 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreshMem: Brain-Inspired Frequency-Space Hybrid Memory for Streaming Video Understanding
Feb 02, 2026Transitioning Multimodal Large Language Models (MLLMs) from offline to online streaming video understanding is essential for continuous perception. However, existing methods lack flexible adaptivity, leading to irreversible detail loss and context fragmentation. To resolve this, we propose FreshMem, a Frequency-Space Hybrid Memory network inspired by the brain's logarithmic perception and memory consolidation. FreshMem reconciles short-term fidelity with long-term coherence through two synergistic modules: Multi-scale Frequency Memory (MFM), which projects overflowing frames into representative frequency coefficients, complemented by residual details to reconstruct a global historical "gist"; and Space Thumbnail Memory (STM), which discretizes the continuous stream into episodic clusters by employing an adaptive compression strategy to distill them into high-density space thumbnails. Extensive experiments show that FreshMem significantly boosts the Qwen2-VL baseline, yielding gains of 5.20%, 4.52%, and 2.34% on StreamingBench, OV-Bench, and OVO-Bench, respectively. As a training-free solution, FreshMem outperforms several fully fine-tuned methods, offering a highly efficient paradigm for long-horizon streaming video understanding.
Understanding Cross Task Generalization in Handwriting-Based Alzheimer's Screening via Vision Language Adaptation
Nov 08, 2025Alzheimer's disease is a prevalent neurodegenerative disorder for which early detection is critical. Handwriting-often disrupted in prodromal AD-provides a non-invasive and cost-effective window into subtle motor and cognitive decline. Existing handwriting-based AD studies, mostly relying on online trajectories and hand-crafted features, have not systematically examined how task type influences diagnostic performance and cross-task generalization. Meanwhile, large-scale vision language models have demonstrated remarkable zero or few-shot anomaly detection in natural images and strong adaptability across medical modalities such as chest X-ray and brain MRI. However, handwriting-based disease detection remains largely unexplored within this paradigm. To close this gap, we introduce a lightweight Cross-Layer Fusion Adapter framework that repurposes CLIP for handwriting-based AD screening. CLFA implants multi-level fusion adapters within the visual encoder to progressively align representations toward handwriting-specific medical cues, enabling prompt-free and efficient zero-shot inference. Using this framework, we systematically investigate cross-task generalization-training on a specific handwriting task and evaluating on unseen ones-to reveal which task types and writing patterns most effectively discriminate AD. Extensive analyses further highlight characteristic stroke patterns and task-level factors that contribute to early AD identification, offering both diagnostic insights and a benchmark for handwriting-based cognitive assessment.
Enhancing Diagnostic Precision in Gastric Bleeding through Automated Lesion Segmentation: A Deep DuS-KFCM Approach
Nov 21, 2024


Timely and precise classification and segmentation of gastric bleeding in endoscopic imagery are pivotal for the rapid diagnosis and intervention of gastric complications, which is critical in life-saving medical procedures. Traditional methods grapple with the challenge posed by the indistinguishable intensity values of bleeding tissues adjacent to other gastric structures. Our study seeks to revolutionize this domain by introducing a novel deep learning model, the Dual Spatial Kernelized Constrained Fuzzy C-Means (Deep DuS-KFCM) clustering algorithm. This Hybrid Neuro-Fuzzy system synergizes Neural Networks with Fuzzy Logic to offer a highly precise and efficient identification of bleeding regions. Implementing a two-fold coarse-to-fine strategy for segmentation, this model initially employs the Spatial Kernelized Fuzzy C-Means (SKFCM) algorithm enhanced with spatial intensity profiles and subsequently harnesses the state-of-the-art DeepLabv3+ with ResNet50 architecture to refine the segmentation output. Through extensive experiments across mainstream gastric bleeding and red spots datasets, our Deep DuS-KFCM model demonstrated unprecedented accuracy rates of 87.95%, coupled with a specificity of 96.33%, outperforming contemporary segmentation methods. The findings underscore the model's robustness against noise and its outstanding segmentation capabilities, particularly for identifying subtle bleeding symptoms, thereby presenting a significant leap forward in medical image processing.
