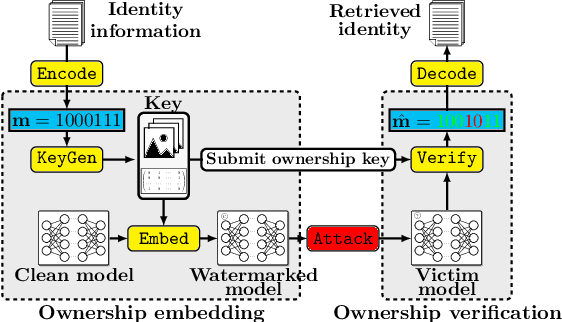
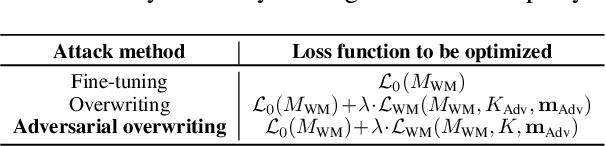
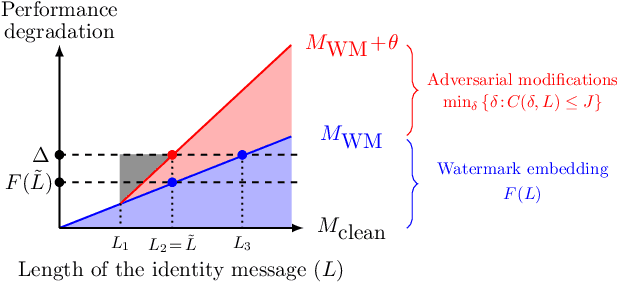

To trace the copyright of deep neural networks, an owner can embed its identity information into its model as a watermark. The capacity of the watermark quantify the maximal volume of information that can be verified from the watermarked model. Current studies on capacity focus on the ownership verification accuracy under ordinary removal attacks and fail to capture the relationship between robustness and fidelity. This paper studies the capacity of deep neural network watermarks from an information theoretical perspective. We propose a new definition of deep neural network watermark capacity analogous to channel capacity, analyze its properties, and design an algorithm that yields a tight estimation of its upper bound under adversarial overwriting. We also propose a universal non-invasive method to secure the transmission of the identity message beyond capacity by multiple rounds of ownership verification. Our observations provide evidence for neural network owners and defenders that are curious about the tradeoff between the integrity of their ownership and the performance degradation of their products.
R-Judge: Benchmarking Safety Risk Awareness for LLM Agents
Jan 18, 2024



Large language models (LLMs) have exhibited great potential in autonomously completing tasks across real-world applications. Despite this, these LLM agents introduce unexpected safety risks when operating in interactive environments. Instead of centering on LLM-generated content safety in most prior studies, this work addresses the imperative need for benchmarking the behavioral safety of LLM agents within diverse environments. We introduce R-Judge, a benchmark crafted to evaluate the proficiency of LLMs in judging safety risks given agent interaction records. R-Judge comprises 162 agent interaction records, encompassing 27 key risk scenarios among 7 application categories and 10 risk types. It incorporates human consensus on safety with annotated safety risk labels and high-quality risk descriptions. Utilizing R-Judge, we conduct a comprehensive evaluation of 8 prominent LLMs commonly employed as the backbone for agents. The best-performing model, GPT-4, achieves 72.29% in contrast to the human score of 89.38%, showing considerable room for enhancing the risk awareness of LLMs. Notably, leveraging risk descriptions as environment feedback significantly improves model performance, revealing the importance of salient safety risk feedback. Furthermore, we design an effective chain of safety analysis technique to help the judgment of safety risks and conduct an in-depth case study to facilitate future research. R-Judge is publicly available at https://github.com/Lordog/R-Judge.
Reduce Communication Costs and Preserve Privacy: Prompt Tuning Method in Federated Learning
Aug 25, 2022
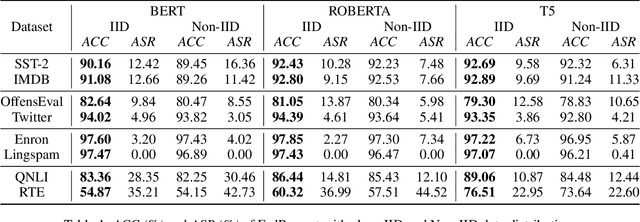

