 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Vision Replace Text in Working Memory? Evidence from Spatial n-Back in Vision-Language Models
Feb 04, 2026Working memory is a central component of intelligent behavior, providing a dynamic workspace for maintaining and updating task-relevant information. Recent work has used n-back tasks to probe working-memory-like behavior in large language models, but it is unclear whether the same probe elicits comparable computations when information is carried in a visual rather than textual code in vision-language models. We evaluate Qwen2.5 and Qwen2.5-VL on a controlled spatial n-back task presented as matched text-rendered or image-rendered grids. Across conditions, models show reliably higher accuracy and d' with text than with vision. To interpret these differences at the process level, we use trial-wise log-probability evidence and find that nominal 2/3-back often fails to reflect the instructed lag and instead aligns with a recency-locked comparison. We further show that grid size alters recent-repeat structure in the stimulus stream, thereby changing interference and error patterns. These results motivate computation-sensitive interpretations of multimodal working memory.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Revisiting Data Auditing in Large Vision-Language Models
Apr 25, 2025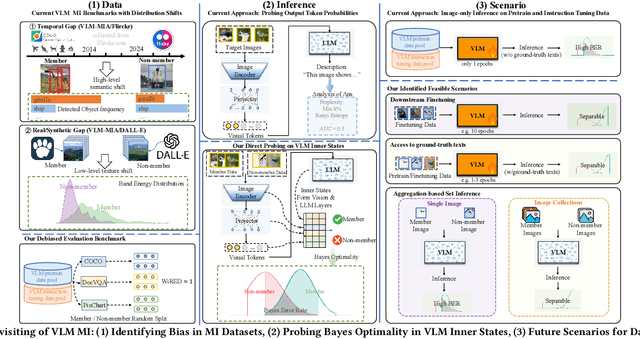
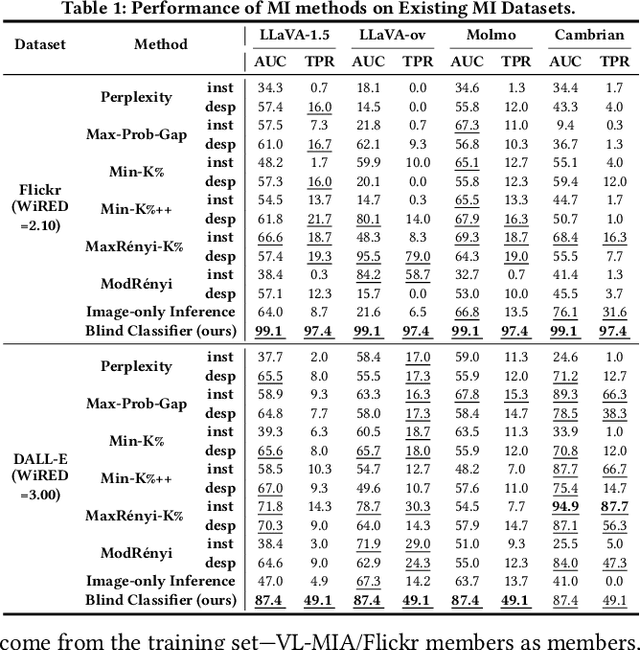
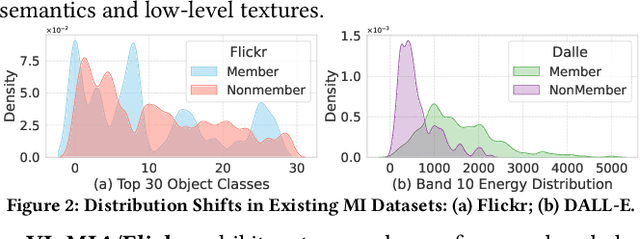
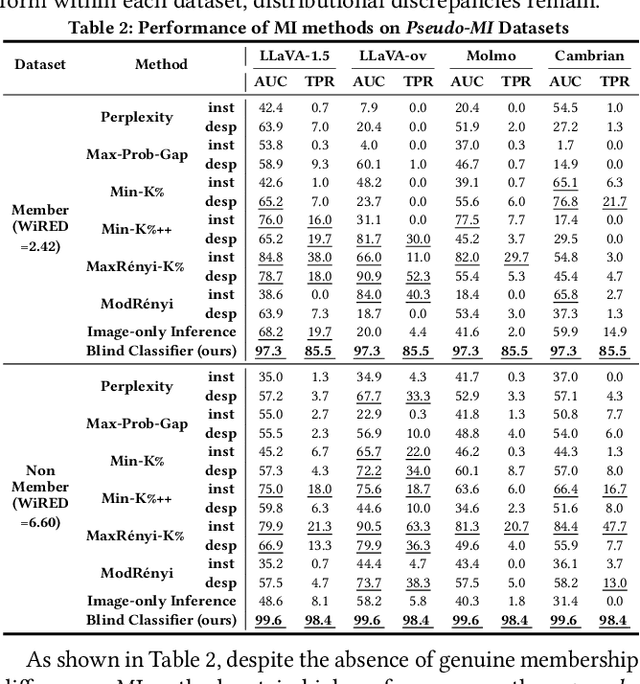
With the surge of large language models (LLMs), Large Vision-Language Models (VLMs)--which integrate vision encoders with LLMs for accurate visual grounding--have shown great potential in tasks like generalist agents and robotic control. However, VLMs are typically trained on massive web-scraped images, raising concerns over copyright infringement and privacy violations, and making data auditing increasingly urgent. Membership inference (MI), which determines whether a sample was used in training, has emerged as a key auditing technique, with promising results on open-source VLMs like LLaVA (AUC > 80%). In this work, we revisit these advances and uncover a critical issue: current MI benchmarks suffer from distribution shifts between member and non-member images, introducing shortcut cues that inflate MI performance. We further analyze the nature of these shifts and