Hybrid Transformer for Early Alzheimer's Detection: Integration of Handwriting-Based 2D Images and 1D Signal Features
Oct 14, 2024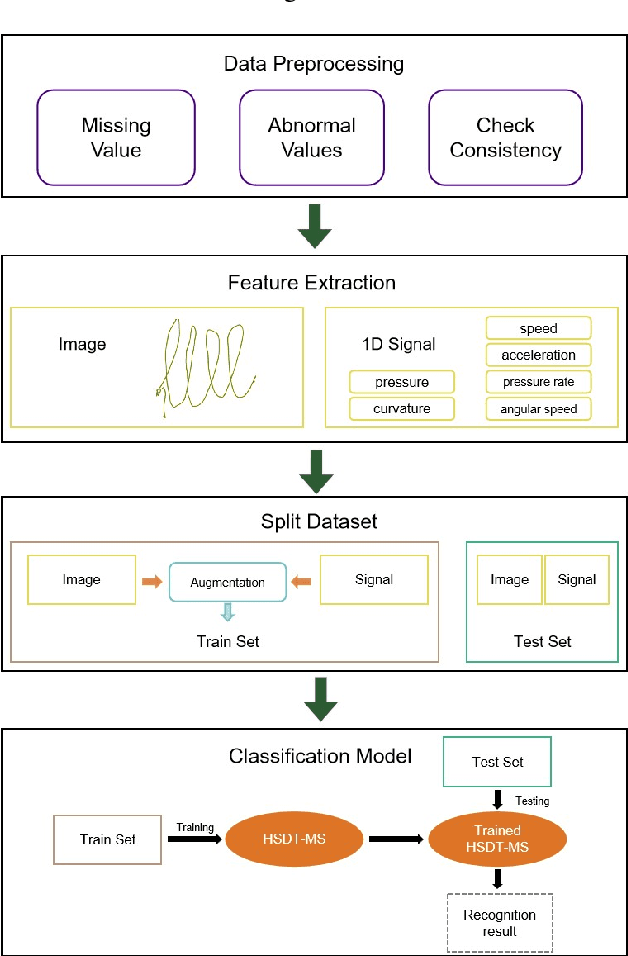
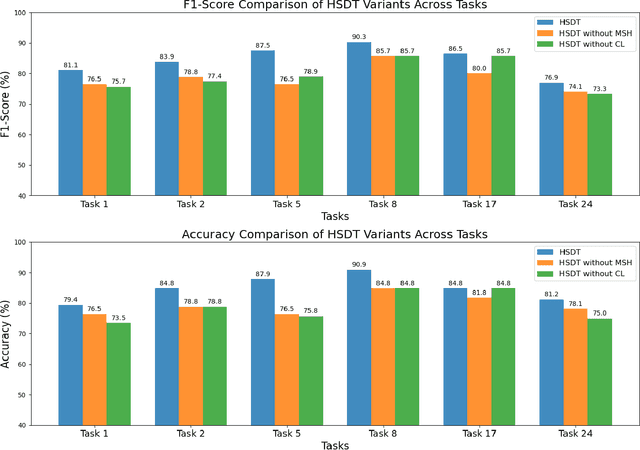


Alzheimer's Disease (AD) is a prevalent neurodegenerative condition where early detection is vital. Handwriting, often affected early in AD, offers a non-invasive and cost-effective way to capture subtle motor changes. State-of-the-art research on handwriting, mostly online, based AD detection has predominantly relied on manually extracted features, fed as input to shallow machine learning models. Some recent works have proposed deep learning (DL)-based models, either 1D-CNN or 2D-CNN architectures, with performance comparing favorably to handcrafted schemes. These approaches, however, overlook the intrinsic relationship between the 2D spatial patterns of handwriting strokes and their 1D dynamic characteristics, thus limiting their capacity to capture the multimodal nature of handwriting data. Moreover, the application of Transformer models remains basically unexplored. To address these limitations, we propose a novel approach for AD detection, consisting of a learnable multimodal hybrid attention model that integrates simultaneously 2D handwriting images with 1D dynamic handwriting signals. Our model leverages a gated mechanism to combine similarity and difference attention, blending the two modalities and learning robust features by incorporating information at different scales. Our model achieved state-of-the-art performance on the DARWIN dataset, with an F1-score of 90.32\% and accuracy of 90.91\% in Task 8 ('L' writing), surpassing the previous best by 4.61% and 6.06% respectively.
