 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMsMemoryGAN: A Multi-scale Memory GAN for Palm-vein Adversarial Purification
Aug 20, 2024

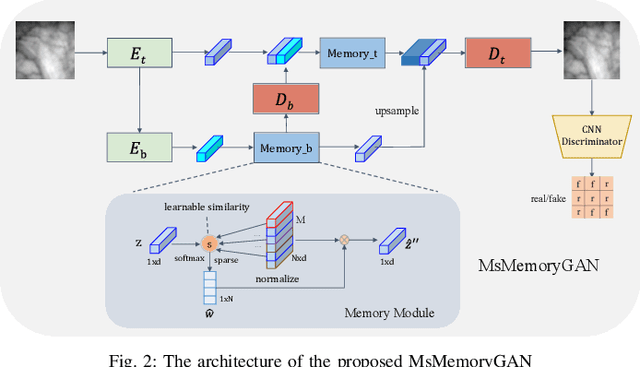
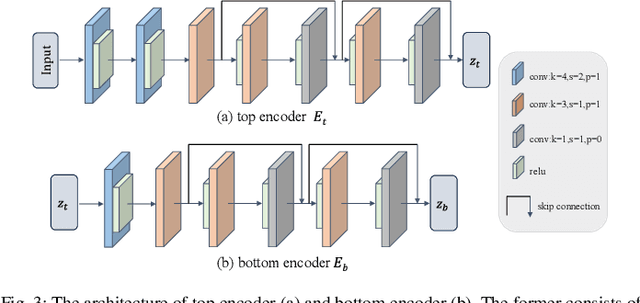
Deep neural networks have recently achieved promising performance in the vein recognition task and have shown an increasing application trend, however, they are prone to adversarial perturbation attacks by adding imperceptible perturbations to the input, resulting in making incorrect recognition. To address this issue, we propose a novel defense model named MsMemoryGAN, which aims to filter the perturbations from adversarial samples before recognition. First, we design a multi-scale autoencoder to achieve high-quality reconstruction and two memory modules to learn the detailed patterns of normal samples at different scales. Second, we investigate a learnable metric in the memory module to retrieve the most relevant memory items to reconstruct the input image. Finally, the perceptional loss is combined with the pixel loss to further enhance the quality of the reconstructed image. During the training phase, the MsMemoryGAN learns to reconstruct the input by merely using fewer prototypical elements of the normal patterns recorded in the memory. At the testing stage, given an adversarial sample, the MsMemoryGAN retrieves its most relevant normal patterns in memory for the reconstruction. Perturbations in the adversarial sample are usually not reconstructed well, resulting in purifying the input from adversarial perturbations. We have conducted extensive experiments on two public vein datasets under different adversarial attack methods to evaluate the performance of the proposed approach. The experimental results show that our approach removes a wide variety of adversarial perturbations, allowing vein classifiers to achieve the highest recognition accuracy.
Neural Architecture Search based Global-local Vision Mamba for Palm-Vein Recognition
Aug 13, 2024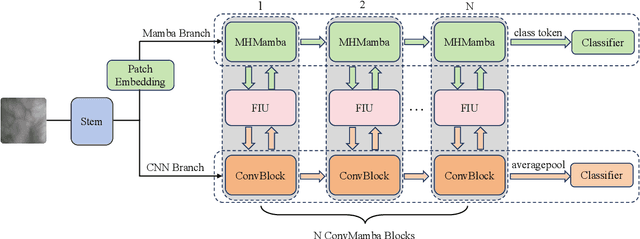
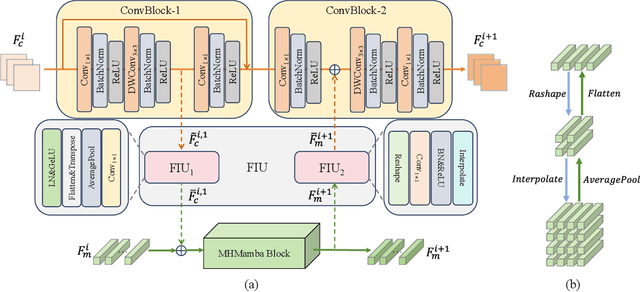
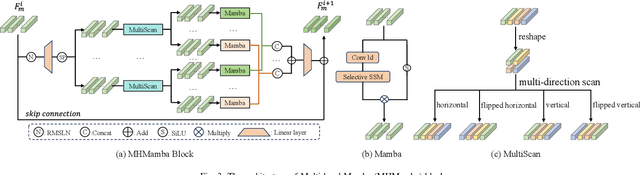
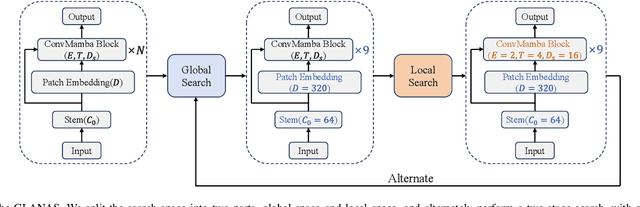
Due to the advantages such as high security, high privacy, and liveness recognition, vein recognition has been received more and more attention in past years. Recently, deep learning models, e.g., Mamba has shown robust feature representation with linear computational complexity and successfully applied for visual tasks. However, vision Manba can capture long-distance feature dependencies but unfortunately deteriorate local feature details. Besides, manually designing a Mamba architecture based on human priori knowledge is very time-consuming and error-prone. In this paper, first, we propose a hybrid network structure named Global-local Vision Mamba (GLVM), to learn the local correlations in images explicitly and global dependencies among tokens for vein feature representation. Secondly, we design a Multi-head Mamba to learn the dependencies along different directions, so as to improve the feature representation ability of vision Mamba. Thirdly, to learn the complementary features, we propose a ConvMamba block consisting of three branches, named Multi-head Mamba branch (MHMamba), Feature Iteration Unit branch (FIU), and Convolutional Neural Network (CNN) branch, where the Feature Iteration Unit branch aims to fuse convolutional local features with Mamba-based global representations. Finally, a Globallocal Alternate Neural Architecture Search (GLNAS) method is proposed to search the optimal architecture of GLVM alternately with the evolutionary algorithm, thereby improving the recognition performance for vein recognition tasks. We conduct rigorous experiments on three public palm-vein databases to estimate the performance. The experimental results demonstrate that the proposed method outperforms the representative approaches and achieves state-of-the-art recognition accuracy.