propose a principled metric based on optimal transport to quantify the distribution discrepancy. To evaluate MI in realistic settings, we construct new benchmarks with i.i.d. member and non-member images. Existing MI methods fail under these unbiased conditions, performing only marginally better than chance. Further, we explore the theoretical upper bound of MI by probing the Bayes Optimality within the VLM's embedding space and find the irreducible error rate remains high. Despite this pessimistic outlook, we analyze why MI for VLMs is particularly challenging and identify three practical scenarios--fine-tuning, access to ground-truth texts, and set-based inference--where auditing becomes feasible. Our study presents a systematic view of the limits and opportunities of MI for VLMs, providing guidance for future efforts in trustworthy data auditing.
RGAR: Recurrence Generation-augmented Retrieval for Factual-aware Medical Question Answering
Feb 19, 2025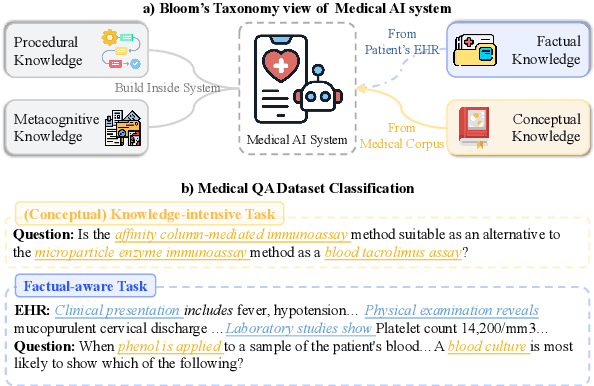
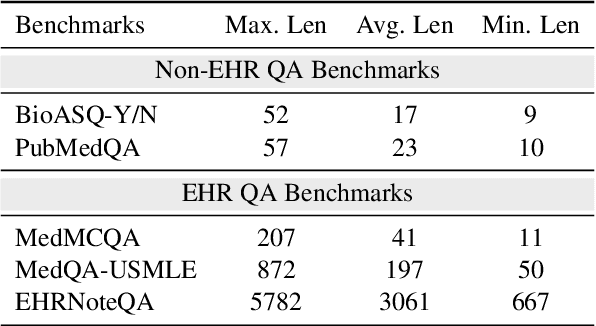
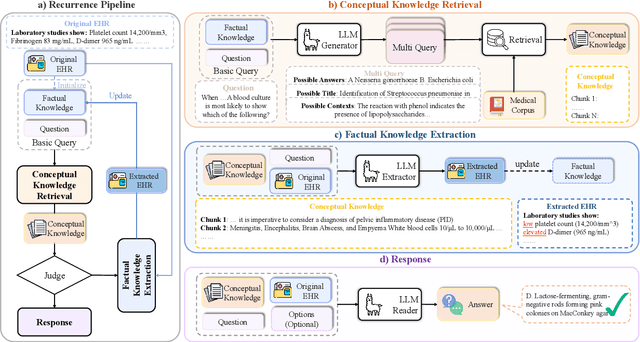
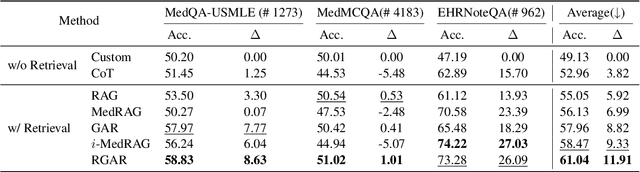
Medical question answering requires extensive access to specialized conceptual knowledge. The current paradigm, Retrieval-Augmented Generation (RAG), acquires expertise medical knowledge through large-scale corpus retrieval and uses this knowledge to guide a general-purpose large language model (LLM) for generating answers. However, existing retrieval approaches often overlook the importance of factual knowledge, which limits the relevance of retrieved conceptual knowledge and restricts its applicability in real-world scenarios, such as clinical decision-making based on Electronic Health Records (EHRs). This paper introduces RGAR, a recurrence generation-augmented retrieval framework that retrieves both relevant factual and conceptual knowledge from dual sources (i.e., EHRs and the corpus), allowing them to interact and refine each another. Through extensive evaluation across three factual-aware medical question answering benchmarks, RGAR establishes a new state-of-the-art performance among medical RAG systems. Notably, the Llama-3.1-8B-Instruct model with RGAR surpasses the considerably larger, RAG-enhanced GPT-3.5. Our findings demonstrate the benefit of extracting factual knowledge for retrieval, which consistently yields improved generation quality.