EM-DARTS: Hierarchical Differentiable Architecture Search for Eye Movement Recognition
Sep 22, 2024



Eye movement biometrics has received increasing attention thanks to its high secure identification. Although deep learning (DL) models have been recently successfully applied for eye movement recognition, the DL architecture still is determined by human prior knowledge. Differentiable Neural Architecture Search (DARTS) automates the manual process of architecture design with high search efficiency. DARTS, however, usually stacks the same multiple learned cells to form a final neural network for evaluation, limiting therefore the diversity of the network. Incidentally, DARTS usually searches the architecture in a shallow network while evaluating it in a deeper one, which results in a large gap between the architecture depths in the search and evaluation scenarios. To address this issue, we propose EM-DARTS, a hierarchical differentiable architecture search algorithm to automatically design the DL architecture for eye movement recognition. First, we define a supernet and propose a global and local alternate Neural Architecture Search method to search the optimal architecture alternately with an differentiable neural architecture search. The local search strategy aims to find an optimal architecture for different cells while the global search strategy is responsible for optimizing the architecture of the target network. To further reduce redundancy, a transfer entropy is proposed to compute the information amount of each layer, so as to further simplify search network. Our experiments on three public databases demonstrate that the proposed EM-DARTS is capable of producing an optimal architecture that leads to state-of-the-art recognition performance.
Relax DARTS: Relaxing the Constraints of Differentiable Architecture Search for Eye Movement Recognition
Sep 18, 2024



Eye movement biometrics is a secure and innovative identification method. Deep learning methods have shown good performance, but their network architecture relies on manual design and combined priori knowledge. To address these issues, we introduce automated network search (NAS) algorithms to the field of eye movement recognition and present Relax DARTS, which is an improvement of the Differentiable Architecture Search (DARTS) to realize more efficient network search and training. The key idea is to circumvent the issue of weight sharing by independently training the architecture parameters $\alpha$ to achieve a more precise target architecture. Moreover, the introduction of module input weights $\beta$ allows cells the flexibility to select inputs, to alleviate the overfitting phenomenon and improve the model performance. Results on four public databases demonstrate that the Relax DARTS achieves state-of-the-art recognition performance. Notably, Relax DARTS exhibits adaptability to other multi-feature temporal classification tasks.
A Survey on Mixup Augmentations and Beyond
Sep 08, 2024



As Deep Neural Networks have achieved thrilling breakthroughs in the past decade, data augmentations have garnered increasing attention as regularization techniques when massive labeled data are unavailable. Among existing augmentations, Mixup and relevant data-mixing methods that convexly combine selected samples and the corresponding labels are widely adopted because they yield high performances by generating data-dependent virtual data while easily migrating to various domains. This survey presents a comprehensive review of foundational mixup methods and their applications. We first elaborate on the training pipeline with mixup augmentations as a unified framework containing modules. A reformulated framework could contain various mixup methods and give intuitive operational procedures. Then, we systematically investigate the applications of mixup augmentations on vision downstream tasks, various data modalities, and some analysis \& theorems of mixup. Meanwhile, we conclude the current status and limitations of mixup research and point out further work for effective and efficient mixup augmentations. This survey can provide researchers with the current state of the art in mixup methods and provide some insights and guidance roles in the mixup arena. An online project with this survey is available at \url{https://github.com/Westlake-AI/Awesome-Mixup}.