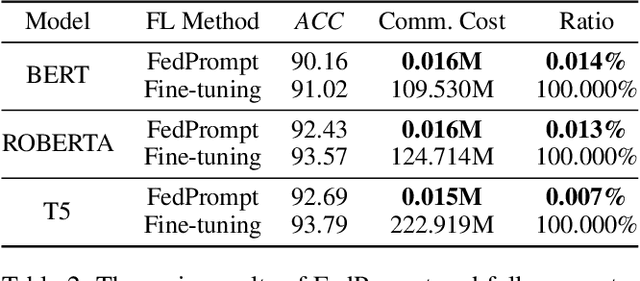
Federated learning (FL) has enabled global model training on decentralized data in a privacy-preserving way by aggregating model updates. However, for many natural language processing (NLP) tasks that utilize pre-trained language models (PLMs) with large numbers of parameters, there are considerable communication costs associated with FL. Recently, prompt tuning, which tunes some soft prompts without modifying PLMs, has achieved excellent performance as a new learning paradigm. Therefore we want to combine the two methods and explore the effect of prompt tuning under FL. In this paper, we propose "FedPrompt" as the first work study prompt tuning in a model split learning way using FL, and prove that split learning greatly reduces the communication cost, only 0.01% of the PLMs' parameters, with little decrease on accuracy both on IID and Non-IID data distribution. This improves the efficiency of FL method while also protecting the data privacy in prompt tuning.In addition, like PLMs, prompts are uploaded and downloaded between public platforms and personal users, so we try to figure out whether there is still a backdoor threat using only soft prompt in FL scenarios. We further conduct backdoor attacks by data poisoning on FedPrompt. Our experiments show that normal backdoor attack can not achieve a high attack success rate, proving the robustness of FedPrompt.We hope this work can promote the application of prompt in FL and raise the awareness of the possible security threats.
Knowledge-Free Black-Box Watermark and Ownership Proof for Image Classification Neural Networks
Apr 09, 2022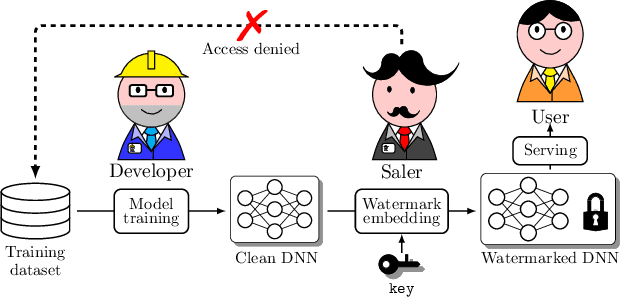

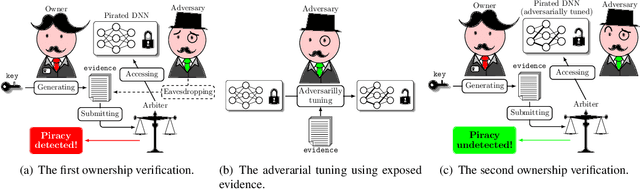

Watermarking has become a plausible candidate for ownership verification and intellectual property protection of deep neural networks. Regarding image classification neural networks, current watermarking schemes uniformly resort to backdoor triggers. However, injecting a backdoor into a neural network requires knowledge of the training dataset, which is usually unavailable in the real-world commercialization. Meanwhile, established watermarking schemes oversight the potential damage of exposed evidence during ownership verification and the watermarking algorithms themselves. Those concerns decline current watermarking schemes from industrial applications. To confront these challenges, we propose a knowledge-free black-box watermarking scheme for image classification neural networks. The image generator obtained from a data-free distillation process is leveraged to stabilize the network's performance during the backdoor injection. A delicate encoding and verification protocol is designed to ensure the scheme's security against knowledgable adversaries. We also give a pioneering analysis of the capacity of the watermarking scheme. Experiment results proved the functionality-preserving capability and security of the proposed watermarking scheme.
FastCover: An Unsupervised Learning Framework for Multi-Hop Influence Maximization in Social Networks
Oct 31, 2021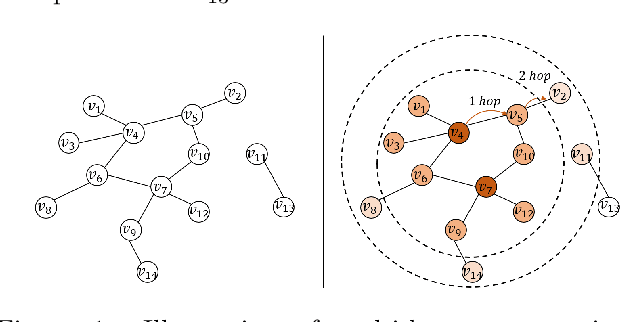

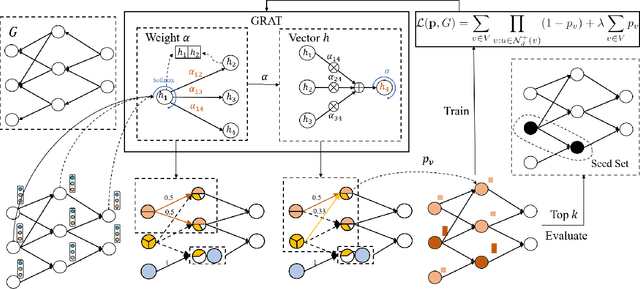
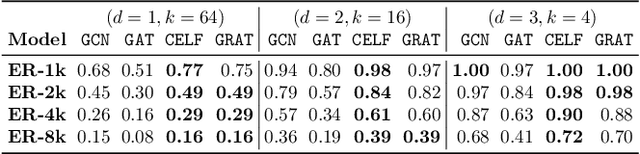
Finding influential users in social networks is a fundamental problem with many possible useful applications. Viewing the social network as a graph, the influence of a set of users can be measured by the number of neighbors located within a given number of hops in the network, where each hop marks a step of influence diffusion. In this paper, we reduce the problem of IM to a budget-constrained d-hop dominating set problem (kdDSP). We propose a unified machine learning (ML) framework, FastCover, to solve kdDSP by learning an efficient greedy strategy in an unsupervised way. As one critical component of the framework, we devise a novel graph neural network (GNN) architecture, graph reversed attention network (GRAT), that captures the diffusion process among neighbors. Unlike most heuristic algorithms and concurrent ML frameworks for combinatorial optimization problems, FastCover determines the entire seed set from the nodes' scores computed with only one forward propagation of the GNN and has a time complexity quasi-linear in the graph size. Experiments on synthetic graphs and real-world social networks demonstrate that FastCover finds solutions with better or comparable quality rendered by the concurrent algorithms while achieving a speedup of over 1000x.