Efficient and Effective Model Extraction
Sep 24, 2024



Model extraction aims to create a functionally similar copy from a machine learning as a service (MLaaS) API with minimal overhead, typically for illicit profit or as a precursor to further attacks, posing a significant threat to the MLaaS ecosystem. However, recent studies have shown that model extraction is highly inefficient, particularly when the target task distribution is unavailable. In such cases, even substantially increasing the attack budget fails to produce a sufficiently similar replica, reducing the adversary's motivation to pursue extraction attacks. In this paper, we revisit the elementary design choices throughout the extraction lifecycle. We propose an embarrassingly simple yet dramatically effective algorithm, Efficient and Effective Model Extraction (E3), focusing on both query preparation and training routine. E3 achieves superior generalization compared to state-of-the-art methods while minimizing computational costs. For instance, with only 0.005 times the query budget and less than 0.2 times the runtime, E3 outperforms classical generative model based data-free model extraction by an absolute accuracy improvement of over 50% on CIFAR-10. Our findings underscore the persistent threat posed by model extraction and suggest that it could serve as a valuable benchmarking algorithm for future security evaluations.
EM-DARTS: Hierarchical Differentiable Architecture Search for Eye Movement Recognition
Sep 22, 2024



Eye movement biometrics has received increasing attention thanks to its high secure identification. Although deep learning (DL) models have been recently successfully applied for eye movement recognition, the DL architecture still is determined by human prior knowledge. Differentiable Neural Architecture Search (DARTS) automates the manual process of architecture design with high search efficiency. DARTS, however, usually stacks the same multiple learned cells to form a final neural network for evaluation, limiting therefore the diversity of the network. Incidentally, DARTS usually searches the architecture in a shallow network while evaluating it in a deeper one, which results in a large gap between the architecture depths in the search and evaluation scenarios. To address this issue, we propose EM-DARTS, a hierarchical differentiable architecture search algorithm to automatically design the DL architecture for eye movement recognition. First, we define a supernet and propose a global and local alternate Neural Architecture Search method to search the optimal architecture alternately with an differentiable neural architecture search. The local search strategy aims to find an optimal architecture for different cells while the global search strategy is responsible for optimizing the architecture of the target network. To further reduce redundancy, a transfer entropy is proposed to compute the information amount of each layer, so as to further simplify search network. Our experiments on three public databases demonstrate that the proposed EM-DARTS is capable of producing an optimal architecture that leads to state-of-the-art recognition performance.
Relax DARTS: Relaxing the Constraints of Differentiable Architecture Search for Eye Movement Recognition
Sep 18, 2024



Eye movement biometrics is a secure and innovative identification method. Deep learning methods have shown good performance, but their network architecture relies on manual design and combined priori knowledge. To address these issues, we introduce automated network search (NAS) algorithms to the field of eye movement recognition and present Relax DARTS, which is an improvement of the Differentiable Architecture Search (DARTS) to realize more efficient network search and training. The key idea is to circumvent the issue of weight sharing by independently training the architecture parameters $\alpha$ to achieve a more precise target architecture. Moreover, the introduction of module input weights $\beta$ allows cells the flexibility to select inputs, to alleviate the overfitting phenomenon and improve the model performance. Results on four public databases demonstrate that the Relax DARTS achieves state-of-the-art recognition performance. Notably, Relax DARTS exhibits adaptability to other multi-feature temporal classification tasks.