MsMemoryGAN: A Multi-scale Memory GAN for Palm-vein Adversarial Purification
Aug 20, 2024

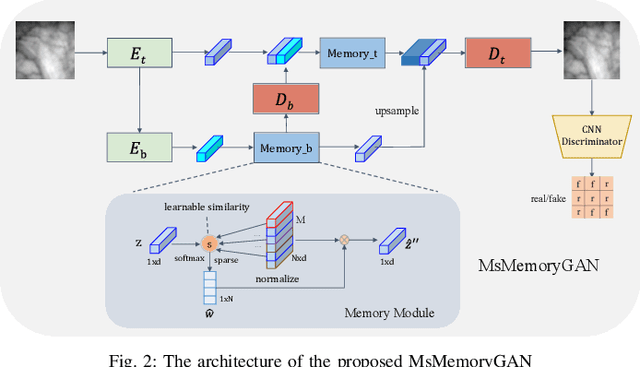
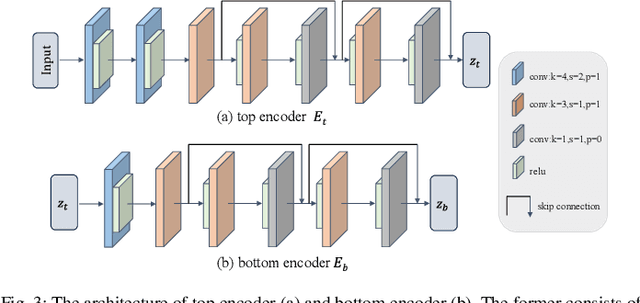
Deep neural networks have recently achieved promising performance in the vein recognition task and have shown an increasing application trend, however, they are prone to adversarial perturbation attacks by adding imperceptible perturbations to the input, resulting in making incorrect recognition. To address this issue, we propose a novel defense model named MsMemoryGAN, which aims to filter the perturbations from adversarial samples before recognition. First, we design a multi-scale autoencoder to achieve high-quality reconstruction and two memory modules to learn the detailed patterns of normal samples at different scales. Second, we investigate a learnable metric in the memory module to retrieve the most relevant memory items to reconstruct the input image. Finally, the perceptional loss is combined with the pixel loss to further enhance the quality of the reconstructed image. During the training phase, the MsMemoryGAN learns to reconstruct the input by merely using fewer prototypical elements of the normal patterns recorded in the memory. At the testing stage, given an adversarial sample, the MsMemoryGAN retrieves its most relevant normal patterns in memory for the reconstruction. Perturbations in the adversarial sample are usually not reconstructed well, resulting in purifying the input from adversarial perturbations. We have conducted extensive experiments on two public vein datasets under different adversarial attack methods to evaluate the performance of the proposed approach. The experimental results show that our approach removes a wide variety of adversarial perturbations, allowing vein classifiers to achieve the highest recognition accuracy.
Neural Architecture Search based Global-local Vision Mamba for Palm-Vein Recognition
Aug 13, 2024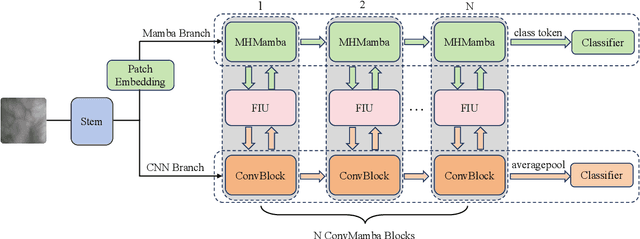
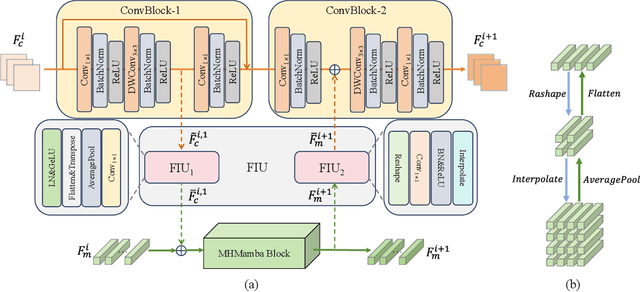
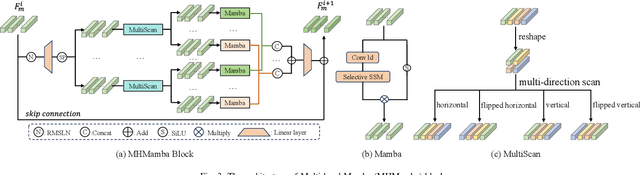
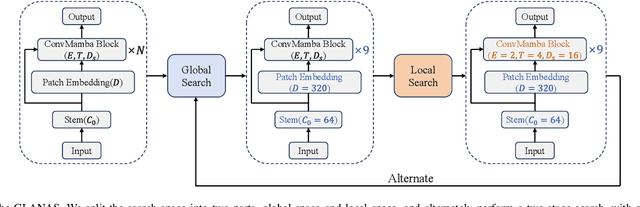
Due to the advantages such as high security, high privacy, and liveness recognition, vein recognition has been received more and more attention in past years. Recently, deep learning models, e.g., Mamba has shown robust feature representation with linear computational complexity and successfully applied for visual tasks. However, vision Manba can capture long-distance feature dependencies but unfortunately deteriorate local feature details. Besides, manually designing a Mamba architecture based on human priori knowledge is very time-consuming and error-prone. In this paper, first, we propose a