A Survey on Mixup Augmentations and Beyond
Sep 08, 2024



As Deep Neural Networks have achieved thrilling breakthroughs in the past decade, data augmentations have garnered increasing attention as regularization techniques when massive labeled data are unavailable. Among existing augmentations, Mixup and relevant data-mixing methods that convexly combine selected samples and the corresponding labels are widely adopted because they yield high performances by generating data-dependent virtual data while easily migrating to various domains. This survey presents a comprehensive review of foundational mixup methods and their applications. We first elaborate on the training pipeline with mixup augmentations as a unified framework containing modules. A reformulated framework could contain various mixup methods and give intuitive operational procedures. Then, we systematically investigate the applications of mixup augmentations on vision downstream tasks, various data modalities, and some analysis \& theorems of mixup. Meanwhile, we conclude the current status and limitations of mixup research and point out further work for effective and efficient mixup augmentations. This survey can provide researchers with the current state of the art in mixup methods and provide some insights and guidance roles in the mixup arena. An online project with this survey is available at \url{https://github.com/Westlake-AI/Awesome-Mixup}.
SUMix: Mixup with Semantic and Uncertain Information
Jul 10, 2024
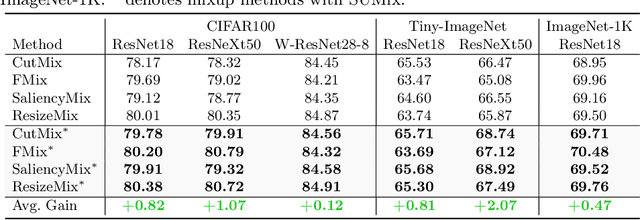
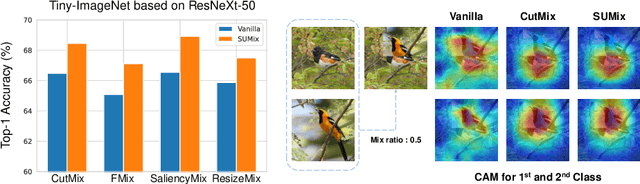
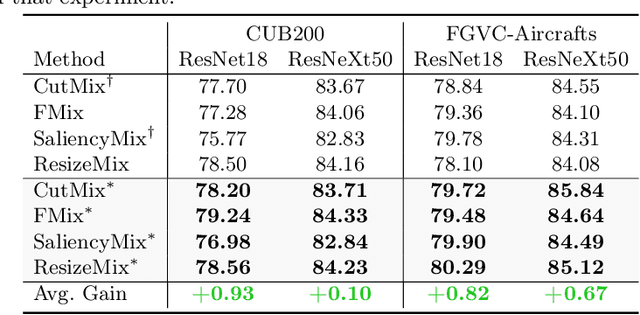
Mixup data augmentation approaches have been applied for various tasks of deep learning to improve the generalization ability of deep neural networks. Some existing approaches CutMix, SaliencyMix, etc. randomly replace a patch in one image with patches from another to generate the mixed image. Similarly, the corresponding labels are linearly combined by a fixed ratio $\lambda$ by l. The objects in two images may be overlapped during the mixing process, so some semantic information is corrupted in the mixed samples. In this case, the mixed image does not match the mixed label information. Besides, such a label may mislead the deep learning model training, which results in poor performance. To solve this problem, we proposed a novel approach named SUMix to learn the mixing ratio as well as the uncertainty for the mixed samples during the training process. First, we design a learnable similarity function to compute an accurate mix ratio. Second, an approach is investigated as a regularized term to model the uncertainty of the mixed samples. We conduct experiments on five image benchmarks, and extensive experimental results imply that our method is capable of improving the performance of classifiers with different cutting-based mixup approaches. The source code is available at https://github.com/JinXins/SUMix.
StarLKNet: Star Mixup with Large Kernel Networks for Palm Vein Identification
May 21, 2024



As a representative of a new generation of biometrics, vein identification technology offers a high level of security and convenience. Convolutional neural networks (CNNs), a prominent class of deep learning architectures, have been extensively utilized for vein identification. Since their performance and robustness are limited by small Effective Receptive Fields (e.g. 3$\times$3 kernels) and insufficient training samples, however, they are unable to extract global feature representations from vein images in an effective manner. To address these issues, we propose StarLKNet, a large kernel convolution-based palm-vein identification network, with the Mixup approach. Our StarMix learns effectively the distribution of vein features to expand samples. To enable CNNs to capture comprehensive feature representations from palm-vein images, we explored the effect of convolutional kernel size on the performance of palm-vein identification networks and designed LaKNet, a network leveraging large kernel convolution and gating mechanism. In light of the current state of knowledge, this represents an inaugural instance of the deployment of a CNN with large kernels in the domain of vein identification. Extensive experiments were conducted to validate the performance of StarLKNet on two public palm-vein datasets. The results demonstrated that StarMix provided superior augmentation, and LakNet exhibited more stable performance gains compared to mainstream approaches, resulting in the highest recognition accuracy and lowest identification error.