hybrid network structure named Global-local Vision Mamba (GLVM), to learn the local correlations in images explicitly and global dependencies among tokens for vein feature representation. Secondly, we design a Multi-head Mamba to learn the dependencies along different directions, so as to improve the feature representation ability of vision Mamba. Thirdly, to learn the complementary features, we propose a ConvMamba block consisting of three branches, named Multi-head Mamba branch (MHMamba), Feature Iteration Unit branch (FIU), and Convolutional Neural Network (CNN) branch, where the Feature Iteration Unit branch aims to fuse convolutional local features with Mamba-based global representations. Finally, a Globallocal Alternate Neural Architecture Search (GLNAS) method is proposed to search the optimal architecture of GLVM alternately with the evolutionary algorithm, thereby improving the recognition performance for vein recognition tasks. We conduct rigorous experiments on three public palm-vein databases to estimate the performance. The experimental results demonstrate that the proposed method outperforms the representative approaches and achieves state-of-the-art recognition accuracy.
SUMix: Mixup with Semantic and Uncertain Information
Jul 10, 2024
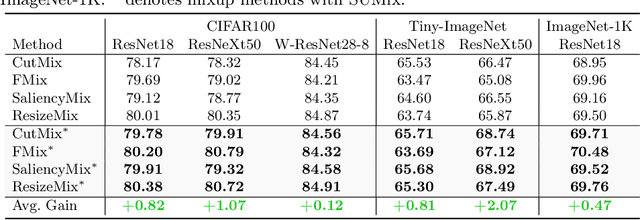
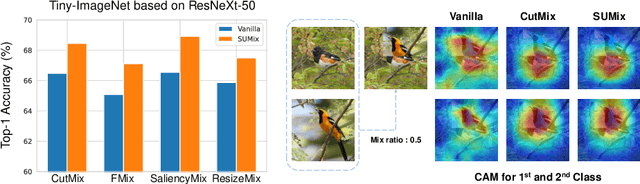
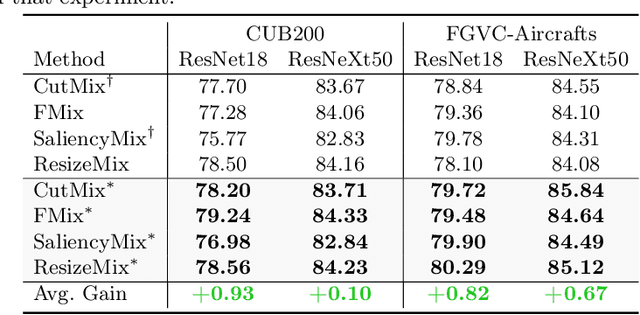
Mixup data augmentation approaches have been applied for various tasks of deep learning to improve the generalization ability of deep neural networks. Some existing approaches CutMix, SaliencyMix, etc. randomly replace a patch in one image with patches from another to generate the mixed image. Similarly, the corresponding labels are linearly combined by a fixed ratio $\lambda$ by l. The objects in two images may be overlapped during the mixing process, so some semantic information is corrupted in the mixed samples. In this case, the mixed image does not match the mixed label information. Besides, such a label may mislead the deep learning model training, which results in poor performance. To solve this problem, we proposed a novel approach named SUMix to learn the mixing ratio as well as the uncertainty for the mixed samples during the training process. First, we design a learnable similarity function to compute an accurate mix ratio. Second, an approach is investigated as a regularized term to model the uncertainty of the mixed samples. We conduct experiments on five image benchmarks, and extensive experimental results imply that our method is capable of improving the performance of classifiers with different cutting-based mixup approaches. The source code is available at https://github.com/JinXins/SUMix.